 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMinistral 3
Jan 13, 2026We introduce the Ministral 3 series, a family of parameter-efficient dense language models designed for compute and memory constrained applications, available in three model sizes: 3B, 8B, and 14B parameters. For each model size, we release three variants: a pretrained base model for general-purpose use, an instruction finetuned, and a reasoning model for complex problem-solving. In addition, we present our recipe to derive the Ministral 3 models through Cascade Distillation, an iterative pruning and continued training with distillation technique. Each model comes with image understanding capabilities, all under the Apache 2.0 license.
Voxtral
Jul 17, 2025We present Voxtral Mini and Voxtral Small, two multimodal audio chat models. Voxtral is trained to comprehend both spoken audio and text documents, achieving state-of-the-art performance across a diverse range of audio benchmarks, while preserving strong text capabilities. Voxtral Small outperforms a number of closed-source models, while being small enough to run locally. A 32K context window enables the model to handle audio files up to 40 minutes in duration and long multi-turn conversations. We also contribute three benchmarks for evaluating speech understanding models on knowledge and trivia. Both Voxtral models are released under Apache 2.0 license.
Magistral
Jun 12, 2025



We introduce Magistral, Mistral's first reasoning model and our own scalable reinforcement learning (RL) pipeline. Instead of relying on existing implementations and RL traces distilled from prior models, we follow a ground up approach, relying solely on our own models and infrastructure. Notably, we demonstrate a stack that enabled us to explore the limits of pure RL training of LLMs, present a simple method to force the reasoning language of the model, and show that RL on text data alone maintains most of the initial checkpoint's capabilities. We find that RL on text maintains or improves multimodal understanding, instruction following and function calling. We present Magistral Medium, trained for reasoning on top of Mistral Medium 3 with RL alone, and we open-source Magistral Small (Apache 2.0) which further includes cold-start data from Magistral Medium.
MoDE: Effective Multi-task Parameter Efficient Fine-Tuning with a Mixture of Dyadic Experts
Aug 02, 2024Parameter-efficient fine-tuning techniques like Low-Rank Adaptation (LoRA) have revolutionized the adaptation of large language models (LLMs) to diverse tasks. Recent efforts have explored mixtures of LoRA modules for multi-task settings. However, our analysis reveals redundancy in the down-projection matrices of these architectures. This observation motivates our proposed method, Mixture of Dyadic Experts (MoDE), which introduces a novel design for efficient multi-task adaptation. This is done by sharing the down-projection matrix across tasks and employing atomic rank-one adapters, coupled with routers that allow more sophisticated task-level specialization. Our design allows for more fine-grained mixing, thereby increasing the model's ability to jointly handle multiple tasks. We evaluate MoDE on the Supernatural Instructions (SNI) benchmark consisting of a diverse set of 700+ tasks and demonstrate that it outperforms state-of-the-art multi-task parameter-efficient fine-tuning (PEFT) methods, without introducing additional parameters. Our findings contribute to a deeper understanding of parameter efficiency in multi-task LLM adaptation and provide a practical solution for deploying high-performing, lightweight models.
Improve Mathematical Reasoning in Language Models by Automated Process Supervision
Jun 05, 2024

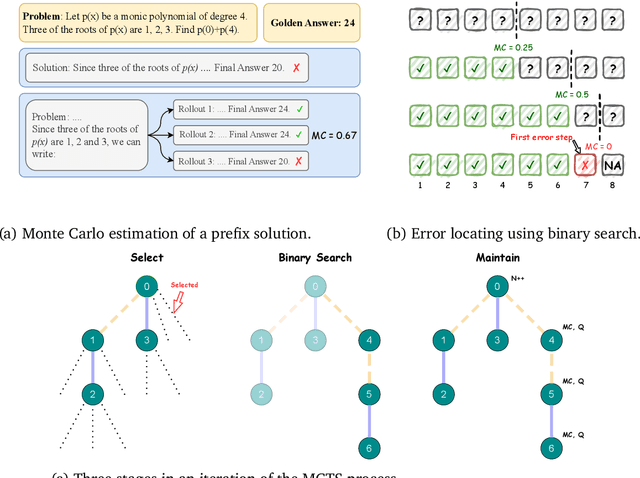
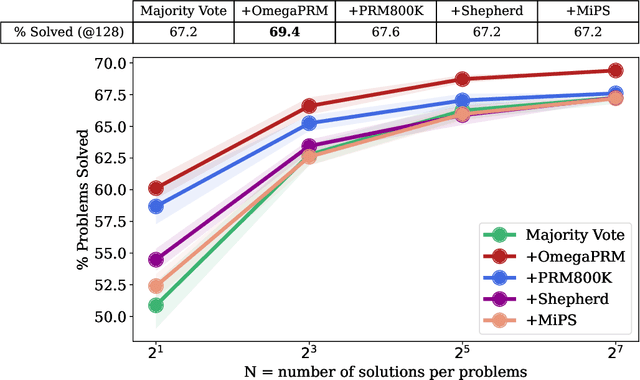
Complex multi-step reasoning tasks, such as solving mathematical problems or generating code, remain a significant hurdle for even the most advanced large language models (LLMs). Verifying LLM outputs with an Outcome Reward Model (ORM) is a standard inference-time technique aimed at enhancing the reasoning performance of LLMs. However, this still proves insufficient for reasoning tasks with a lengthy or multi-hop reasoning chain, where the intermediate outcomes are neither properly rewarded nor penalized. Process supervision addresses this limitation by assigning intermediate rewards during the reasoning process. To date, the methods used to collect process supervision data have relied on either human annotation or per-step Monte Carlo estimation, both prohibitively expensive to scale, thus hindering the broad application of this technique. In response to this challenge, we propose a novel divide-and-conquer style Monte Carlo Tree Search (MCTS) algorithm named \textit{OmegaPRM} for the efficient collection of high-quality process supervision data. This algorithm swiftly identifies the first error in the Chain of Thought (CoT) with binary search and balances the positive and negative examples, thereby ensuring both efficiency and quality. As a result, we are able to collect over 1.5 million process supervision annotations to train a Process Reward Model (PRM). Utilizing this fully automated process supervision alongside the weighted self-consistency algorithm, we have enhanced the instruction tuned Gemini Pro model's math reasoning performance, achieving a 69.4\% success rate on the MATH benchmark, a 36\% relative improvement from the 51\% base model performance. Additionally, the entire process operates without any human intervention, making our method both financially and computationally cost-effective compared to existing methods.
PERL: Parameter Efficient Reinforcement Learning from Human Feedback
Mar 15, 2024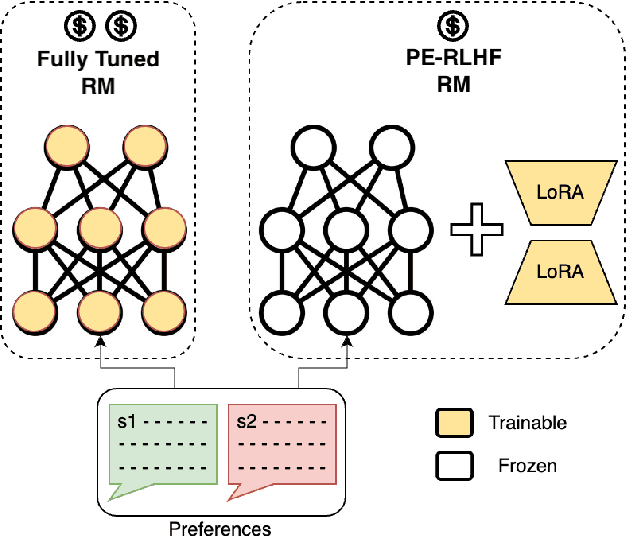
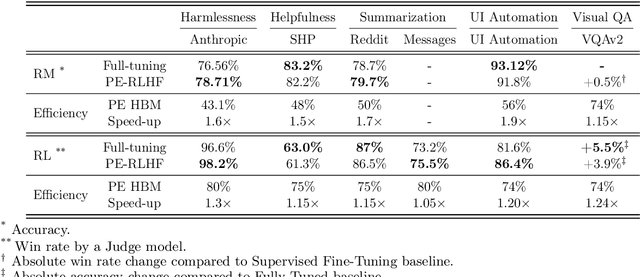
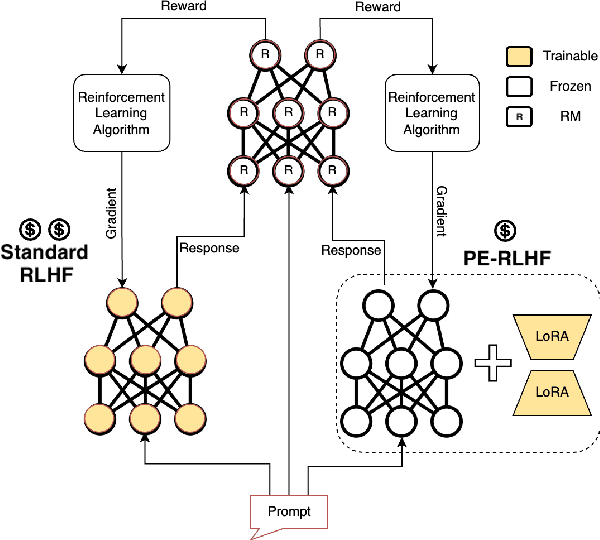
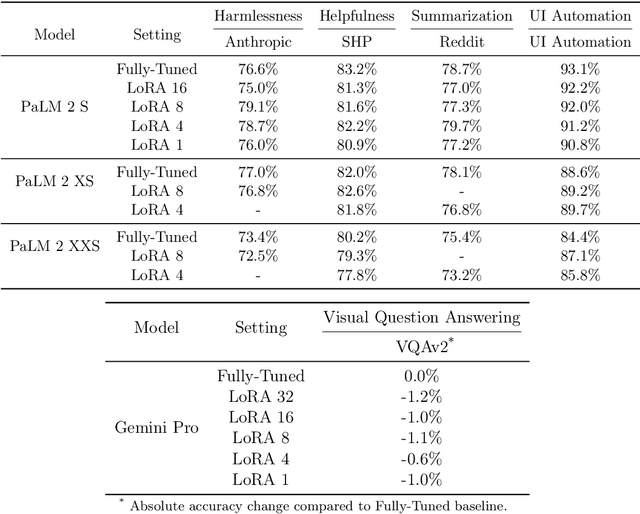
Reinforcement Learning from Human Feedback (RLHF) has proven to be a strong method to align Pretrained Large Language Models (LLMs) with human preferences. But training models with RLHF is computationally expensive, and an overall complex process. In this work, we study RLHF where the underlying models are trained using the parameter efficient method of Low-Rank Adaptation (LoRA) introduced by Hu et al. [2021]. We investigate the setup of "Parameter Efficient Reinforcement Learning" (PERL), in which we perform reward model training and reinforcement learning using LoRA. We compare PERL to conventional fine-tuning (full-tuning) across various configurations for 7 benchmarks, including 2 novel datasets, of reward modeling and reinforcement learning. We find that PERL performs on par with the conventional RLHF setting, while training faster, and with less memory. This enables the high performance of RLHF, while reducing the computational burden that limits its adoption as an alignment technique for Large Language Models. We also release 2 novel thumbs up/down preference datasets: "Taskmaster Coffee", and "Taskmaster Ticketing" to promote research around RLHF.
RLAIF: Scaling Reinforcement Learning from Human Feedback with AI Feedback
Sep 01, 2023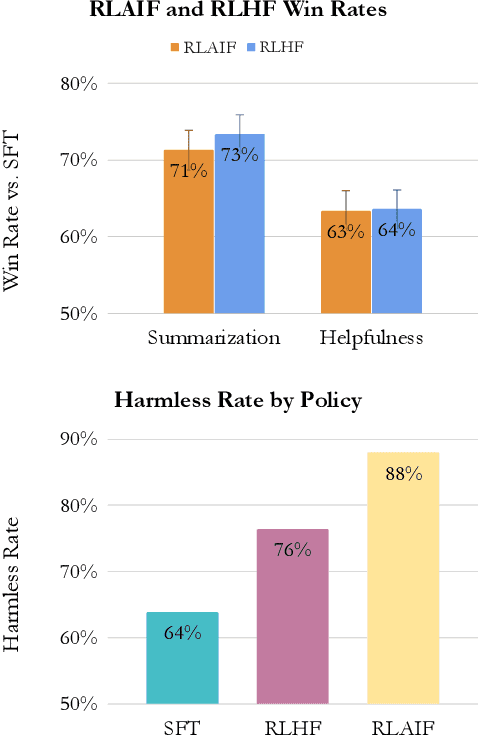
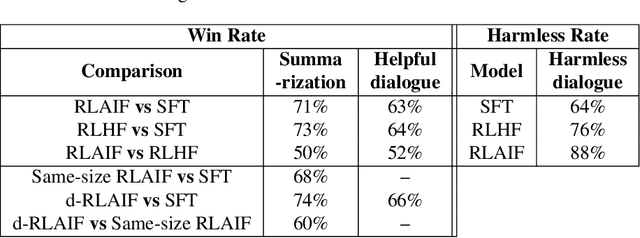
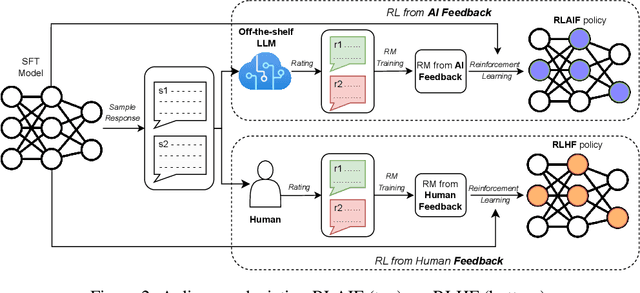

Reinforcement learning from human feedback (RLHF) is effective at aligning large language models (LLMs) to human preferences, but gathering high quality human preference labels is a key bottleneck. We conduct a head-to-head comparison of RLHF vs. RL from AI Feedback (RLAIF) - a technique where preferences are labeled by an off-the-shelf LLM in lieu of humans, and we find that they result in similar improvements. On the task of summarization, human evaluators prefer generations from both RLAIF and RLHF over a baseline supervised fine-tuned model in ~70% of cases. Furthermore, when asked to rate RLAIF vs. RLHF summaries, humans prefer both at equal rates. These results suggest that RLAIF can yield human-level performance, offering a potential solution to the scalability limitations of RLHF.
Conversational Recommendation as Retrieval: A Simple, Strong Baseline
May 23, 2023Conversational recommendation systems (CRS) aim to recommend suitable items to users through natural language conversation. However, most CRS approaches do not effectively utilize the signal provided by these conversations. They rely heavily on explicit external knowledge e.g., knowledge graphs to augment the models' understanding of the items and attributes, which is quite hard to scale. To alleviate this, we propose an alternative information retrieval (IR)-styled approach to the CRS item recommendation task, where we represent conversations as queries and items as documents to be retrieved. We expand the document representation used for retrieval with conversations from the training set. With a simple BM25-based retriever, we show that our task formulation compares favorably with much more complex baselines using complex external knowledge on a popular CRS benchmark. We demonstrate further improvements using user-centric modeling and data augmentation to counter the cold start problem for CRSs.
AnyTOD: A Programmable Task-Oriented Dialog System
Dec 20, 2022
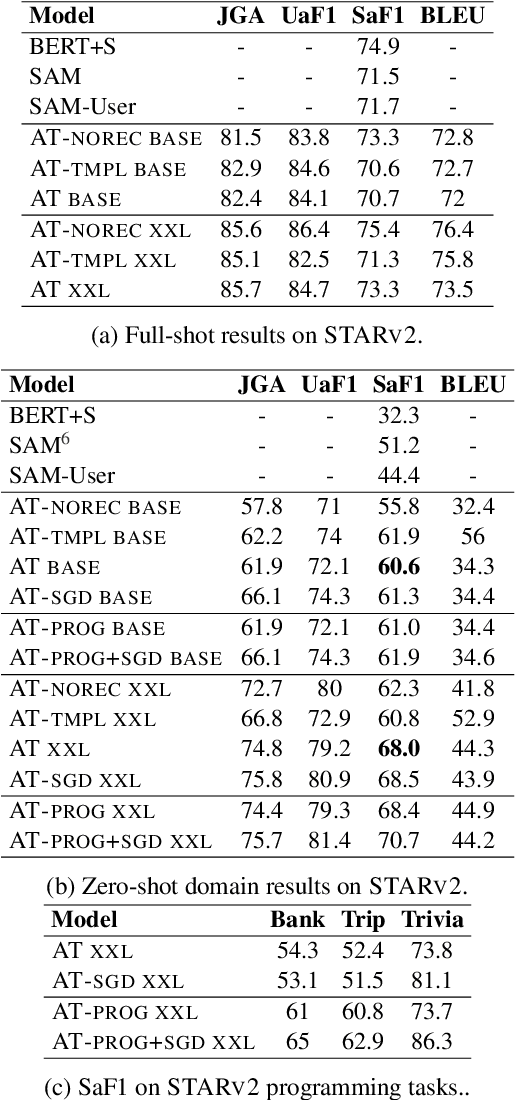
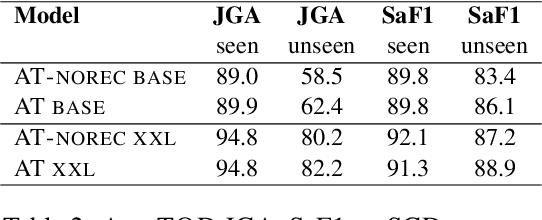

We propose AnyTOD, an end-to-end task-oriented dialog (TOD) system with zero-shot capability for unseen tasks. We view TOD as a program executed by a language model (LM), where program logic and ontology is provided by a designer in the form of a schema. To enable generalization onto unseen schemas and programs without prior training, AnyTOD adopts a neuro-symbolic approach. A neural LM keeps track of events that occur during a conversation, and a symbolic program implementing the dialog policy is executed to recommend next actions AnyTOD should take. This approach drastically reduces data annotation and model training requirements, addressing a long-standing challenge in TOD research: rapidly adapting a TOD system to unseen tasks and domains. We demonstrate state-of-the-art results on the STAR and ABCD benchmarks, as well as AnyTOD's strong zero-shot transfer capability in low-resource settings. In addition, we release STARv2, an updated version of the STAR dataset with richer data annotations, for benchmarking zero-shot end-to-end TOD models.
Speech Aware Dialog System Technology Challenge (DSTC11)
Dec 16, 2022



Most research on task oriented dialog modeling is based on written text input. However, users interact with practical dialog systems often using speech as input. Typically, systems convert speech into text using an Automatic Speech Recognition (ASR) system, introducing errors. Furthermore, these systems do not address the differences in written and spoken language. The research on this topic is stymied by the lack of a public corpus. Motivated by these considerations, our goal in hosting the speech-aware dialog state tracking challenge was to create a public corpus or task which can be used to investigate the performance gap between the written and spoken forms of input, develop models that could alleviate this gap, and establish whether Text-to-Speech-based (TTS) systems is a reasonable surrogate to the more-labor intensive human data collection. We created three spoken versions of the popular written-domain MultiWoz task -- (a) TTS-Verbatim: written user inputs were converted into speech waveforms using a TTS system, (b) Human-Verbatim: humans spoke the user inputs verbatim, and (c) Human-paraphrased: humans paraphrased the user inputs. Additionally, we provided different forms of ASR output to encourage wider participation from teams that may not have access to state-of-the-art ASR systems. These included ASR transcripts, word time stamps, and latent representations of the audio (audio encoder outputs). In this paper, we describe the corpus, report results from participating teams, provide preliminary analyses of their results, and summarize the current state-of-the-art in this domain.