 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInformation Asymmetry across Language Varieties: A Case Study on Cantonese-Mandarin and Bavarian-German QA
Mar 16, 2026Large Language Models (LLMs) are becoming a common way for humans to seek knowledge, yet their coverage and reliability vary widely. Especially for local language varieties, there are large asymmetries, e.g., information in local Wikipedia that is absent from the standard variant. However, little is known about how well LLMs perform under such information asymmetry, especially on closely related languages. We manually construct a novel challenge question-answering (QA) dataset that captures knowledge conveyed on a local Wikipedia page, which is absent from their higher-resource counterparts-covering Mandarin Chinese vs. Cantonese and German vs. Bavarian. Our experiments show that LLMs fail to answer questions about information only in local editions of Wikipedia. Providing context from lead sections substantially improves performance, with further gains possible via translation. Our topical, geographic annotations, and stratified evaluations reveal the usefulness of local Wikipedia editions as sources of both regional and global information. These findings raise critical questions about inclusivity and cultural coverage of LLMs.
EVADE: LLM-Based Explanation Generation and Validation for Error Detection in NLI
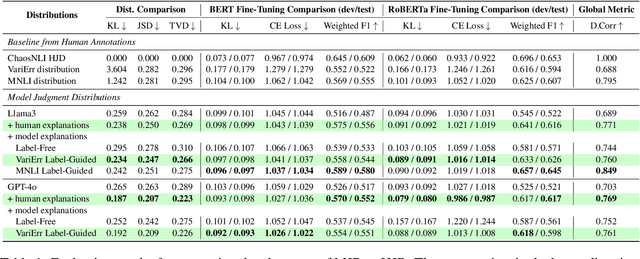
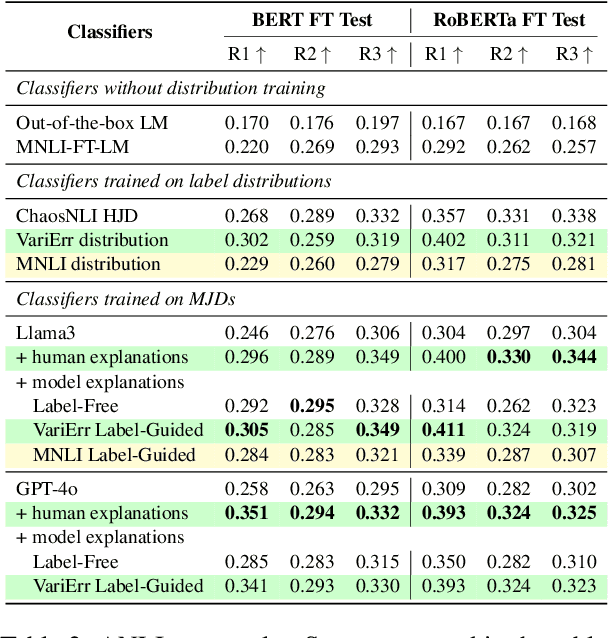
Nov 12, 2025High-quality datasets are critical for training and evaluating reliable NLP models. In tasks like natural language inference (NLI), human label variation (HLV) arises when multiple labels are valid for the same instance, making it difficult to separate annotation errors from plausible variation. An earlier framework VARIERR (Weber-Genzel et al., 2024) asks multiple annotators to explain their label decisions in the first round and flag errors via validity judgments in the second round. However, conducting two rounds of manual annotation is costly and may limit the coverage of plausible labels or explanations. Our study proposes a new framework, EVADE, for generating and validating explanations to detect errors using large language models (LLMs). We perform a comprehensive analysis comparing human- and LLM-detected errors for NLI across distribution comparison, validation overlap, and impact on model fine-tuning. Our experiments demonstrate that LLM validation refines generated explanation distributions to more closely align with human annotations, and that removing LLM-detected errors from training data yields improvements in fine-tuning performance than removing errors identified by human annotators. This highlights the potential to scale error detection, reducing human effort while improving dataset quality under label variation.
BoN Appetit Team at LeWiDi-2025: Best-of-N Test-time Scaling Can Not Stomach Annotation Disagreements (Yet)
Oct 14, 2025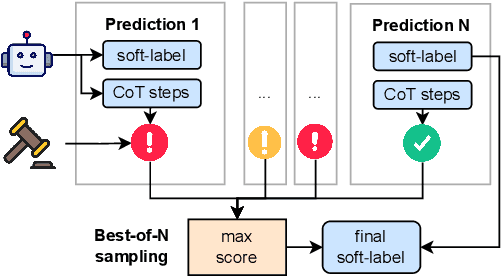


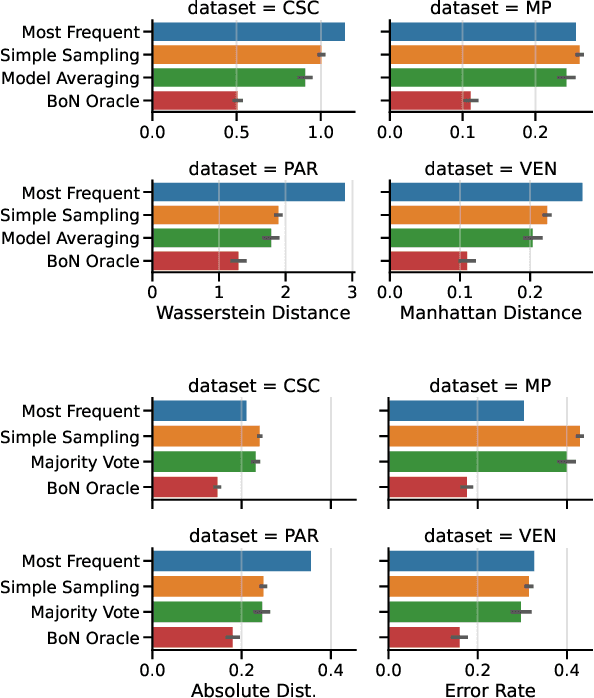
Test-time scaling is a family of techniques to improve LLM outputs at inference time by performing extra computation. To the best of our knowledge, test-time scaling has been limited to domains with verifiably correct answers, like mathematics and coding. We transfer test-time scaling to the LeWiDi-2025 tasks to evaluate annotation disagreements. We experiment with three test-time scaling methods: two benchmark algorithms (Model Averaging and Majority Voting), and a Best-of-N sampling method. The two benchmark methods improve LLM performance consistently on the LeWiDi tasks, but the Best-of-N method does not. Our experiments suggest that the Best-of-N method does not currently transfer from mathematics to LeWiDi tasks, and we analyze potential reasons for this gap.
Evaluation Should Not Ignore Variation: On the Impact of Reference Set Choice on Summarization Metrics
Jun 17, 2025Human language production exhibits remarkable richness and variation, reflecting diverse communication styles and intents. However, this variation is often overlooked in summarization evaluation. While having multiple reference summaries is known to improve correlation with human judgments, the impact of using different reference sets on reference-based metrics has not been systematically investigated. This work examines the sensitivity of widely used reference-based metrics in relation to the choice of reference sets, analyzing three diverse multi-reference summarization datasets: SummEval, GUMSum, and DUC2004. We demonstrate that many popular metrics exhibit significant instability. This instability is particularly concerning for n-gram-based metrics like ROUGE, where model rankings vary depending on the reference sets, undermining the reliability of model comparisons. We also collect human judgments on LLM outputs for genre-diverse data and examine their correlation with metrics to supplement existing findings beyond newswire summaries, finding weak-to-no correlation. Taken together, we recommend incorporating reference set variation into summarization evaluation to enhance consistency alongside correlation with human judgments, especially when evaluating LLMs.
LiTEx: A Linguistic Taxonomy of Explanations for Understanding Within-Label Variation in Natural Language Inference
May 28, 2025



There is increasing evidence of Human Label Variation (HLV) in Natural Language Inference (NLI), where annotators assign different labels to the same premise-hypothesis pair. However, within-label variation--cases where annotators agree on the same label but provide divergent reasoning--poses an additional and mostly overlooked challenge. Several NLI datasets contain highlighted words in the NLI item as explanations, but the same spans on the NLI item can be highlighted for different reasons, as evidenced by free-text explanations, which offer a window into annotators' reasoning. To systematically understand this problem and gain insight into the rationales behind NLI labels, we introduce LITEX, a linguistically-informed taxonomy for categorizing free-text explanations. Using this taxonomy, we annotate a subset of the e-SNLI dataset, validate the taxonomy's reliability, and analyze how it aligns with NLI labels, highlights, and explanations. We further assess the taxonomy's usefulness in explanation generation, demonstrating that conditioning generation on LITEX yields explanations that are linguistically closer to human explanations than those generated using only labels or highlights. Our approach thus not only captures within-label variation but also shows how taxonomy-guided generation for reasoning can bridge the gap between human and model explanations more effectively than existing strategies.
What Media Frames Reveal About Stance: A Dataset and Study about Memes in Climate Change Discourse
May 22, 2025Media framing refers to the emphasis on specific aspects of perceived reality to shape how an issue is defined and understood. Its primary purpose is to shape public perceptions often in alignment with the authors' opinions and stances. However, the interaction between stance and media frame remains largely unexplored. In this work, we apply an interdisciplinary approach to conceptualize and computationally explore this interaction with internet memes on climate change. We curate CLIMATEMEMES, the first dataset of climate-change memes annotated with both stance and media frames, inspired by research in communication science. CLIMATEMEMES includes 1,184 memes sourced from 47 subreddits, enabling analysis of frame prominence over time and communities, and sheds light on the framing preferences of different stance holders. We propose two meme understanding tasks: stance detection and media frame detection. We evaluate LLaVA-NeXT and Molmo in various setups, and report the corresponding results on their LLM backbone. Human captions consistently enhance performance. Synthetic captions and human-corrected OCR also help occasionally. Our findings highlight that VLMs perform well on stance, but struggle on frames, where LLMs outperform VLMs. Finally, we analyze VLMs' limitations in handling nuanced frames and stance expressions on climate change internet memes.
A Rose by Any Other Name: LLM-Generated Explanations Are Good Proxies for Human Explanations to Collect Label Distributions on NLI
Dec 18, 2024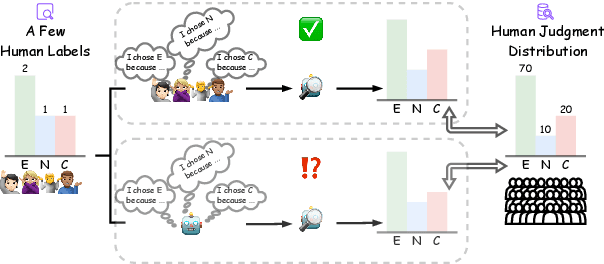
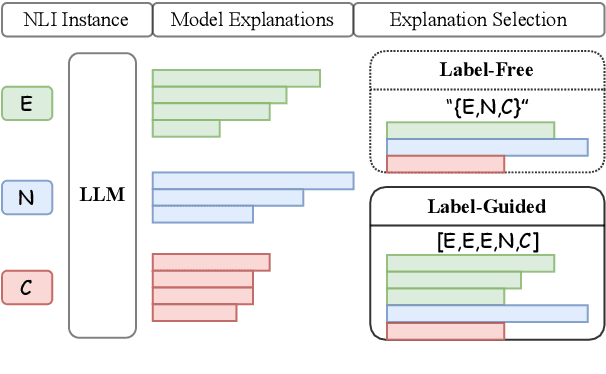
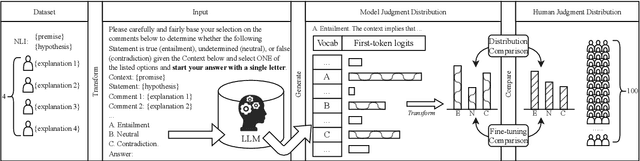
Disagreement in human labeling is ubiquitous, and can be captured in human judgment distributions (HJDs). Recent research has shown that explanations provide valuable information for understanding human label variation (HLV) and large language models (LLMs) can approximate HJD from a few human-provided label-explanation pairs. However, collecting explanations for every label is still time-consuming. This paper examines whether LLMs can be used to replace humans in generating explanations for approximating HJD. Specifically, we use LLMs as annotators to generate model explanations for a few given human labels. We test ways to obtain and combine these label-explanations with the goal to approximate human judgment distribution. We further compare the resulting human with model-generated explanations, and test automatic and human explanation selection. Our experiments show that LLM explanations are promising for NLI: to estimate HJD, generated explanations yield comparable results to human's when provided with human labels. Importantly, our results generalize from datasets with human explanations to i) datasets where they are not available and ii) challenging out-of-distribution test sets.
MultiClimate: Multimodal Stance Detection on Climate Change Videos
Sep 26, 2024Climate change (CC) has attracted increasing attention in NLP in recent years. However, detecting the stance on CC in multimodal data is understudied and remains challenging due to a lack of reliable datasets. To improve the understanding of public opinions and communication strategies, this paper presents MultiClimate, the first open-source manually-annotated stance detection dataset with $100$ CC-related YouTube videos and $4,209$ frame-transcript pairs. We deploy state-of-the-art vision and language models, as well as multimodal models for MultiClimate stance detection. Results show that text-only BERT significantly outperforms image-only ResNet50 and ViT. Combining both modalities achieves state-of-the-art, $0.747$/$0.749$ in accuracy/F1. Our 100M-sized fusion models also beat CLIP and BLIP, as well as the much larger 9B-sized multimodal IDEFICS and text-only Llama3 and Gemma2, indicating that multimodal stance detection remains challenging for large language models. Our code, dataset, as well as supplementary materials, are available at https://github.com/werywjw/MultiClimate.
"Seeing the Big through the Small": Can LLMs Approximate Human Judgment Distributions on NLI from a Few Explanations?
Jun 25, 2024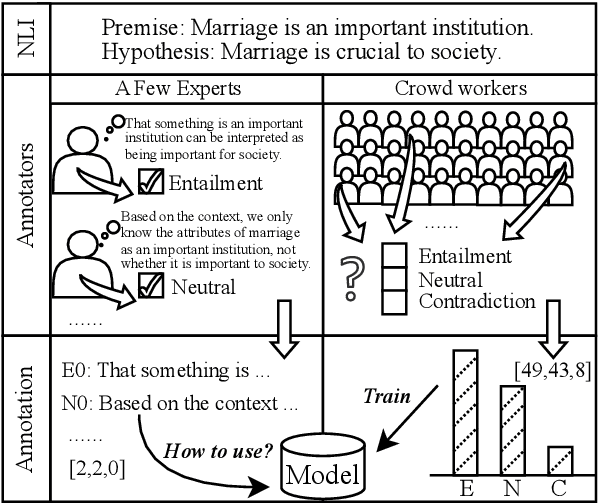

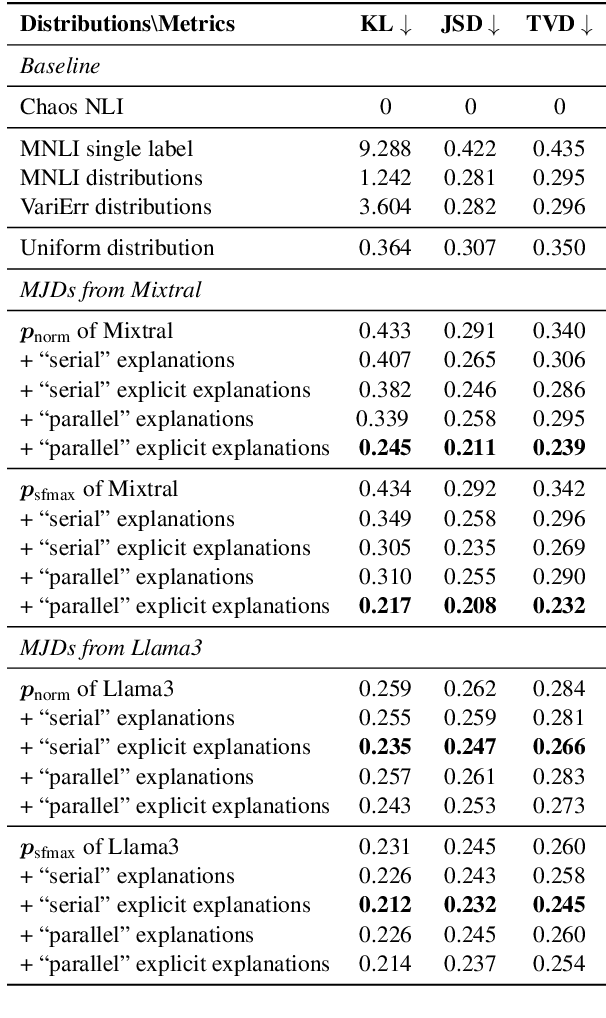
Human label variation (HLV) is a valuable source of information that arises when multiple human annotators provide different labels for valid reasons. In Natural Language Inference (NLI) earlier approaches to capturing HLV involve either collecting annotations from many crowd workers to represent human judgment distribution (HJD) or use expert linguists to provide detailed explanations for their chosen labels. While the former method provides denser HJD information, obtaining it is resource-intensive. In contrast, the latter offers richer textual information but it is challenging to scale up to many human judges. Besides, large language models (LLMs) are increasingly used as evaluators (``LLM judges'') but with mixed results, and few works aim to study HJDs. This study proposes to exploit LLMs to approximate HJDs using a small number of expert labels and explanations. Our experiments show that a few explanations significantly improve LLMs' ability to approximate HJDs with and without explicit labels, thereby providing a solution to scale up annotations for HJD. However, fine-tuning smaller soft-label aware models with the LLM-generated model judgment distributions (MJDs) presents partially inconsistent results: while similar in distance, their resulting fine-tuned models and visualized distributions differ substantially. We show the importance of complementing instance-level distance measures with a global-level shape metric and visualization to more effectively evaluate MJDs against human judgment distributions.
CLIMATELI: Evaluating Entity Linking on Climate Change Data
Jun 24, 2024



Climate Change (CC) is a pressing topic of global importance, attracting increasing attention across research fields, from social sciences to Natural Language Processing (NLP). CC is also discussed in various settings and communication platforms, from academic publications to social media forums. Understanding who and what is mentioned in such data is a first critical step to gaining new insights into CC. We present CLIMATELI (CLIMATe Entity LInking), the first manually annotated CC dataset that links 3,087 entity spans to Wikipedia. Using CLIMATELI (CLIMATe Entity LInking), we evaluate existing entity linking (EL) systems on the CC topic across various genres and propose automated filtering methods for CC entities. We find that the performance of EL models notably lags behind humans at both token and entity levels. Testing within the scope of retaining or excluding non-nominal and/or non-CC entities particularly impacts the models' performances.