 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMind the Sim2Real Gap in User Simulation for Agentic Tasks
Mar 11, 2026As NLP evaluation shifts from static benchmarks to multi-turn interactive settings, LLM-based simulators have become widely used as user proxies, serving two roles: generating user turns and providing evaluation signals. Yet, these simulations are frequently assumed to be faithful to real human behaviors, often without rigorous verification. We formalize the Sim2Real gap in user simulation and present the first study running the full $τ$-bench protocol with real humans (451 participants, 165 tasks), benchmarking 31 LLM simulators across proprietary, open-source, and specialized families using the User-Sim Index (USI), a metric we introduce to quantify how well LLM simulators resemble real user interactive behaviors and feedback. Behaviorally, LLM simulators are excessively cooperative, stylistically uniform, and lack realistic frustration or ambiguity, creating an "easy mode" that inflates agent success rates above the human baseline. In evaluations, real humans provide nuanced judgments across eight quality dimensions while simulated users produce uniformly more positive feedback; rule-based rewards are failing to capture rich feedback signals generated by human users. Overall, higher general model capability does not necessarily yield more faithful user simulation. These findings highlight the importance of human validation when using LLM-based user simulators in the agent development cycle and motivate improved models for user simulation.
What Prompts Don't Say: Understanding and Managing Underspecification in LLM Prompts
May 19, 2025Building LLM-powered software requires developers to communicate their requirements through natural language, but developer prompts are frequently underspecified, failing to fully capture many user-important requirements. In this paper, we present an in-depth analysis of prompt underspecification, showing that while LLMs can often (41.1%) guess unspecified requirements by default, such behavior is less robust: Underspecified prompts are 2x more likely to regress over model or prompt changes, sometimes with accuracy drops by more than 20%. We then demonstrate that simply adding more requirements to a prompt does not reliably improve performance, due to LLMs' limited instruction-following capabilities and competing constraints, and standard prompt optimizers do not offer much help. To address this, we introduce novel requirements-aware prompt optimization mechanisms that can improve performance by 4.8% on average over baselines that naively specify everything in the prompt. Beyond prompt optimization, we envision that effectively managing prompt underspecification requires a broader process, including proactive requirements discovery, evaluation, and monitoring.
What You Say = What You Want? Teaching Humans to Articulate Requirements for LLMs
Sep 13, 2024



Prompting ChatGPT to achieve complex goals (e.g., creating a customer support chatbot) often demands meticulous prompt engineering, including aspects like fluent writing and chain-of-thought techniques. While emerging prompt optimizers can automatically refine many of these aspects, we argue that clearly conveying customized requirements (e.g., how to handle diverse inputs) remains a human-centric challenge. In this work, we introduce Requirement-Oriented Prompt Engineering (ROPE), a paradigm that focuses human attention on generating clear, complete requirements during prompting. We implement ROPE through an assessment and training suite that provides deliberate practice with LLM-generated feedback. In a study with 30 novices, we show that requirement-focused training doubles novices' prompting performance, significantly outperforming conventional prompt engineering training and prompt optimization. We also demonstrate that high-quality LLM outputs are directly tied to the quality of input requirements. Our work paves the way for more effective task delegation in human-LLM collaborative prompting.
Generating Situated Reflection Triggers about Alternative Solution Paths: A Case Study of Generative AI for Computer-Supported Collaborative Learning
Apr 28, 2024



An advantage of Large Language Models (LLMs) is their contextualization capability - providing different responses based on student inputs like solution strategy or prior discussion, to potentially better engage students than standard feedback. We present a design and evaluation of a proof-of-concept LLM application to offer students dynamic and contextualized feedback. Specifically, we augment an Online Programming Exercise bot for a college-level Cloud Computing course with ChatGPT, which offers students contextualized reflection triggers during a collaborative query optimization task in database design. We demonstrate that LLMs can be used to generate highly situated reflection triggers that incorporate details of the collaborative discussion happening in context. We discuss in depth the exploration of the design space of the triggers and their correspondence with the learning objectives as well as the impact on student learning in a pilot study with 34 students.
ChaTA: Towards an Intelligent Question-Answer Teaching Assistant using Open-Source LLMs
Nov 13, 2023Responding to the thousands of student questions on online QA platforms each semester has a considerable human cost, particularly in computing courses with rapidly growing enrollments. To address the challenges of scalable and intelligent question-answering (QA), we introduce an innovative solution that leverages open-source Large Language Models (LLMs) from the LLaMA-2 family to ensure data privacy. Our approach combines augmentation techniques such as retrieval augmented generation (RAG), supervised fine-tuning (SFT), and learning from human preferences data using Direct Preference Optimization (DPO). Through extensive experimentation on a Piazza dataset from an introductory CS course, comprising 10,000 QA pairs and 1,500 pairs of preference data, we demonstrate a significant 30% improvement in the quality of answers, with RAG being a particularly impactful addition. Our contributions include the development of a novel architecture for educational QA, extensive evaluations of LLM performance utilizing both human assessments and LLM-based metrics, and insights into the challenges and future directions of educational data processing. This work paves the way for the development of CHATA, an intelligent QA assistant customizable for courses with an online QA platform
* Updates for camera-ready submission
Is AI the better programming partner? Human-Human Pair Programming vs. Human-AI pAIr Programming
Jun 09, 2023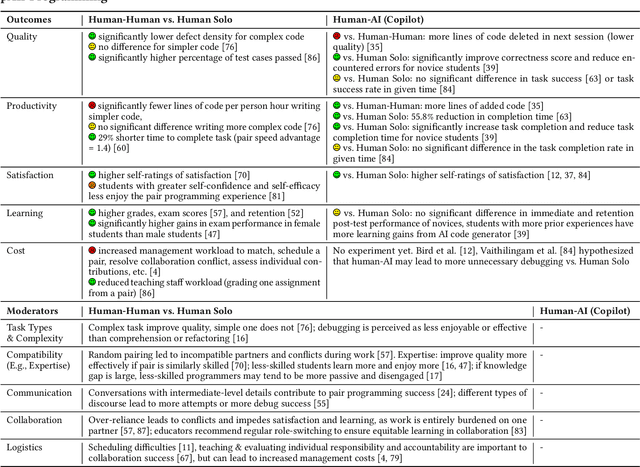
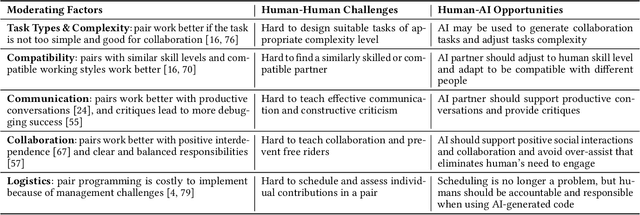
The emergence of large-language models (LLMs) that excel at code generation and commercial products such as GitHub's Copilot has sparked interest in human-AI pair programming (referred to as "pAIr programming") where an AI system collaborates with a human programmer. While traditional pair programming between humans has been extensively studied, it remains uncertain whether its findings can be applied to human-AI pair programming. We compare human-human and human-AI pair programming, exploring their similarities and differences in interaction, measures, benefits, and challenges. We find that the effectiveness of both approaches is mixed in the literature (though the measures used for pAIr programming are not as comprehensive). We summarize moderating factors on the success of human-human pair programming, which provides opportunities for pAIr programming research. For example, mismatched expertise makes pair programming less productive, therefore well-designed AI programming assistants may adapt to differences in expertise levels.