 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMassively Multilingual Joint Segmentation and Glossing
Jan 16, 2026Automated interlinear gloss prediction with neural networks is a promising approach to accelerate language documentation efforts. However, while state-of-the-art models like GlossLM achieve high scores on glossing benchmarks, user studies with linguists have found critical barriers to the usefulness of such models in real-world scenarios. In particular, existing models typically generate morpheme-level glosses but assign them to whole words without predicting the actual morpheme boundaries, making the predictions less interpretable and thus untrustworthy to human annotators. We conduct the first study on neural models that jointly predict interlinear glosses and the corresponding morphological segmentation from raw text. We run experiments to determine the optimal way to train models that balance segmentation and glossing accuracy, as well as the alignment between the two tasks. We extend the training corpus of GlossLM and pretrain PolyGloss, a family of seq2seq multilingual models for joint segmentation and glossing that outperforms GlossLM on glossing and beats various open-source LLMs on segmentation, glossing, and alignment. In addition, we demonstrate that PolyGloss can be quickly adapted to a new dataset via low-rank adaptation.
Synthetic Socratic Debates: Examining Persona Effects on Moral Decision and Persuasion Dynamics
Jun 14, 2025As large language models (LLMs) are increasingly used in morally sensitive domains, it is crucial to understand how persona traits affect their moral reasoning and persuasive behavior. We present the first large-scale study of multi-dimensional persona effects in AI-AI debates over real-world moral dilemmas. Using a 6-dimensional persona space (age, gender, country, class, ideology, and personality), we simulate structured debates between AI agents over 131 relationship-based cases. Our results show that personas affect initial moral stances and debate outcomes, with political ideology and personality traits exerting the strongest influence. Persuasive success varies across traits, with liberal and open personalities reaching higher consensus and win rates. While logit-based confidence grows during debates, emotional and credibility-based appeals diminish, indicating more tempered argumentation over time. These trends mirror findings from psychology and cultural studies, reinforcing the need for persona-aware evaluation frameworks for AI moral reasoning.
Not-Just-Scaling Laws: Towards a Better Understanding of the Downstream Impact of Language Model Design Decisions
Mar 05, 2025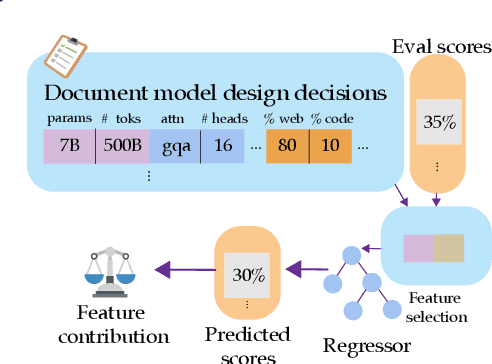
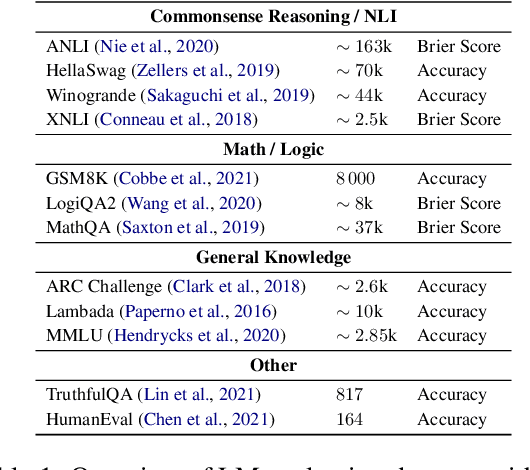
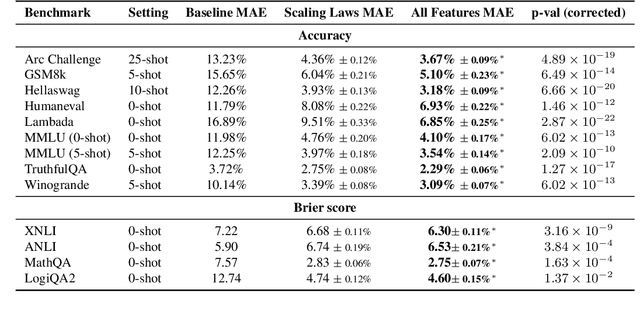
Improvements in language model capabilities are often attributed to increasing model size or training data, but in some cases smaller models trained on curated data or with different architectural decisions can outperform larger ones trained on more tokens. What accounts for this? To quantify the impact of these design choices, we meta-analyze 92 open-source pretrained models across a wide array of scales, including state-of-the-art open-weights models as well as less performant models and those with less conventional design decisions. We find that by incorporating features besides model size and number of training tokens, we can achieve a relative 3-28% increase in ability to predict downstream performance compared with using scale alone. Analysis of model design decisions reveal insights into data composition, such as the trade-off between language and code tasks at 15-25\% code, as well as the better performance of some architectural decisions such as choosing rotary over learned embeddings. Broadly, our framework lays a foundation for more systematic investigation of how model development choices shape final capabilities.
What Goes Into a LM Acceptability Judgment? Rethinking the Impact of Frequency and Length
Nov 04, 2024


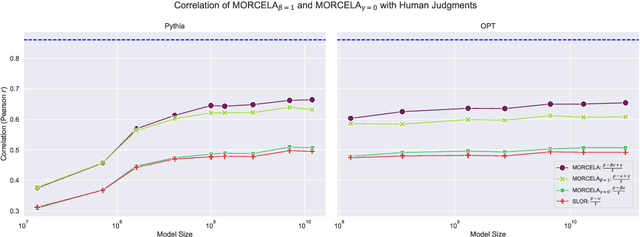
When comparing the linguistic capabilities of language models (LMs) with humans using LM probabilities, factors such as the length of the sequence and the unigram frequency of lexical items have a significant effect on LM probabilities in ways that humans are largely robust to. Prior works in comparing LM and human acceptability judgments treat these effects uniformly across models, making a strong assumption that models require the same degree of adjustment to control for length and unigram frequency effects. We propose MORCELA, a new linking theory between LM scores and acceptability judgments where the optimal level of adjustment for these effects is estimated from data via learned parameters for length and unigram frequency. We first show that MORCELA outperforms a commonly used linking theory for acceptability--SLOR (Pauls and Klein, 2012; Lau et al. 2017)--across two families of transformer LMs (Pythia and OPT). Furthermore, we demonstrate that the assumed degrees of adjustment in SLOR for length and unigram frequency overcorrect for these confounds, and that larger models require a lower relative degree of adjustment for unigram frequency, though a significant amount of adjustment is still necessary for all models. Finally, our subsequent analysis shows that larger LMs' lower susceptibility to frequency effects can be explained by an ability to better predict rarer words in context.
CMULAB: An Open-Source Framework for Training and Deployment of Natural Language Processing Models
Apr 03, 2024Effectively using Natural Language Processing (NLP) tools in under-resourced languages requires a thorough understanding of the language itself, familiarity with the latest models and training methodologies, and technical expertise to deploy these models. This could present a significant obstacle for language community members and linguists to use NLP tools. This paper introduces the CMU Linguistic Annotation Backend, an open-source framework that simplifies model deployment and continuous human-in-the-loop fine-tuning of NLP models. CMULAB enables users to leverage the power of multilingual models to quickly adapt and extend existing tools for speech recognition, OCR, translation, and syntactic analysis to new languages, even with limited training data. We describe various tools and APIs that are currently available and how developers can easily add new models/functionality to the framework. Code is available at https://github.com/neulab/cmulab along with a live demo at https://cmulab.dev
Wav2Gloss: Generating Interlinear Glossed Text from Speech
Mar 19, 2024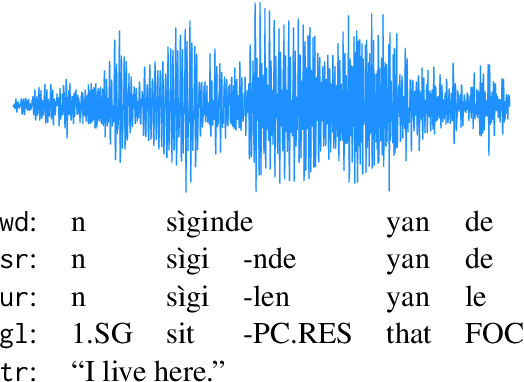
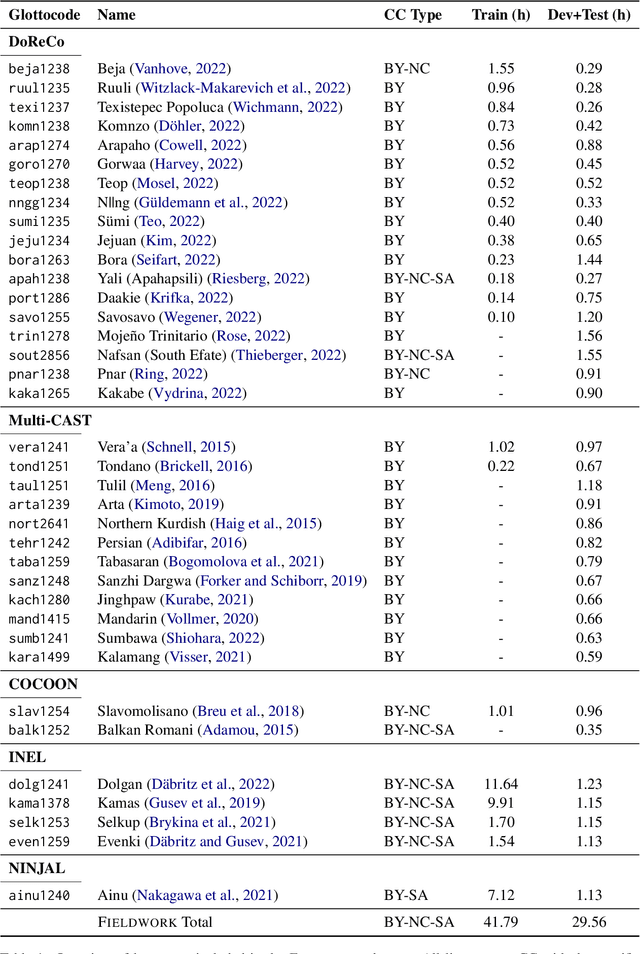
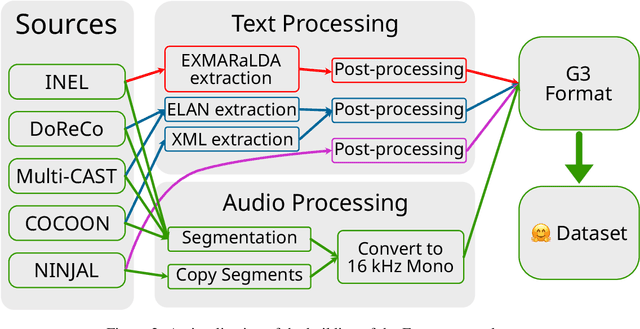
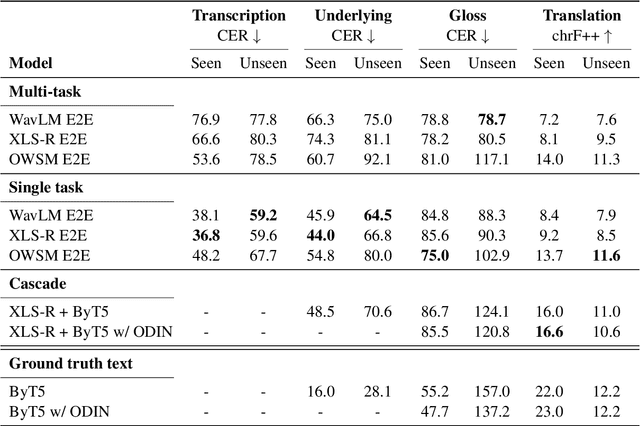
Thousands of the world's languages are in danger of extinction--a tremendous threat to cultural identities and human language diversity. Interlinear Glossed Text (IGT) is a form of linguistic annotation that can support documentation and resource creation for these languages' communities. IGT typically consists of (1) transcriptions, (2) morphological segmentation, (3) glosses, and (4) free translations to a majority language. We propose Wav2Gloss: a task to extract these four annotation components automatically from speech, and introduce the first dataset to this end, Fieldwork: a corpus of speech with all these annotations covering 37 languages with standard formatting and train/dev/test splits. We compare end-to-end and cascaded Wav2Gloss methods, with analysis suggesting that pre-trained decoders assist with translation and glossing, that multi-task and multilingual approaches are underperformant, and that end-to-end systems perform better than cascaded systems, despite the text-only systems' advantages. We provide benchmarks to lay the ground work for future research on IGT generation from speech.
GlossLM: Multilingual Pretraining for Low-Resource Interlinear Glossing
Mar 11, 2024



A key aspect of language documentation is the creation of annotated text in a format such as interlinear glossed text (IGT), which captures fine-grained morphosyntactic analyses in a morpheme-by-morpheme format. Prior work has explored methods to automatically generate IGT in order to reduce the time cost of language analysis. However, many languages (particularly those requiring preservation) lack sufficient IGT data to train effective models, and crosslingual transfer has been proposed as a method to overcome this limitation. We compile the largest existing corpus of IGT data from a variety of sources, covering over 450k examples across 1.8k languages, to enable research on crosslingual transfer and IGT generation. Then, we pretrain a large multilingual model on a portion of this corpus, and further finetune it to specific languages. Our model is competitive with state-of-the-art methods for segmented data and large monolingual datasets. Meanwhile, our model outperforms SOTA models on unsegmented text and small corpora by up to 6.6% morpheme accuracy, demonstrating the effectiveness of crosslingual transfer for low-resource languages.
Do LLMs exhibit human-like response biases? A case study in survey design
Nov 07, 2023As large language models (LLMs) become more capable, there is growing excitement about the possibility of using LLMs as proxies for humans in real-world tasks where subjective labels are desired, such as in surveys and opinion polling. One widely-cited barrier to the adoption of LLMs is their sensitivity to prompt wording -- but interestingly, humans also display sensitivities to instruction changes in the form of response biases. As such, we argue that if LLMs are going to be used to approximate human opinions, it is necessary to investigate the extent to which LLMs also reflect human response biases, if at all. In this work, we use survey design as a case study, where human response biases caused by permutations in wordings of ``prompts'' have been extensively studied. Drawing from prior work in social psychology, we design a dataset and propose a framework to evaluate whether LLMs exhibit human-like response biases in survey questionnaires. Our comprehensive evaluation of nine models shows that popular open and commercial LLMs generally fail to reflect human-like behavior. These inconsistencies tend to be more prominent in models that have been instruction fine-tuned. Furthermore, even if a model shows a significant change in the same direction as humans, we find that perturbations that are not meant to elicit significant changes in humans may also result in a similar change, suggesting that such a result could be partially due to other spurious correlations. These results highlight the potential pitfalls of using LLMs to substitute humans in parts of the annotation pipeline, and further underscore the importance of finer-grained characterizations of model behavior. Our code, dataset, and collected samples are available at https://github.com/lindiatjuatja/BiasMonkey
Syntax and Semantics Meet in the "Middle": Probing the Syntax-Semantics Interface of LMs Through Agentivity
May 29, 2023



Recent advances in large language models have prompted researchers to examine their abilities across a variety of linguistic tasks, but little has been done to investigate how models handle the interactions in meaning across words and larger syntactic forms -- i.e. phenomena at the intersection of syntax and semantics. We present the semantic notion of agentivity as a case study for probing such interactions. We created a novel evaluation dataset by utilitizing the unique linguistic properties of a subset of optionally transitive English verbs. This dataset was used to prompt varying sizes of three model classes to see if they are sensitive to agentivity at the lexical level, and if they can appropriately employ these word-level priors given a specific syntactic context. Overall, GPT-3 text-davinci-003 performs extremely well across all experiments, outperforming all other models tested by far. In fact, the results are even better correlated with human judgements than both syntactic and semantic corpus statistics. This suggests that LMs may potentially serve as more useful tools for linguistic annotation, theory testing, and discovery than select corpora for certain tasks.