 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Structured Meaning Representations with Aspect Classification
Mar 25, 2026To fully capture the meaning of a sentence, semantic representations should encode aspect, which describes the internal temporal structure of events. In graph-based meaning representation frameworks such as Uniform Meaning Representations (UMR), aspect lets one know how events unfold over time, including distinctions such as states, activities, and completed events. Despite its importance, aspect remains sparsely annotated across semantic meaning representation frameworks. This has, in turn, hindered not only current manual annotation, but also the development of automatic systems capable of predicting aspectual information. In this paper, we introduce a new dataset of English sentences annotated with UMR aspect labels over Abstract Meaning Representation (AMR) graphs that lack the feature. We describe the annotation scheme and guidelines used to label eventive predicates according to the UMR aspect lattice, as well as the annotation pipeline used to ensure consistency and quality across annotators through a multi-step adjudication process. To demonstrate the utility of our dataset for future automation, we present baseline experiments using three modeling approaches. Our results establish initial benchmarks for automatic UMR aspect prediction and provide a foundation for integrating aspect into semantic meaning representations more broadly.
CWoMP: Morpheme Representation Learning for Interlinear Glossing
Mar 18, 2026Interlinear glossed text (IGT) is a standard notation for language documentation which is linguistically rich but laborious to produce manually. Recent automated IGT methods treat glosses as character sequences, neglecting their compositional structure. We propose CWoMP (Contrastive Word-Morpheme Pretraining), which instead treats morphemes as atomic form-meaning units with learned representations. A contrastively trained encoder aligns words-in-context with their constituent morphemes in a shared embedding space; an autoregressive decoder then generates the morpheme sequence by retrieving entries from a mutable lexicon of these embeddings. Predictions are interpretable--grounded in lexicon entries--and users can improve results at inference time by expanding the lexicon without retraining. We evaluate on diverse low-resource languages, showing that CWoMP outperforms existing methods while being significantly more efficient, with particularly strong gains in extremely low-resource settings.
Massively Multilingual Joint Segmentation and Glossing
Jan 16, 2026Automated interlinear gloss prediction with neural networks is a promising approach to accelerate language documentation efforts. However, while state-of-the-art models like GlossLM achieve high scores on glossing benchmarks, user studies with linguists have found critical barriers to the usefulness of such models in real-world scenarios. In particular, existing models typically generate morpheme-level glosses but assign them to whole words without predicting the actual morpheme boundaries, making the predictions less interpretable and thus untrustworthy to human annotators. We conduct the first study on neural models that jointly predict interlinear glosses and the corresponding morphological segmentation from raw text. We run experiments to determine the optimal way to train models that balance segmentation and glossing accuracy, as well as the alignment between the two tasks. We extend the training corpus of GlossLM and pretrain PolyGloss, a family of seq2seq multilingual models for joint segmentation and glossing that outperforms GlossLM on glossing and beats various open-source LLMs on segmentation, glossing, and alignment. In addition, we demonstrate that PolyGloss can be quickly adapted to a new dataset via low-rank adaptation.
Neural Induction of Finite-State Transducers
Jan 16, 2026Finite-State Transducers (FSTs) are effective models for string-to-string rewriting tasks, often providing the efficiency necessary for high-performance applications, but constructing transducers by hand is difficult. In this work, we propose a novel method for automatically constructing unweighted FSTs following the hidden state geometry learned by a recurrent neural network. We evaluate our methods on real-world datasets for morphological inflection, grapheme-to-phoneme prediction, and historical normalization, showing that the constructed FSTs are highly accurate and robust for many datasets, substantially outperforming classical transducer learning algorithms by up to 87% accuracy on held-out test sets.
Untangling the Influence of Typology, Data and Model Architecture on Ranking Transfer Languages for Cross-Lingual POS Tagging
Mar 25, 2025Cross-lingual transfer learning is an invaluable tool for overcoming data scarcity, yet selecting a suitable transfer language remains a challenge. The precise roles of linguistic typology, training data, and model architecture in transfer language choice are not fully understood. We take a holistic approach, examining how both dataset-specific and fine-grained typological features influence transfer language selection for part-of-speech tagging, considering two different sources for morphosyntactic features. While previous work examines these dynamics in the context of bilingual biLSTMS, we extend our analysis to a more modern transfer learning pipeline: zero-shot prediction with pretrained multilingual models. We train a series of transfer language ranking systems and examine how different feature inputs influence ranker performance across architectures. Word overlap, type-token ratio, and genealogical distance emerge as top features across all architectures. Our findings reveal that a combination of typological and dataset-dependent features leads to the best rankings, and that good performance can be obtained with either feature group on its own.
From Priest to Doctor: Domain Adaptaion for Low-Resource Neural Machine Translation
Dec 01, 2024Many of the world's languages have insufficient data to train high-performing general neural machine translation (NMT) models, let alone domain-specific models, and often the only available parallel data are small amounts of religious texts. Hence, domain adaptation (DA) is a crucial issue faced by contemporary NMT and has, so far, been underexplored for low-resource languages. In this paper, we evaluate a set of methods from both low-resource NMT and DA in a realistic setting, in which we aim to translate between a high-resource and a low-resource language with access to only: a) parallel Bible data, b) a bilingual dictionary, and c) a monolingual target-domain corpus in the high-resource language. Our results show that the effectiveness of the tested methods varies, with the simplest one, DALI, being most effective. We follow up with a small human evaluation of DALI, which shows that there is still a need for more careful investigation of how to accomplish DA for low-resource NMT.
Boosting the Capabilities of Compact Models in Low-Data Contexts with Large Language Models and Retrieval-Augmented Generation
Oct 01, 2024The data and compute requirements of current language modeling technology pose challenges for the processing and analysis of low-resource languages. Declarative linguistic knowledge has the potential to partially bridge this data scarcity gap by providing models with useful inductive bias in the form of language-specific rules. In this paper, we propose a retrieval augmented generation (RAG) framework backed by a large language model (LLM) to correct the output of a smaller model for the linguistic task of morphological glossing. We leverage linguistic information to make up for the lack of data and trainable parameters, while allowing for inputs from written descriptive grammars interpreted and distilled through an LLM. The results demonstrate that significant leaps in performance and efficiency are possible with the right combination of: a) linguistic inputs in the form of grammars, b) the interpretive power of LLMs, and c) the trainability of smaller token classification networks. We show that a compact, RAG-supported model is highly effective in data-scarce settings, achieving a new state-of-the-art for this task and our target languages. Our work also offers documentary linguists a more reliable and more usable tool for morphological glossing by providing well-reasoned explanations and confidence scores for each output.
Can we teach language models to gloss endangered languages?
Jun 27, 2024
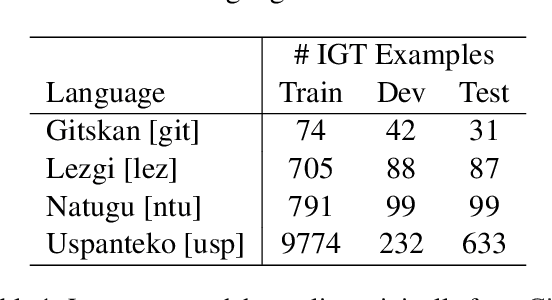

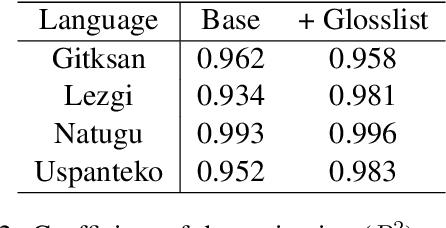
Interlinear glossed text (IGT) is a popular format in language documentation projects, where each morpheme is labeled with a descriptive annotation. Automating the creation of interlinear glossed text can be desirable to reduce annotator effort and maintain consistency across annotated corpora. Prior research has explored a number of statistical and neural methods for automatically producing IGT. As large language models (LLMs) have showed promising results across multilingual tasks, even for rare, endangered languages, it is natural to wonder whether they can be utilized for the task of generating IGT. We explore whether LLMs can be effective at the task of interlinear glossing with in-context learning, without any traditional training. We propose new approaches for selecting examples to provide in-context, observing that targeted selection can significantly improve performance. We find that LLM-based methods beat standard transformer baselines, despite requiring no training at all. These approaches still underperform state-of-the-art supervised systems for the task, but are highly practical for researchers outside of the NLP community, requiring minimal effort to use.
TAMS: Translation-Assisted Morphological Segmentation
Mar 21, 2024



Canonical morphological segmentation is the process of analyzing words into the standard (aka underlying) forms of their constituent morphemes. This is a core task in language documentation, and NLP systems have the potential to dramatically speed up this process. But in typical language documentation settings, training data for canonical morpheme segmentation is scarce, making it difficult to train high quality models. However, translation data is often much more abundant, and, in this work, we present a method that attempts to leverage this data in the canonical segmentation task. We propose a character-level sequence-to-sequence model that incorporates representations of translations obtained from pretrained high-resource monolingual language models as an additional signal. Our model outperforms the baseline in a super-low resource setting but yields mixed results on training splits with more data. While further work is needed to make translations useful in higher-resource settings, our model shows promise in severely resource-constrained settings.
GlossLM: Multilingual Pretraining for Low-Resource Interlinear Glossing
Mar 11, 2024



A key aspect of language documentation is the creation of annotated text in a format such as interlinear glossed text (IGT), which captures fine-grained morphosyntactic analyses in a morpheme-by-morpheme format. Prior work has explored methods to automatically generate IGT in order to reduce the time cost of language analysis. However, many languages (particularly those requiring preservation) lack sufficient IGT data to train effective models, and crosslingual transfer has been proposed as a method to overcome this limitation. We compile the largest existing corpus of IGT data from a variety of sources, covering over 450k examples across 1.8k languages, to enable research on crosslingual transfer and IGT generation. Then, we pretrain a large multilingual model on a portion of this corpus, and further finetune it to specific languages. Our model is competitive with state-of-the-art methods for segmented data and large monolingual datasets. Meanwhile, our model outperforms SOTA models on unsegmented text and small corpora by up to 6.6% morpheme accuracy, demonstrating the effectiveness of crosslingual transfer for low-resource languages.