 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePERL: Parameter Efficient Reinforcement Learning from Human Feedback
Mar 15, 2024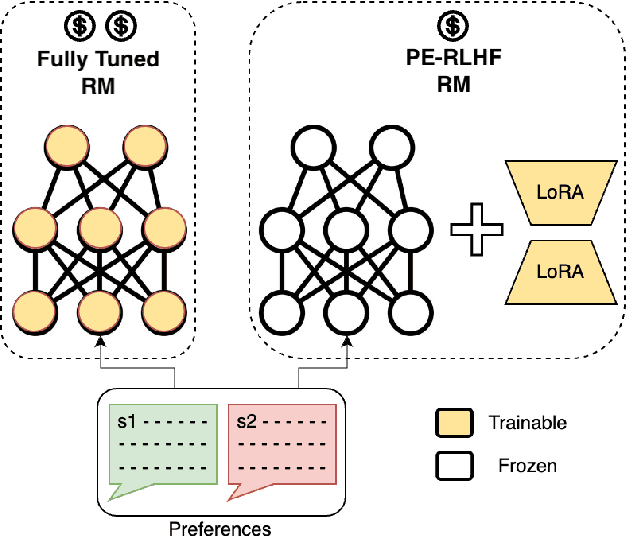
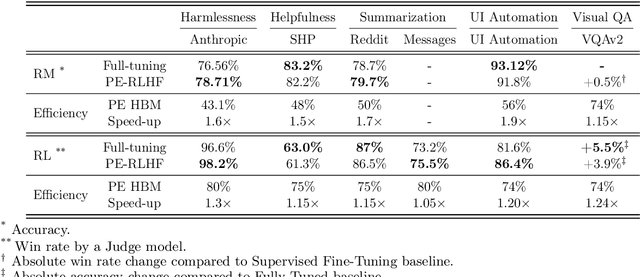
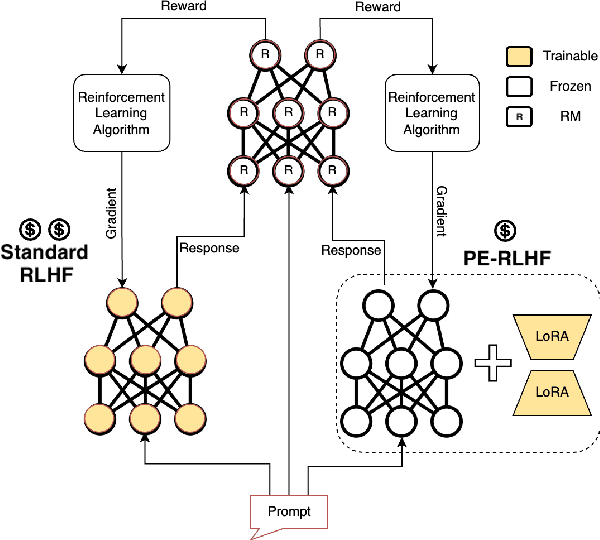
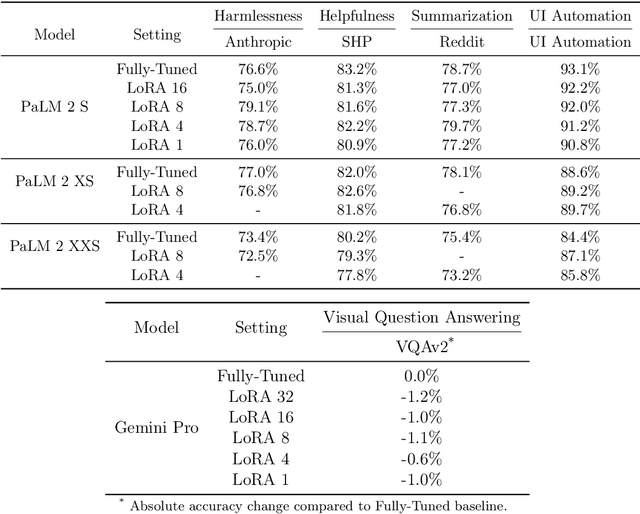
Reinforcement Learning from Human Feedback (RLHF) has proven to be a strong method to align Pretrained Large Language Models (LLMs) with human preferences. But training models with RLHF is computationally expensive, and an overall complex process. In this work, we study RLHF where the underlying models are trained using the parameter efficient method of Low-Rank Adaptation (LoRA) introduced by Hu et al. [2021]. We investigate the setup of "Parameter Efficient Reinforcement Learning" (PERL), in which we perform reward model training and reinforcement learning using LoRA. We compare PERL to conventional fine-tuning (full-tuning) across various configurations for 7 benchmarks, including 2 novel datasets, of reward modeling and reinforcement learning. We find that PERL performs on par with the conventional RLHF setting, while training faster, and with less memory. This enables the high performance of RLHF, while reducing the computational burden that limits its adoption as an alignment technique for Large Language Models. We also release 2 novel thumbs up/down preference datasets: "Taskmaster Coffee", and "Taskmaster Ticketing" to promote research around RLHF.
Conversational Recommendation as Retrieval: A Simple, Strong Baseline
May 23, 2023Conversational recommendation systems (CRS) aim to recommend suitable items to users through natural language conversation. However, most CRS approaches do not effectively utilize the signal provided by these conversations. They rely heavily on explicit external knowledge e.g., knowledge graphs to augment the models' understanding of the items and attributes, which is quite hard to scale. To alleviate this, we propose an alternative information retrieval (IR)-styled approach to the CRS item recommendation task, where we represent conversations as queries and items as documents to be retrieved. We expand the document representation used for retrieval with conversations from the training set. With a simple BM25-based retriever, we show that our task formulation compares favorably with much more complex baselines using complex external knowledge on a popular CRS benchmark. We demonstrate further improvements using user-centric modeling and data augmentation to counter the cold start problem for CRSs.