 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Models Decide and When They Bind: A Two-Stage Computation for Multiple-Choice Question-Answering
Jan 07, 2026Multiple-choice question answering (MCQA) is easy to evaluate but adds a meta-task: models must both solve the problem and output the symbol that *represents* the answer, conflating reasoning errors with symbol-binding failures. We study how language models implement MCQA internally using representational analyses (PCA, linear probes) as well as causal interventions. We find that option-boundary (newline) residual states often contain strong linearly decodable signals related to per-option correctness. Winner-identity probing reveals a two-stage progression: the winning *content position* becomes decodable immediately after the final option is processed, while the *output symbol* is represented closer to the answer emission position. Tests under symbol and content permutations support a two-stage mechanism in which models first select a winner in content space and then bind or route that winner to the appropriate symbol to emit.
Grounded Misunderstandings in Asymmetric Dialogue: A Perspectivist Annotation Scheme for MapTask
Nov 05, 2025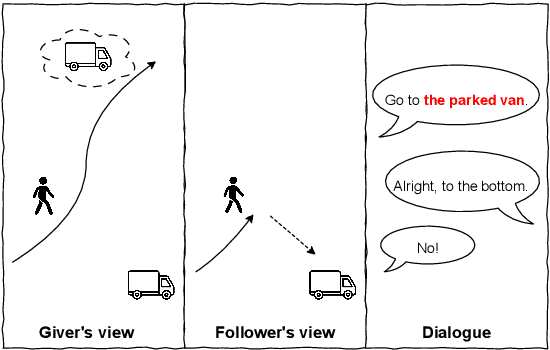
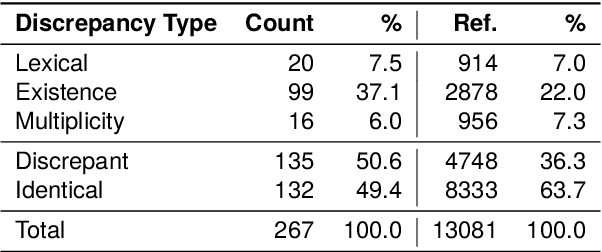

Collaborative dialogue relies on participants incrementally establishing common ground, yet in asymmetric settings they may believe they agree while referring to different entities. We introduce a perspectivist annotation scheme for the HCRC MapTask corpus (Anderson et al., 1991) that separately captures speaker and addressee grounded interpretations for each reference expression, enabling us to trace how understanding emerges, diverges, and repairs over time. Using a scheme-constrained LLM annotation pipeline, we obtain 13k annotated reference expressions with reliability estimates and analyze the resulting understanding states. The results show that full misunderstandings are rare once lexical variants are unified, but multiplicity discrepancies systematically induce divergences, revealing how apparent grounding can mask referential misalignment. Our framework provides both a resource and an analytic lens for studying grounded misunderstanding and for evaluating (V)LLMs' capacity to model perspective-dependent grounding in collaborative dialogue.
Evaluation Should Not Ignore Variation: On the Impact of Reference Set Choice on Summarization Metrics
Jun 17, 2025Human language production exhibits remarkable richness and variation, reflecting diverse communication styles and intents. However, this variation is often overlooked in summarization evaluation. While having multiple reference summaries is known to improve correlation with human judgments, the impact of using different reference sets on reference-based metrics has not been systematically investigated. This work examines the sensitivity of widely used reference-based metrics in relation to the choice of reference sets, analyzing three diverse multi-reference summarization datasets: SummEval, GUMSum, and DUC2004. We demonstrate that many popular metrics exhibit significant instability. This instability is particularly concerning for n-gram-based metrics like ROUGE, where model rankings vary depending on the reference sets, undermining the reliability of model comparisons. We also collect human judgments on LLM outputs for genre-diverse data and examine their correlation with metrics to supplement existing findings beyond newswire summaries, finding weak-to-no correlation. Taken together, we recommend incorporating reference set variation into summarization evaluation to enhance consistency alongside correlation with human judgments, especially when evaluating LLMs.
Burn After Reading: Do Multimodal Large Language Models Truly Capture Order of Events in Image Sequences?
Jun 12, 2025This paper introduces the TempVS benchmark, which focuses on temporal grounding and reasoning capabilities of Multimodal Large Language Models (MLLMs) in image sequences. TempVS consists of three main tests (i.e., event relation inference, sentence ordering and image ordering), each accompanied with a basic grounding test. TempVS requires MLLMs to rely on both visual and linguistic modalities to understand the temporal order of events. We evaluate 38 state-of-the-art MLLMs, demonstrating that models struggle to solve TempVS, with a substantial performance gap compared to human capabilities. We also provide fine-grained insights that suggest promising directions for future research. Our TempVS benchmark data and code are available at https://github.com/yjsong22/TempVS.
VAQUUM: Are Vague Quantifiers Grounded in Visual Data?
Feb 18, 2025



Vague quantifiers such as "a few" and "many" are influenced by many contextual factors, including how many objects are present in a given context. In this work, we evaluate the extent to which vision-and-language models (VLMs) are compatible with humans when producing or judging the appropriateness of vague quantifiers in visual contexts. We release a novel dataset, VAQUUM, containing 20300 human ratings on quantified statements across a total of 1089 images. Using this dataset, we compare human judgments and VLM predictions using three different evaluation methods. Our findings show that VLMs, like humans, are influenced by object counts in vague quantifier use. However, we find significant inconsistencies across models in different evaluation settings, suggesting that judging and producing vague quantifiers rely on two different processes.
Probing Omissions and Distortions in Transformer-based RDF-to-Text Models
Sep 25, 2024
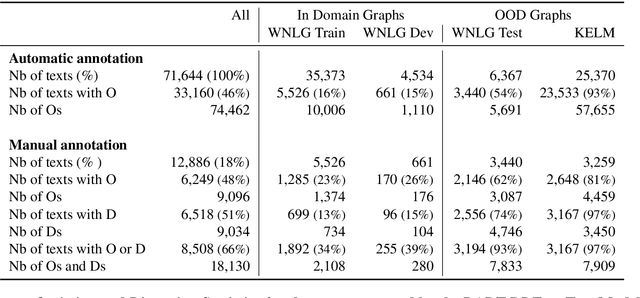
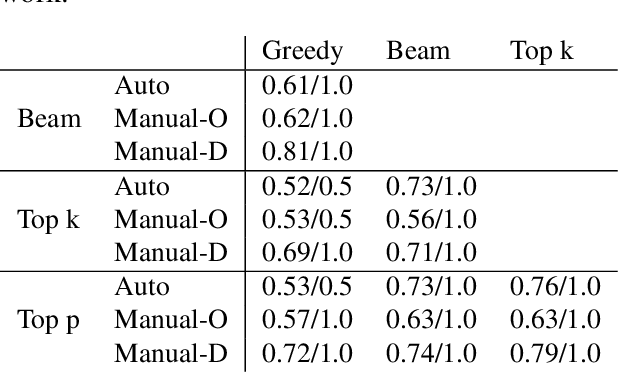
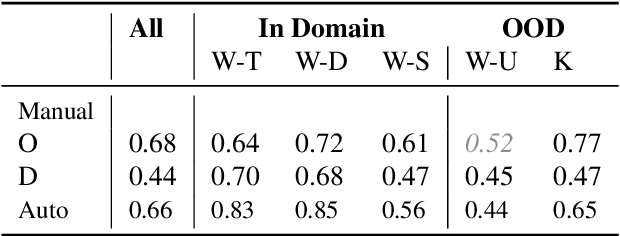
In Natural Language Generation (NLG), important information is sometimes omitted in the output text. To better understand and analyse how this type of mistake arises, we focus on RDF-to-Text generation and explore two methods of probing omissions in the encoder output of BART (Lewis et al, 2020) and of T5 (Raffel et al, 2019): (i) a novel parameter-free probing method based on the computation of cosine similarity between embeddings of RDF graphs and of RDF graphs in which we removed some entities and (ii) a parametric probe which performs binary classification on the encoder embeddings to detect omitted entities. We also extend our analysis to distorted entities, i.e. entities that are not fully correctly mentioned in the generated text (e.g. misspelling of entity, wrong units of measurement). We found that both omitted and distorted entities can be probed in the encoder's output embeddings. This suggests that the encoder emits a weaker signal for these entities and therefore is responsible for some loss of information. This also shows that probing methods can be used to detect mistakes in the output of NLG models.
CV-Probes: Studying the interplay of lexical and world knowledge in visually grounded verb understanding
Sep 02, 2024This study investigates the ability of various vision-language (VL) models to ground context-dependent and non-context-dependent verb phrases. To do that, we introduce the CV-Probes dataset, designed explicitly for studying context understanding, containing image-caption pairs with context-dependent verbs (e.g., "beg") and non-context-dependent verbs (e.g., "sit"). We employ the MM-SHAP evaluation to assess the contribution of verb tokens towards model predictions. Our results indicate that VL models struggle to ground context-dependent verb phrases effectively. These findings highlight the challenges in training VL models to integrate context accurately, suggesting a need for improved methodologies in VL model training and evaluation.
Summarizing long regulatory documents with a multi-step pipeline
Aug 19, 2024Due to their length and complexity, long regulatory texts are challenging to summarize. To address this, a multi-step extractive-abstractive architecture is proposed to handle lengthy regulatory documents more effectively. In this paper, we show that the effectiveness of a two-step architecture for summarizing long regulatory texts varies significantly depending on the model used. Specifically, the two-step architecture improves the performance of decoder-only models. For abstractive encoder-decoder models with short context lengths, the effectiveness of an extractive step varies, whereas for long-context encoder-decoder models, the extractive step worsens their performance. This research also highlights the challenges of evaluating generated texts, as evidenced by the differing results from human and automated evaluations. Most notably, human evaluations favoured language models pretrained on legal text, while automated metrics rank general-purpose language models higher. The results underscore the importance of selecting the appropriate summarization strategy based on model architecture and context length.
Automatic Metrics in Natural Language Generation: A Survey of Current Evaluation Practices
Aug 17, 2024
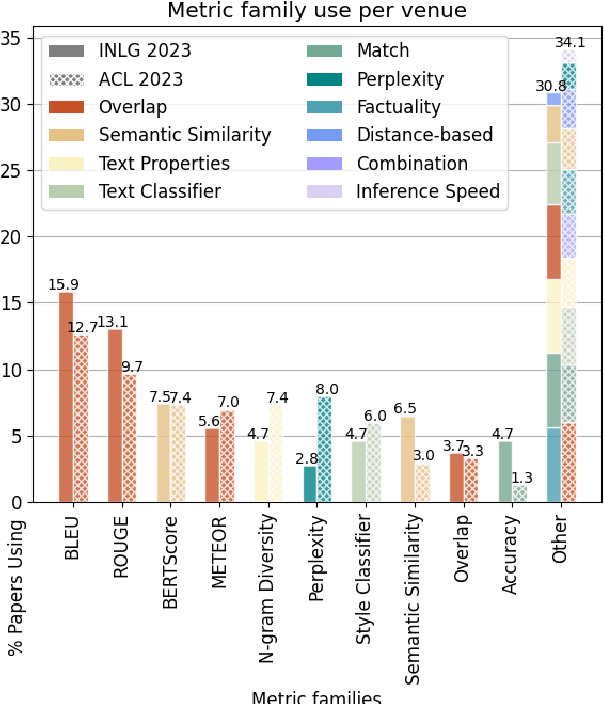
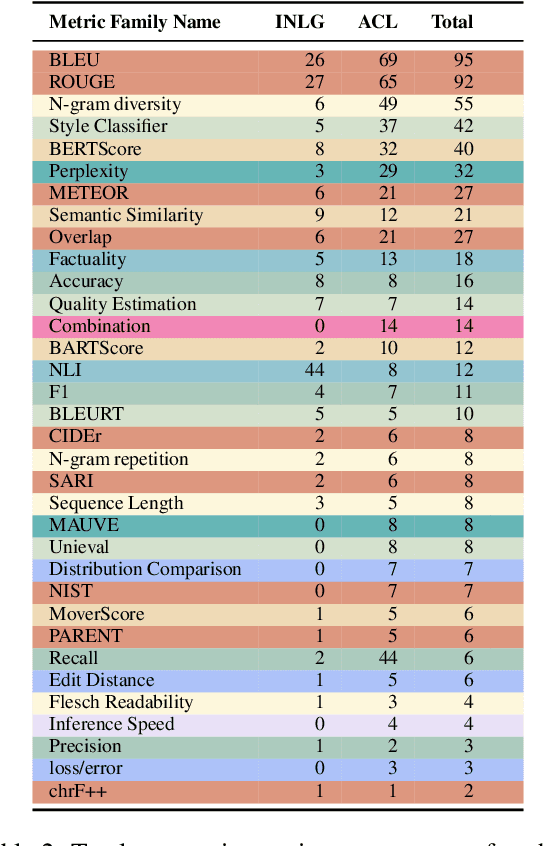
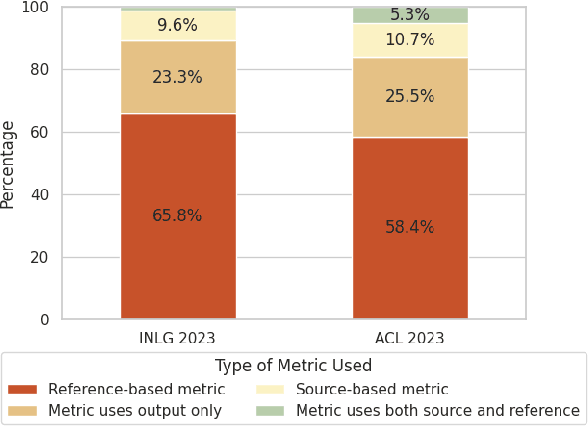
Automatic metrics are extensively used to evaluate natural language processing systems. However, there has been increasing focus on how they are used and reported by practitioners within the field. In this paper, we have conducted a survey on the use of automatic metrics, focusing particularly on natural language generation (NLG) tasks. We inspect which metrics are used as well as why they are chosen and how their use is reported. Our findings from this survey reveal significant shortcomings, including inappropriate metric usage, lack of implementation details and missing correlations with human judgements. We conclude with recommendations that we believe authors should follow to enable more rigour within the field.
Context-aware Visual Storytelling with Visual Prefix Tuning and Contrastive Learning
Aug 12, 2024



Visual storytelling systems generate multi-sentence stories from image sequences. In this task, capturing contextual information and bridging visual variation bring additional challenges. We propose a simple yet effective framework that leverages the generalization capabilities of pretrained foundation models, only training a lightweight vision-language mapping network to connect modalities, while incorporating context to enhance coherence. We introduce a multimodal contrastive objective that also improves visual relevance and story informativeness. Extensive experimental results, across both automatic metrics and human evaluations, demonstrate that the stories generated by our framework are diverse, coherent, informative, and interesting.