 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Priest to Doctor: Domain Adaptaion for Low-Resource Neural Machine Translation
Dec 01, 2024Many of the world's languages have insufficient data to train high-performing general neural machine translation (NMT) models, let alone domain-specific models, and often the only available parallel data are small amounts of religious texts. Hence, domain adaptation (DA) is a crucial issue faced by contemporary NMT and has, so far, been underexplored for low-resource languages. In this paper, we evaluate a set of methods from both low-resource NMT and DA in a realistic setting, in which we aim to translate between a high-resource and a low-resource language with access to only: a) parallel Bible data, b) a bilingual dictionary, and c) a monolingual target-domain corpus in the high-resource language. Our results show that the effectiveness of the tested methods varies, with the simplest one, DALI, being most effective. We follow up with a small human evaluation of DALI, which shows that there is still a need for more careful investigation of how to accomplish DA for low-resource NMT.
TAMS: Translation-Assisted Morphological Segmentation
Mar 21, 2024



Canonical morphological segmentation is the process of analyzing words into the standard (aka underlying) forms of their constituent morphemes. This is a core task in language documentation, and NLP systems have the potential to dramatically speed up this process. But in typical language documentation settings, training data for canonical morpheme segmentation is scarce, making it difficult to train high quality models. However, translation data is often much more abundant, and, in this work, we present a method that attempts to leverage this data in the canonical segmentation task. We propose a character-level sequence-to-sequence model that incorporates representations of translations obtained from pretrained high-resource monolingual language models as an additional signal. Our model outperforms the baseline in a super-low resource setting but yields mixed results on training splits with more data. While further work is needed to make translations useful in higher-resource settings, our model shows promise in severely resource-constrained settings.
eRST: A Signaled Graph Theory of Discourse Relations and Organization
Mar 20, 2024In this article we present Enhanced Rhetorical Structure Theory (eRST), a new theoretical framework for computational discourse analysis, based on an expansion of Rhetorical Structure Theory (RST). The framework encompasses discourse relation graphs with tree-breaking, nonprojective and concurrent relations, as well as implicit and explicit signals which give explainable rationales to our analyses. We survey shortcomings of RST and other existing frameworks, such as Segmented Discourse Representation Theory (SDRT), the Penn Discourse Treebank (PDTB) and Discourse Dependencies, and address these using constructs in the proposed theory. We provide annotation, search and visualization tools for data, and present and evaluate a freely available corpus of English annotated according to our framework, encompassing 12 spoken and written genres with over 200K tokens. Finally, we discuss automatic parsing, evaluation metrics and applications for data in our framework.
Syntactic Inductive Bias in Transformer Language Models: Especially Helpful for Low-Resource Languages?
Nov 01, 2023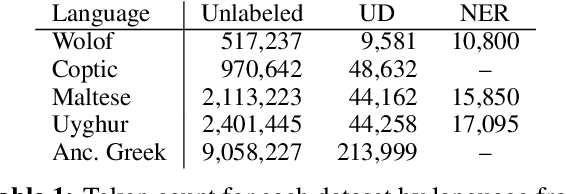
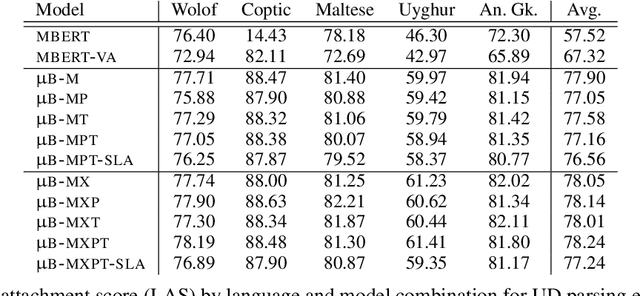
A line of work on Transformer-based language models such as BERT has attempted to use syntactic inductive bias to enhance the pretraining process, on the theory that building syntactic structure into the training process should reduce the amount of data needed for training. But such methods are often tested for high-resource languages such as English. In this work, we investigate whether these methods can compensate for data sparseness in low-resource languages, hypothesizing that they ought to be more effective for low-resource languages. We experiment with five low-resource languages: Uyghur, Wolof, Maltese, Coptic, and Ancient Greek. We find that these syntactic inductive bias methods produce uneven results in low-resource settings, and provide surprisingly little benefit in most cases.
GENTLE: A Genre-Diverse Multilayer Challenge Set for English NLP and Linguistic Evaluation
Jun 03, 2023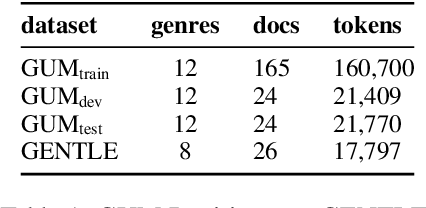
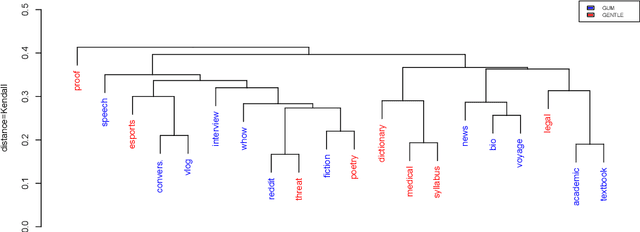
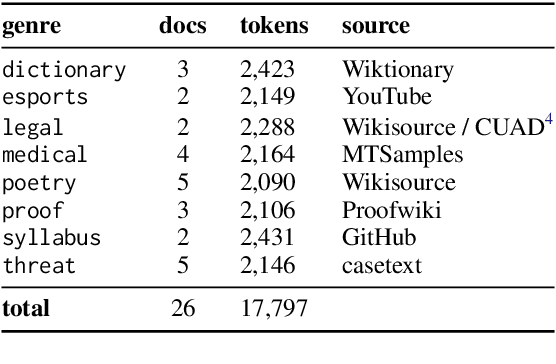
We present GENTLE, a new mixed-genre English challenge corpus totaling 17K tokens and consisting of 8 unusual text types for out-of domain evaluation: dictionary entries, esports commentaries, legal documents, medical notes, poetry, mathematical proofs, syllabuses, and threat letters. GENTLE is manually annotated for a variety of popular NLP tasks, including syntactic dependency parsing, entity recognition, coreference resolution, and discourse parsing. We evaluate state-of-the-art NLP systems on GENTLE and find severe degradation for at least some genres in their performance on all tasks, which indicates GENTLE's utility as an evaluation dataset for NLP systems.
PrOnto: Language Model Evaluations for 859 Languages
May 22, 2023



Evaluation datasets are critical resources for measuring the quality of pretrained language models. However, due to the high cost of dataset annotation, these resources are scarce for most languages other than English, making it difficult to assess the quality of language models. In this work, we present a new method for evaluation dataset construction which enables any language with a New Testament translation to receive a suite of evaluation datasets suitable for pretrained language model evaluation. The method critically involves aligning verses with those in the New Testament portion of English OntoNotes, and then projecting annotations from English to the target language, with no manual annotation required. We apply this method to 1051 New Testament translations in 859 and make them publicly available. Additionally, we conduct experiments which demonstrate the efficacy of our method for creating evaluation tasks which can assess language model quality.
MicroBERT: Effective Training of Low-resource Monolingual BERTs through Parameter Reduction and Multitask Learning
Jan 05, 2023



Transformer language models (TLMs) are critical for most NLP tasks, but they are difficult to create for low-resource languages because of how much pretraining data they require. In this work, we investigate two techniques for training monolingual TLMs in a low-resource setting: greatly reducing TLM size, and complementing the masked language modeling objective with two linguistically rich supervised tasks (part-of-speech tagging and dependency parsing). Results from 7 diverse languages indicate that our model, MicroBERT, is able to produce marked improvements in downstream task evaluations relative to a typical monolingual TLM pretraining approach. Specifically, we find that monolingual MicroBERT models achieve gains of up to 18% for parser LAS and 11% for NER F1 compared to a multilingual baseline, mBERT, while having less than 1% of its parameter count. We conclude reducing TLM parameter count and using labeled data for pretraining low-resource TLMs can yield large quality benefits and in some cases produce models that outperform multilingual approaches.
BERT Has Uncommon Sense: Similarity Ranking for Word Sense BERTology
Sep 20, 2021

An important question concerning contextualized word embedding (CWE) models like BERT is how well they can represent different word senses, especially those in the long tail of uncommon senses. Rather than build a WSD system as in previous work, we investigate contextualized embedding neighborhoods directly, formulating a query-by-example nearest neighbor retrieval task and examining ranking performance for words and senses in different frequency bands. In an evaluation on two English sense-annotated corpora, we find that several popular CWE models all outperform a random baseline even for proportionally rare senses, without explicit sense supervision. However, performance varies considerably even among models with similar architectures and pretraining regimes, with especially large differences for rare word senses, revealing that CWE models are not all created equal when it comes to approximating word senses in their native representations.
DisCoDisCo at the DISRPT2021 Shared Task: A System for Discourse Segmentation, Classification, and Connective Detection
Sep 20, 2021
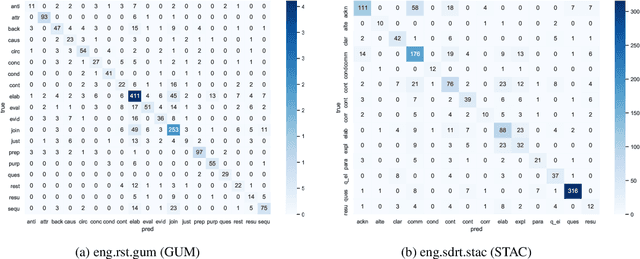
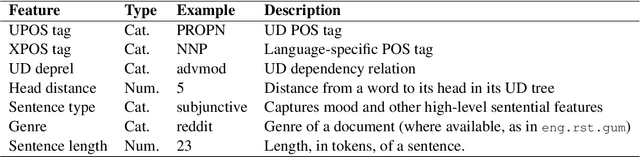

This paper describes our submission to the DISRPT2021 Shared Task on Discourse Unit Segmentation, Connective Detection, and Relation Classification. Our system, called DisCoDisCo, is a Transformer-based neural classifier which enhances contextualized word embeddings (CWEs) with hand-crafted features, relying on tokenwise sequence tagging for discourse segmentation and connective detection, and a feature-rich, encoder-less sentence pair classifier for relation classification. Our results for the first two tasks outperform SOTA scores from the previous 2019 shared task, and results on relation classification suggest strong performance on the new 2021 benchmark. Ablation tests show that including features beyond CWEs are helpful for both tasks, and a partial evaluation of multiple pre-trained Transformer-based language models indicates that models pre-trained on the Next Sentence Prediction (NSP) task are optimal for relation classification.
Supersense and Sensibility: Proxy Tasks for Semantic Annotation of Prepositions
Mar 27, 2021Prepositional supersense annotation is time-consuming and requires expert training. Here, we present two sensible methods for obtaining prepositional supersense annotations by eliciting surface substitution and similarity judgments. Four pilot studies suggest that both methods have potential for producing prepositional supersense annotations that are comparable in quality to expert annotations.