 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVoxtral TTS
Mar 26, 2026We introduce Voxtral TTS, an expressive multilingual text-to-speech model that generates natural speech from as little as 3 seconds of reference audio. Voxtral TTS adopts a hybrid architecture that combines auto-regressive generation of semantic speech tokens with flow-matching for acoustic tokens. These tokens are encoded and decoded with Voxtral Codec, a speech tokenizer trained from scratch with a hybrid VQ-FSQ quantization scheme. In human evaluations conducted by native speakers, Voxtral TTS is preferred for multilingual voice cloning due to its naturalness and expressivity, achieving a 68.4\% win rate over ElevenLabs Flash v2.5. We release the model weights under a CC BY-NC license.
COMBAT: Conditional World Models for Behavioral Agent Training
Feb 28, 2026Recent advances in video generation have spurred the development of world models capable of simulating 3D-consistent environments and interactions with static objects. However, a significant limitation remains in their ability to model dynamic, reactive agents that can intelligently influence and interact with the world. To address this gap, we introduce COMBAT, a real-time, action-controlled world model trained on the complex 1v1 fighting game Tekken 3. Our work demonstrates that diffusion models can successfully simulate a dynamic opponent that reacts to player actions, learning its behavior implicitly. Our approach utilizes a 1.2 billion parameter Diffusion Transformer, conditioned on latent representations from a deep compression autoencoder. We employ state-of-the-art techniques, including causal distillation and diffusion forcing, to achieve real-time inference. Crucially, we observe the emergence of sophisticated agent behavior by training the model solely on single-player inputs, without any explicit supervision for the opponent's policy. Unlike traditional imitation learning methods, which require complete action labels, COMBAT learns effectively from partially observed data to generate responsive behaviors for a controllable Player 1. We present an extensive study and introduce novel evaluation methods to benchmark this emergent agent behavior, establishing a strong foundation for training interactive agents within diffusion-based world models.
Voxtral Realtime
Feb 11, 2026We introduce Voxtral Realtime, a natively streaming automatic speech recognition model that matches offline transcription quality at sub-second latency. Unlike approaches that adapt offline models through chunking or sliding windows, Voxtral Realtime is trained end-to-end for streaming, with explicit alignment between audio and text streams. Our architecture builds on the Delayed Streams Modeling framework, introducing a new causal audio encoder and Ada RMS-Norm for improved delay conditioning. We scale pretraining to a large-scale dataset spanning 13 languages. At a delay of 480ms, Voxtral Realtime achieves performance on par with Whisper, the most widely deployed offline transcription system. We release the model weights under the Apache 2.0 license.
Voxtral
Jul 17, 2025We present Voxtral Mini and Voxtral Small, two multimodal audio chat models. Voxtral is trained to comprehend both spoken audio and text documents, achieving state-of-the-art performance across a diverse range of audio benchmarks, while preserving strong text capabilities. Voxtral Small outperforms a number of closed-source models, while being small enough to run locally. A 32K context window enables the model to handle audio files up to 40 minutes in duration and long multi-turn conversations. We also contribute three benchmarks for evaluating speech understanding models on knowledge and trivia. Both Voxtral models are released under Apache 2.0 license.
Magistral
Jun 12, 2025



We introduce Magistral, Mistral's first reasoning model and our own scalable reinforcement learning (RL) pipeline. Instead of relying on existing implementations and RL traces distilled from prior models, we follow a ground up approach, relying solely on our own models and infrastructure. Notably, we demonstrate a stack that enabled us to explore the limits of pure RL training of LLMs, present a simple method to force the reasoning language of the model, and show that RL on text data alone maintains most of the initial checkpoint's capabilities. We find that RL on text maintains or improves multimodal understanding, instruction following and function calling. We present Magistral Medium, trained for reasoning on top of Mistral Medium 3 with RL alone, and we open-source Magistral Small (Apache 2.0) which further includes cold-start data from Magistral Medium.
Metron: Holistic Performance Evaluation Framework for LLM Inference Systems
Jul 09, 2024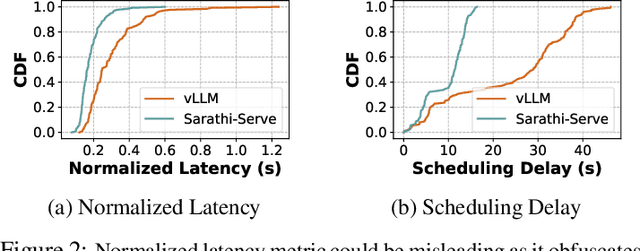
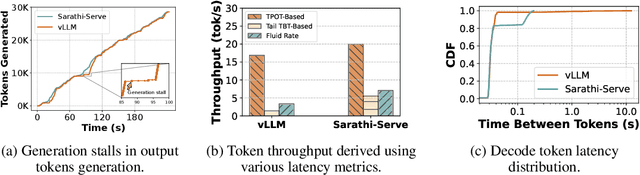
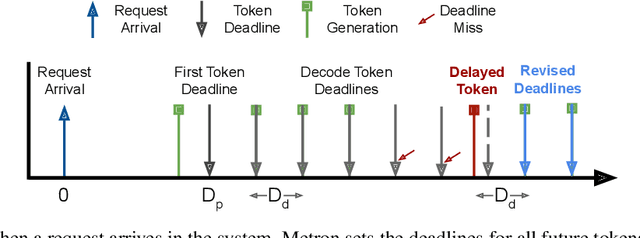
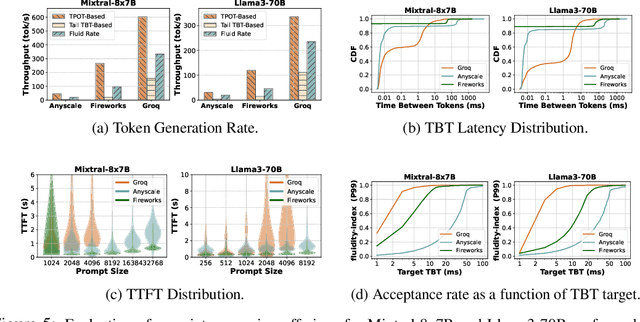
Serving large language models (LLMs) in production can incur substantial costs, which has prompted recent advances in inference system optimizations. Today, these systems are evaluated against conventional latency and throughput metrics (eg. TTFT, TBT, Normalised Latency and TPOT). However, these metrics fail to fully capture the nuances of LLM inference, leading to an incomplete assessment of user-facing performance crucial for real-time applications such as chat and translation. In this paper, we first identify the pitfalls of current performance metrics in evaluating LLM inference systems. We then propose Metron, a comprehensive performance evaluation framework that includes fluidity-index -- a novel metric designed to reflect the intricacies of the LLM inference process and its impact on real-time user experience. Finally, we evaluate various existing open-source platforms and model-as-a-service offerings using Metron, discussing their strengths and weaknesses. Metron is available at https://github.com/project-metron/metron.
Class-Level Code Generation from Natural Language Using Iterative, Tool-Enhanced Reasoning over Repository
Apr 22, 2024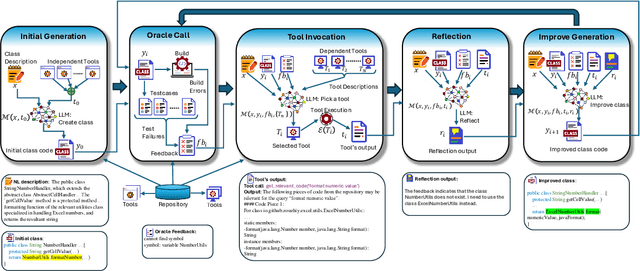
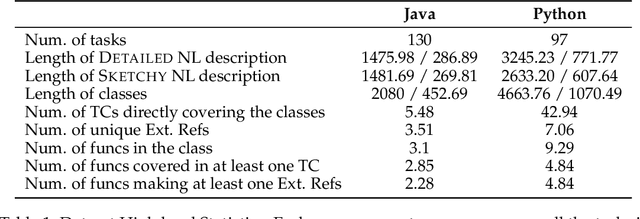
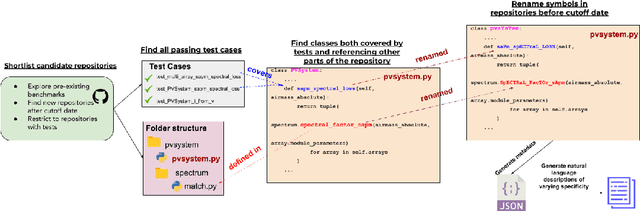

LLMs have demonstrated significant potential in code generation tasks, achieving promising results at the function or statement level in various benchmarks. However, the complexities associated with creating code artifacts like classes, particularly within the context of real-world software repositories, remain underexplored. Existing research often treats class-level generation as an isolated task, neglecting the intricate dependencies and interactions that characterize real-world software development environments. To address this gap, we introduce RepoClassBench, a benchmark designed to rigorously evaluate LLMs in generating complex, class-level code within real-world repositories. RepoClassBench includes natural language to class generation tasks across Java and Python, from a selection of public repositories. We ensure that each class in our dataset not only has cross-file dependencies within the repository but also includes corresponding test cases to verify its functionality. We find that current models struggle with the realistic challenges posed by our benchmark, primarily due to their limited exposure to relevant repository contexts. To address this shortcoming, we introduce Retrieve-Repotools-Reflect (RRR), a novel approach that equips LLMs with static analysis tools to iteratively navigate & reason about repository-level context in an agent-based framework. Our experiments demonstrate that RRR significantly outperforms existing baselines on RepoClassBench, showcasing its effectiveness across programming languages and in various settings. Our findings emphasize the need for benchmarks that incorporate repository-level dependencies to more accurately reflect the complexities of software development. Our work illustrates the benefits of leveraging specialized tools to enhance LLMs understanding of repository context. We plan to make our dataset and evaluation harness public.
ChaTA: Towards an Intelligent Question-Answer Teaching Assistant using Open-Source LLMs
Nov 13, 2023Responding to the thousands of student questions on online QA platforms each semester has a considerable human cost, particularly in computing courses with rapidly growing enrollments. To address the challenges of scalable and intelligent question-answering (QA), we introduce an innovative solution that leverages open-source Large Language Models (LLMs) from the LLaMA-2 family to ensure data privacy. Our approach combines augmentation techniques such as retrieval augmented generation (RAG), supervised fine-tuning (SFT), and learning from human preferences data using Direct Preference Optimization (DPO). Through extensive experimentation on a Piazza dataset from an introductory CS course, comprising 10,000 QA pairs and 1,500 pairs of preference data, we demonstrate a significant 30% improvement in the quality of answers, with RAG being a particularly impactful addition. Our contributions include the development of a novel architecture for educational QA, extensive evaluations of LLM performance utilizing both human assessments and LLM-based metrics, and insights into the challenges and future directions of educational data processing. This work paves the way for the development of CHATA, an intelligent QA assistant customizable for courses with an online QA platform
* Updates for camera-ready submission
Towards Effective Paraphrasing for Information Disguise
Nov 08, 2023Information Disguise (ID), a part of computational ethics in Natural Language Processing (NLP), is concerned with best practices of textual paraphrasing to prevent the non-consensual use of authors' posts on the Internet. Research on ID becomes important when authors' written online communication pertains to sensitive domains, e.g., mental health. Over time, researchers have utilized AI-based automated word spinners (e.g., SpinRewriter, WordAI) for paraphrasing content. However, these tools fail to satisfy the purpose of ID as their paraphrased content still leads to the source when queried on search engines. There is limited prior work on judging the effectiveness of paraphrasing methods for ID on search engines or their proxies, neural retriever (NeurIR) models. We propose a framework where, for a given sentence from an author's post, we perform iterative perturbation on the sentence in the direction of paraphrasing with an attempt to confuse the search mechanism of a NeurIR system when the sentence is queried on it. Our experiments involve the subreddit 'r/AmItheAsshole' as the source of public content and Dense Passage Retriever as a NeurIR system-based proxy for search engines. Our work introduces a novel method of phrase-importance rankings using perplexity scores and involves multi-level phrase substitutions via beam search. Our multi-phrase substitution scheme succeeds in disguising sentences 82% of the time and hence takes an essential step towards enabling researchers to disguise sensitive content effectively before making it public. We also release the code of our approach.
* Accepted at ECIR 2023
Instance-Level Semantic Maps for Vision Language Navigation
May 23, 2023



Humans have a natural ability to perform semantic associations with the surrounding objects in the environment. This allows them to create a mental map of the environment which helps them to navigate on-demand when given a linguistic instruction. A natural goal in Vision Language Navigation (VLN) research is to impart autonomous agents with similar capabilities. Recently introduced VL Maps \cite{huang23vlmaps} take a step towards this goal by creating a semantic spatial map representation of the environment without any labelled data. However, their representations are limited for practical applicability as they do not distinguish between different instances of the same object. In this work, we address this limitation by integrating instance-level information into spatial map representation using a community detection algorithm and by utilizing word ontology learned by large language models (LLMs) to perform open-set semantic associations in the mapping representation. The resulting map representation improves the navigation performance by two-fold (233\%) on realistic language commands with instance-specific descriptions compared to VL Maps. We validate the practicality and effectiveness of our approach through extensive qualitative and quantitative experiments.