 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSPLICE: A Singleton-Enhanced PipeLIne for Coreference REsolution
Mar 25, 2024



Singleton mentions, i.e.~entities mentioned only once in a text, are important to how humans understand discourse from a theoretical perspective. However previous attempts to incorporate their detection in end-to-end neural coreference resolution for English have been hampered by the lack of singleton mention spans in the OntoNotes benchmark. This paper addresses this limitation by combining predicted mentions from existing nested NER systems and features derived from OntoNotes syntax trees. With this approach, we create a near approximation of the OntoNotes dataset with all singleton mentions, achieving ~94% recall on a sample of gold singletons. We then propose a two-step neural mention and coreference resolution system, named SPLICE, and compare its performance to the end-to-end approach in two scenarios: the OntoNotes test set and the out-of-domain (OOD) OntoGUM corpus. Results indicate that reconstructed singleton training yields results comparable to end-to-end systems for OntoNotes, while improving OOD stability (+1.1 avg. F1). We conduct error analysis for mention detection and delve into its impact on coreference clustering, revealing that precision improvements deliver more substantial benefits than increases in recall for resolving coreference chains.
Incorporating Singletons and Mention-based Features in Coreference Resolution via Multi-task Learning for Better Generalization
Sep 20, 2023



Previous attempts to incorporate a mention detection step into end-to-end neural coreference resolution for English have been hampered by the lack of singleton mention span data as well as other entity information. This paper presents a coreference model that learns singletons as well as features such as entity type and information status via a multi-task learning-based approach. This approach achieves new state-of-the-art scores on the OntoGUM benchmark (+2.7 points) and increases robustness on multiple out-of-domain datasets (+2.3 points on average), likely due to greater generalizability for mention detection and utilization of more data from singletons when compared to only coreferent mention pair matching.
Anatomy of OntoGUM--Adapting GUM to the OntoNotes Scheme to Evaluate Robustness of SOTA Coreference Algorithms
Oct 12, 2021



SOTA coreference resolution produces increasingly impressive scores on the OntoNotes benchmark. However lack of comparable data following the same scheme for more genres makes it difficult to evaluate generalizability to open domain data. Zhu et al. (2021) introduced the creation of the OntoGUM corpus for evaluating geralizability of the latest neural LM-based end-to-end systems. This paper covers details of the mapping process which is a set of deterministic rules applied to the rich syntactic and discourse annotations manually annotated in the GUM corpus. Out-of-domain evaluation across 12 genres shows nearly 15-20% degradation for both deterministic and deep learning systems, indicating a lack of generalizability or covert overfitting in existing coreference resolution models.
OntoGUM: Evaluating Contextualized SOTA Coreference Resolution on 12 More Genres
Jun 03, 2021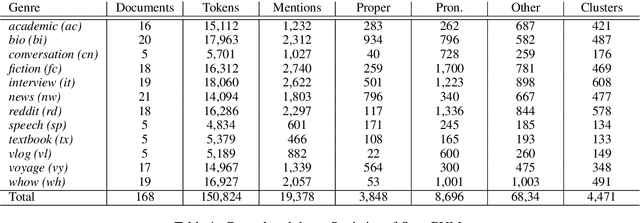
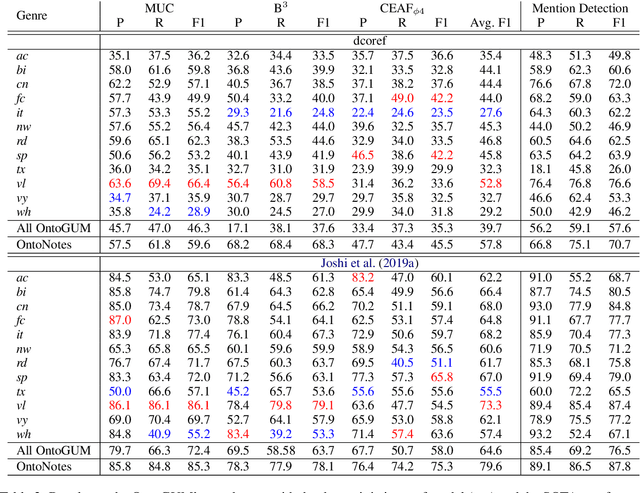
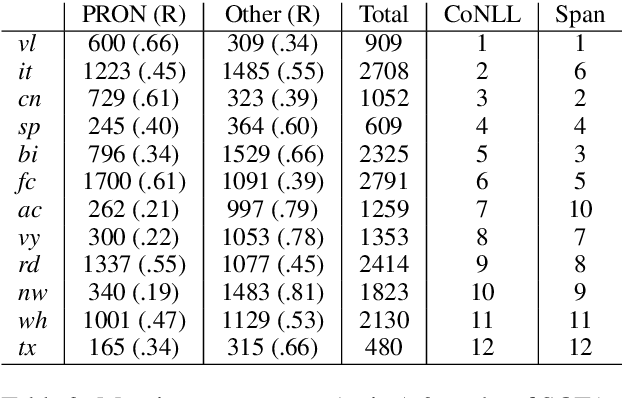
SOTA coreference resolution produces increasingly impressive scores on the OntoNotes benchmark. However lack of comparable data following the same scheme for more genres makes it difficult to evaluate generalizability to open domain data. This paper provides a dataset and comprehensive evaluation showing that the latest neural LM based end-to-end systems degrade very substantially out of domain. We make an OntoNotes-like coreference dataset called OntoGUM publicly available, converted from GUM, an English corpus covering 12 genres, using deterministic rules, which we evaluate. Thanks to the rich syntactic and discourse annotations in GUM, we are able to create the largest human-annotated coreference corpus following the OntoNotes guidelines, and the first to be evaluated for consistency with the OntoNotes scheme. Out-of-domain evaluation across 12 genres shows nearly 15-20% degradation for both deterministic and deep learning systems, indicating a lack of generalizability or covert overfitting in existing coreference resolution models.