 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneral Scales Unlock AI Evaluation with Explanatory and Predictive Power
Mar 09, 2025Ensuring safe and effective use of AI requires understanding and anticipating its performance on novel tasks, from advanced scientific challenges to transformed workplace activities. So far, benchmarking has guided progress in AI, but it has offered limited explanatory and predictive power for general-purpose AI systems, given the low transferability across diverse tasks. In this paper, we introduce general scales for AI evaluation that can explain what common AI benchmarks really measure, extract ability profiles of AI systems, and predict their performance for new task instances, in- and out-of-distribution. Our fully-automated methodology builds on 18 newly-crafted rubrics that place instance demands on general scales that do not saturate. Illustrated for 15 large language models and 63 tasks, high explanatory power is unleashed from inspecting the demand and ability profiles, bringing insights on the sensitivity and specificity exhibited by different benchmarks, and how knowledge, metacognition and reasoning are affected by model size, chain-of-thought and distillation. Surprisingly, high predictive power at the instance level becomes possible using these demand levels, providing superior estimates over black-box baseline predictors based on embeddings or finetuning, especially in out-of-distribution settings (new tasks and new benchmarks). The scales, rubrics, battery, techniques and results presented here represent a major step for AI evaluation, underpinning the reliable deployment of AI in the years ahead.
Generating Situated Reflection Triggers about Alternative Solution Paths: A Case Study of Generative AI for Computer-Supported Collaborative Learning
Apr 28, 2024



An advantage of Large Language Models (LLMs) is their contextualization capability - providing different responses based on student inputs like solution strategy or prior discussion, to potentially better engage students than standard feedback. We present a design and evaluation of a proof-of-concept LLM application to offer students dynamic and contextualized feedback. Specifically, we augment an Online Programming Exercise bot for a college-level Cloud Computing course with ChatGPT, which offers students contextualized reflection triggers during a collaborative query optimization task in database design. We demonstrate that LLMs can be used to generate highly situated reflection triggers that incorporate details of the collaborative discussion happening in context. We discuss in depth the exploration of the design space of the triggers and their correspondence with the learning objectives as well as the impact on student learning in a pilot study with 34 students.
Do LLMs exhibit human-like response biases? A case study in survey design
Nov 07, 2023As large language models (LLMs) become more capable, there is growing excitement about the possibility of using LLMs as proxies for humans in real-world tasks where subjective labels are desired, such as in surveys and opinion polling. One widely-cited barrier to the adoption of LLMs is their sensitivity to prompt wording -- but interestingly, humans also display sensitivities to instruction changes in the form of response biases. As such, we argue that if LLMs are going to be used to approximate human opinions, it is necessary to investigate the extent to which LLMs also reflect human response biases, if at all. In this work, we use survey design as a case study, where human response biases caused by permutations in wordings of ``prompts'' have been extensively studied. Drawing from prior work in social psychology, we design a dataset and propose a framework to evaluate whether LLMs exhibit human-like response biases in survey questionnaires. Our comprehensive evaluation of nine models shows that popular open and commercial LLMs generally fail to reflect human-like behavior. These inconsistencies tend to be more prominent in models that have been instruction fine-tuned. Furthermore, even if a model shows a significant change in the same direction as humans, we find that perturbations that are not meant to elicit significant changes in humans may also result in a similar change, suggesting that such a result could be partially due to other spurious correlations. These results highlight the potential pitfalls of using LLMs to substitute humans in parts of the annotation pipeline, and further underscore the importance of finer-grained characterizations of model behavior. Our code, dataset, and collected samples are available at https://github.com/lindiatjuatja/BiasMonkey
Large Language Models Help Humans Verify Truthfulness -- Except When They Are Convincingly Wrong
Oct 19, 2023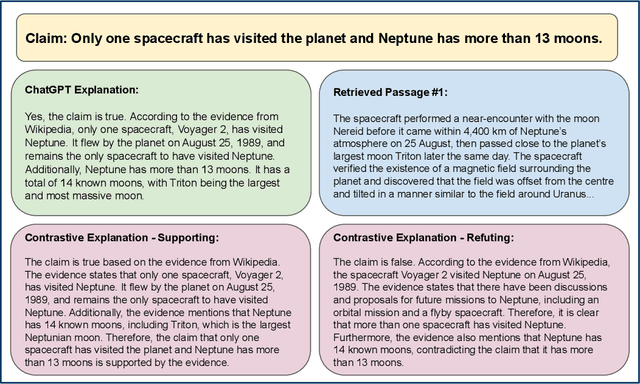
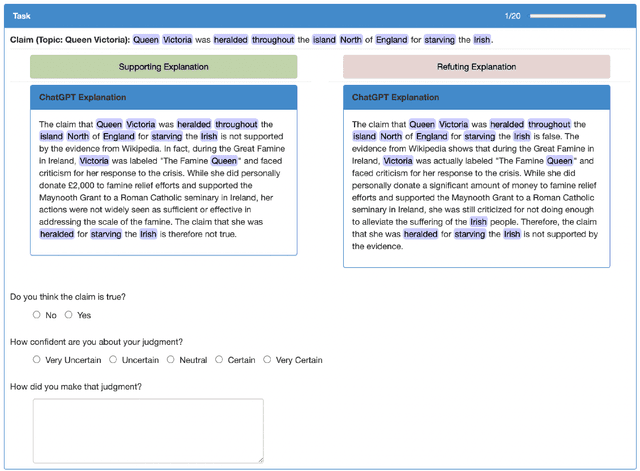
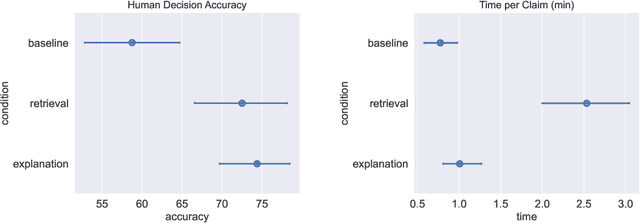
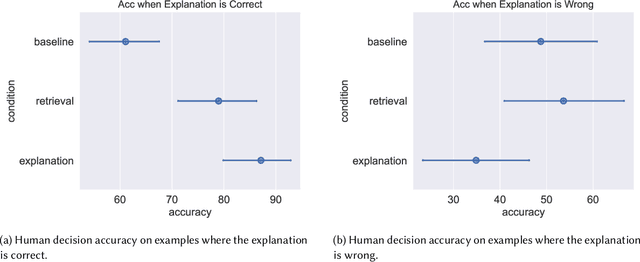
Large Language Models (LLMs) are increasingly used for accessing information on the web. Their truthfulness and factuality are thus of great interest. To help users make the right decisions about the information they're getting, LLMs should not only provide but also help users fact-check information. In this paper, we conduct experiments with 80 crowdworkers in total to compare language models with search engines (information retrieval systems) at facilitating fact-checking by human users. We prompt LLMs to validate a given claim and provide corresponding explanations. Users reading LLM explanations are significantly more efficient than using search engines with similar accuracy. However, they tend to over-rely the LLMs when the explanation is wrong. To reduce over-reliance on LLMs, we ask LLMs to provide contrastive information - explain both why the claim is true and false, and then we present both sides of the explanation to users. This contrastive explanation mitigates users' over-reliance on LLMs, but cannot significantly outperform search engines. However, showing both search engine results and LLM explanations offers no complementary benefits as compared to search engines alone. Taken together, natural language explanations by LLMs may not be a reliable replacement for reading the retrieved passages yet, especially in high-stakes settings where over-relying on wrong AI explanations could lead to critical consequences.
"Merge Conflicts!" Exploring the Impacts of External Distractors to Parametric Knowledge Graphs
Sep 15, 2023



Large language models (LLMs) acquire extensive knowledge during pre-training, known as their parametric knowledge. However, in order to remain up-to-date and align with human instructions, LLMs inevitably require external knowledge during their interactions with users. This raises a crucial question: How will LLMs respond when external knowledge interferes with their parametric knowledge? To investigate this question, we propose a framework that systematically elicits LLM parametric knowledge and introduces external knowledge. Specifically, we uncover the impacts by constructing a parametric knowledge graph to reveal the different knowledge structures of LLMs, and introduce external knowledge through distractors of varying degrees, methods, positions, and formats. Our experiments on both black-box and open-source models demonstrate that LLMs tend to produce responses that deviate from their parametric knowledge, particularly when they encounter direct conflicts or confounding changes of information within detailed contexts. We also find that while LLMs are sensitive to the veracity of external knowledge, they can still be distracted by unrelated information. These findings highlight the risk of hallucination when integrating external knowledge, even indirectly, during interactions with current LLMs. All the data and results are publicly available.