 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnpacking Ambiguity: The Interaction of Polysemous Discourse Markers and Non-DM Signals
Jul 22, 2025Discourse markers (DMs) like 'but' or 'then' are crucial for creating coherence in discourse, yet they are often replaced by or co-occur with non-DMs ('in the morning' can mean the same as 'then'), and both can be ambiguous ('since' can refer to time or cause). The interaction mechanism between such signals remains unclear but pivotal for their disambiguation. In this paper we investigate the relationship between DM polysemy and co-occurrence of non-DM signals in English, as well as the influence of genre on these patterns. Using the framework of eRST, we propose a graded definition of DM polysemy, and conduct correlation and regression analyses to examine whether polysemous DMs are accompanied by more numerous and diverse non-DM signals. Our findings reveal that while polysemous DMs do co-occur with more diverse non-DMs, the total number of co-occurring signals does not necessarily increase. Moreover, genre plays a significant role in shaping DM-signal interactions.
Subjectivity in the Annotation of Bridging Anaphora
Jun 08, 2025Bridging refers to the associative relationship between inferable entities in a discourse and the antecedents which allow us to understand them, such as understanding what "the door" means with respect to an aforementioned "house". As identifying associative relations between entities is an inherently subjective task, it is difficult to achieve consistent agreement in the annotation of bridging anaphora and their antecedents. In this paper, we explore the subjectivity involved in the annotation of bridging instances at three levels: anaphor recognition, antecedent resolution, and bridging subtype selection. To do this, we conduct an annotation pilot on the test set of the existing GUM corpus, and propose a newly developed classification system for bridging subtypes, which we compare to previously proposed schemes. Our results suggest that some previous resources are likely to be severely under-annotated. We also find that while agreement on the bridging subtype category was moderate, annotator overlap for exhaustively identifying instances of bridging is low, and that many disagreements resulted from subjective understanding of the entities involved.
A UD Treebank for Bohairic Coptic
Apr 25, 2025Despite recent advances in digital resources for other Coptic dialects, especially Sahidic, Bohairic Coptic, the main Coptic dialect for pre-Mamluk, late Byzantine Egypt, and the contemporary language of the Coptic Church, remains critically under-resourced. This paper presents and evaluates the first syntactically annotated corpus of Bohairic Coptic, sampling data from a range of works, including Biblical text, saints' lives and Christian ascetic writing. We also explore some of the main differences we observe compared to the existing UD treebank of Sahidic Coptic, the classical dialect of the language, and conduct joint and cross-dialect parsing experiments, revealing the unique nature of Bohairic as a related, but distinct variety from the more often studied Sahidic.
Building UD Cairo for Old English in the Classroom
Apr 25, 2025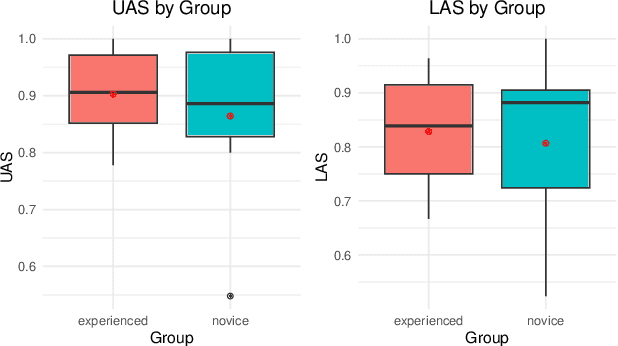
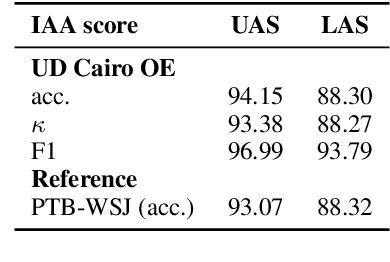
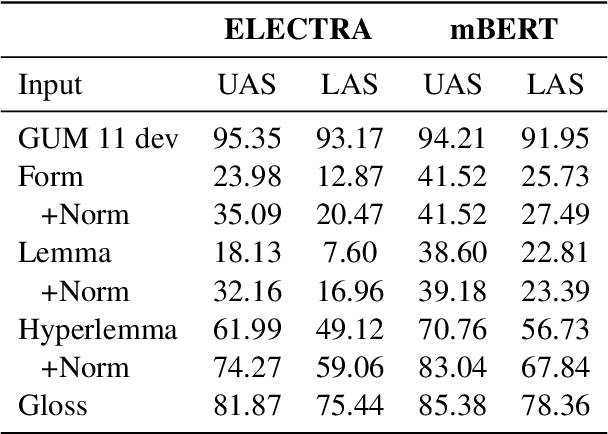
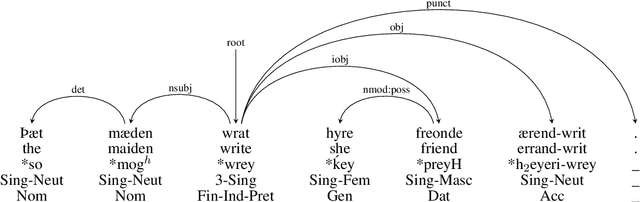
In this paper we present a sample treebank for Old English based on the UD Cairo sentences, collected and annotated as part of a classroom curriculum in Historical Linguistics. To collect the data, a sample of 20 sentences illustrating a range of syntactic constructions in the world's languages, we employ a combination of LLM prompting and searches in authentic Old English data. For annotation we assigned sentences to multiple students with limited prior exposure to UD, whose annotations we compare and adjudicate. Our results suggest that while current LLM outputs in Old English do not reflect authentic syntax, this can be mitigated by post-editing, and that although beginner annotators do not possess enough background to complete the task perfectly, taken together they can produce good results and learn from the experience. We also conduct preliminary parsing experiments using Modern English training data, and find that although performance on Old English is poor, parsing on annotated features (lemma, hyperlemma, gloss) leads to improved performance.
GUM-SAGE: A Novel Dataset and Approach for Graded Entity Salience Prediction
Apr 15, 2025Determining and ranking the most salient entities in a text is critical for user-facing systems, especially as users increasingly rely on models to interpret long documents they only partially read. Graded entity salience addresses this need by assigning entities scores that reflect their relative importance in a text. Existing approaches fall into two main categories: subjective judgments of salience, which allow for gradient scoring but lack consistency, and summarization-based methods, which define salience as mention-worthiness in a summary, promoting explainability but limiting outputs to binary labels (entities are either summary-worthy or not). In this paper, we introduce a novel approach for graded entity salience that combines the strengths of both approaches. Using an English dataset spanning 12 spoken and written genres, we collect 5 summaries per document and calculate each entity's salience score based on its presence across these summaries. Our approach shows stronger correlation with scores based on human summaries and alignments, and outperforms existing techniques, including LLMs. We release our data and code at https://github.com/jl908069/gum_sum_salience to support further research on graded salient entity extraction.
GDTB: Genre Diverse Data for English Shallow Discourse Parsing across Modalities, Text Types, and Domains
Nov 01, 2024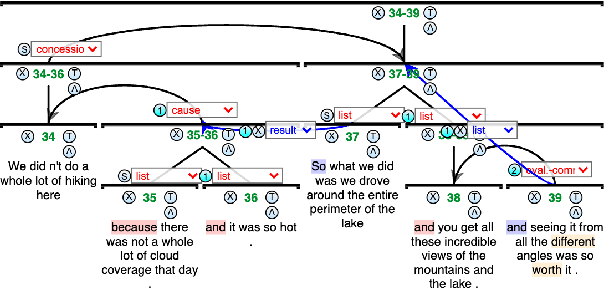
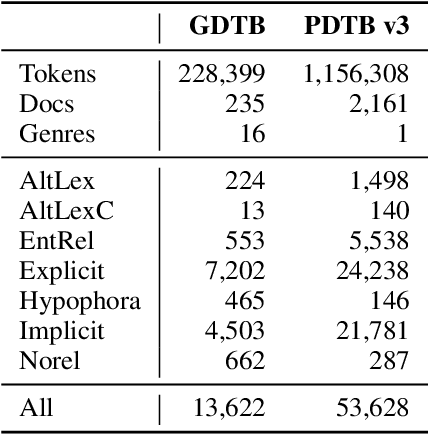
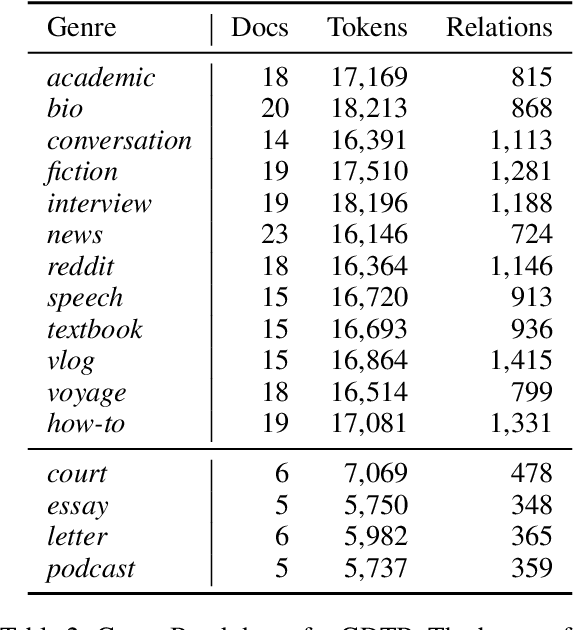
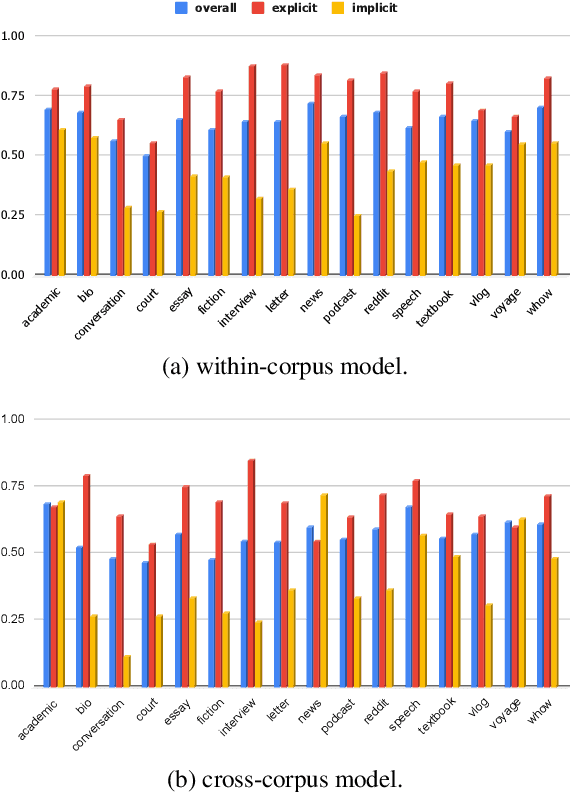
Work on shallow discourse parsing in English has focused on the Wall Street Journal corpus, the only large-scale dataset for the language in the PDTB framework. However, the data is not openly available, is restricted to the news domain, and is by now 35 years old. In this paper, we present and evaluate a new open-access, multi-genre benchmark for PDTB-style shallow discourse parsing, based on the existing UD English GUM corpus, for which discourse relation annotations in other frameworks already exist. In a series of experiments on cross-domain relation classification, we show that while our dataset is compatible with PDTB, substantial out-of-domain degradation is observed, which can be alleviated by joint training on both datasets.
Unifying the Scope of Bridging Anaphora Types in English: Bridging Annotations in ARRAU and GUM
Oct 02, 2024Comparing bridging annotations across coreference resources is difficult, largely due to a lack of standardization across definitions and annotation schemas and narrow coverage of disparate text domains across resources. To alleviate domain coverage issues and consolidate schemas, we compare guidelines and use interpretable predictive models to examine the bridging instances annotated in the GUM, GENTLE and ARRAU corpora. Examining these cases, we find that there is a large difference in types of phenomena annotated as bridging. Beyond theoretical results, we release a harmonized, subcategorized version of the test sets of GUM, GENTLE and the ARRAU Wall Street Journal data to promote meaningful and reliable evaluation of bridging resolution across domains.
Lacuna Language Learning: Leveraging RNNs for Ranked Text Completion in Digitized Coptic Manuscripts
Jul 17, 2024



Ancient manuscripts are frequently damaged, containing gaps in the text known as lacunae. In this paper, we present a bidirectional RNN model for character prediction of Coptic characters in manuscript lacunae. Our best model performs with 72% accuracy on single character reconstruction, but falls to 37% when reconstructing lacunae of various lengths. While not suitable for definitive manuscript reconstruction, we argue that our RNN model can help scholars rank the likelihood of textual reconstructions. As evidence, we use our RNN model to rank reconstructions in two early Coptic manuscripts. Our investigation shows that neural models can augment traditional methods of textual restoration, providing scholars with an additional tool to assess lacunae in Coptic manuscripts.
UCxn: Typologically Informed Annotation of Constructions Atop Universal Dependencies
Mar 26, 2024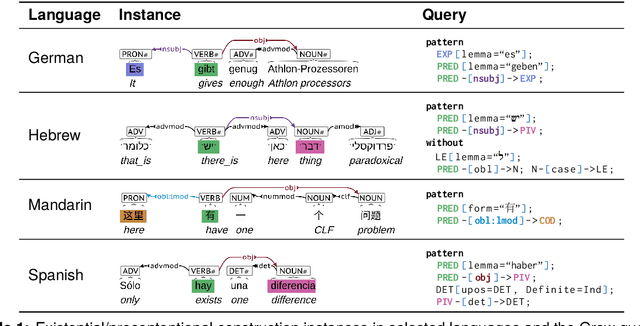
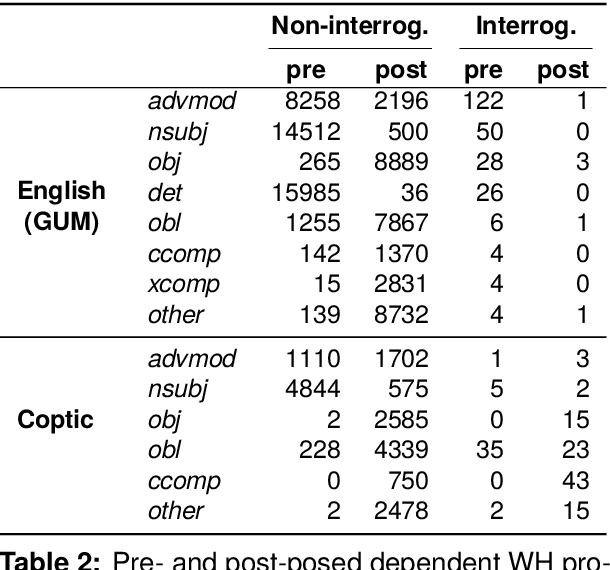
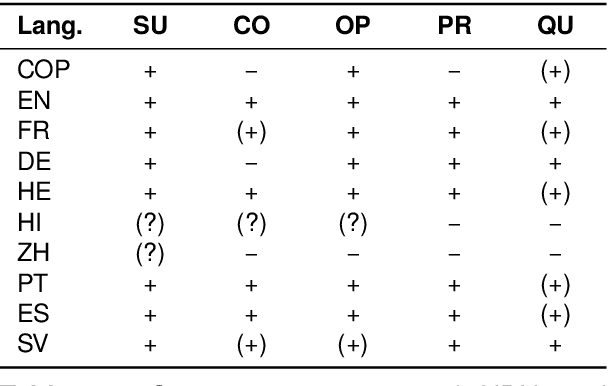
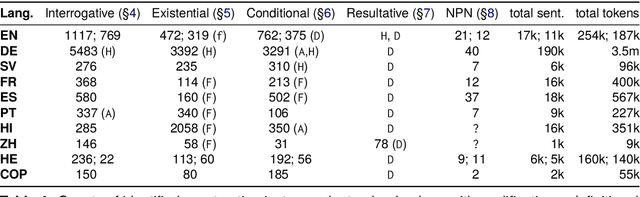
The Universal Dependencies (UD) project has created an invaluable collection of treebanks with contributions in over 140 languages. However, the UD annotations do not tell the full story. Grammatical constructions that convey meaning through a particular combination of several morphosyntactic elements -- for example, interrogative sentences with special markers and/or word orders -- are not labeled holistically. We argue for (i) augmenting UD annotations with a 'UCxn' annotation layer for such meaning-bearing grammatical constructions, and (ii) approaching this in a typologically informed way so that morphosyntactic strategies can be compared across languages. As a case study, we consider five construction families in ten languages, identifying instances of each construction in UD treebanks through the use of morphosyntactic patterns. In addition to findings regarding these particular constructions, our study yields important insights on methodology for describing and identifying constructions in language-general and language-particular ways, and lays the foundation for future constructional enrichment of UD treebanks.
SPLICE: A Singleton-Enhanced PipeLIne for Coreference REsolution
Mar 25, 2024



Singleton mentions, i.e.~entities mentioned only once in a text, are important to how humans understand discourse from a theoretical perspective. However previous attempts to incorporate their detection in end-to-end neural coreference resolution for English have been hampered by the lack of singleton mention spans in the OntoNotes benchmark. This paper addresses this limitation by combining predicted mentions from existing nested NER systems and features derived from OntoNotes syntax trees. With this approach, we create a near approximation of the OntoNotes dataset with all singleton mentions, achieving ~94% recall on a sample of gold singletons. We then propose a two-step neural mention and coreference resolution system, named SPLICE, and compare its performance to the end-to-end approach in two scenarios: the OntoNotes test set and the out-of-domain (OOD) OntoGUM corpus. Results indicate that reconstructed singleton training yields results comparable to end-to-end systems for OntoNotes, while improving OOD stability (+1.1 avg. F1). We conduct error analysis for mention detection and delve into its impact on coreference clustering, revealing that precision improvements deliver more substantial benefits than increases in recall for resolving coreference chains.