 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArchAgent: Agentic AI-driven Computer Architecture Discovery
Feb 25, 2026Agile hardware design flows are a critically needed force multiplier to meet the exploding demand for compute. Recently, agentic generative AI systems have demonstrated significant advances in algorithm design, improving code efficiency, and enabling discovery across scientific domains. Bridging these worlds, we present ArchAgent, an automated computer architecture discovery system built on AlphaEvolve. We show ArchAgent's ability to automatically design/implement state-of-the-art (SoTA) cache replacement policies (architecting new mechanisms/logic, not only changing parameters), broadly within the confines of an established cache replacement policy design competition. In two days without human intervention, ArchAgent generated a policy achieving a 5.3% IPC speedup improvement over the prior SoTA on public multi-core Google Workload Traces. On the heavily-explored single-core SPEC06 workloads, it generated a policy in just 18 days showing a 0.9% IPC speedup improvement over the existing SoTA (a similar "winning margin" as reported by the existing SoTA). ArchAgent achieved these gains 3-5x faster than prior human-developed SoTA policies. Agentic flows also enable "post-silicon hyperspecialization" where agents tune runtime-configurable parameters exposed in hardware policies to further align the policies with a specific workload (mix). Exploiting this, we demonstrate a 2.4% IPC speedup improvement over prior SoTA on SPEC06 workloads. Finally, we outline broader implications for computer architecture research in the era of agentic AI. For example, we demonstrate the phenomenon of "simulator escapes", where the agentic AI flow discovered and exploited a loophole in a popular microarchitectural simulator - a consequence of the fact that these research tools were designed for a (now past) world where they were exclusively operated by humans acting in good-faith.
Conditioned Language Policy: A General Framework for Steerable Multi-Objective Finetuning
Jul 22, 2024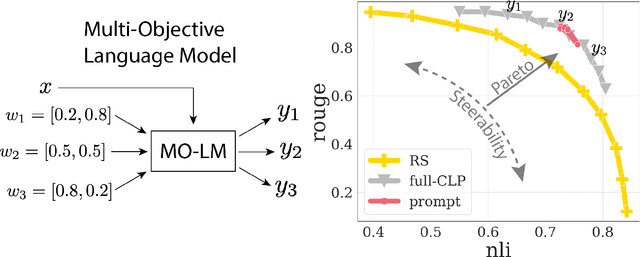
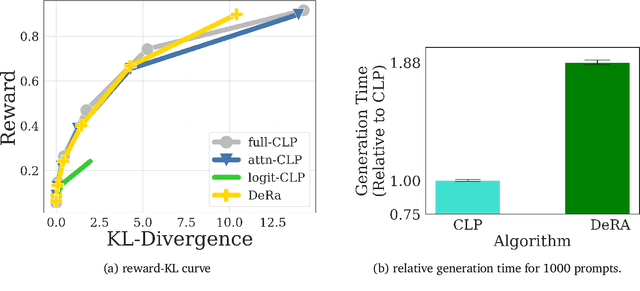
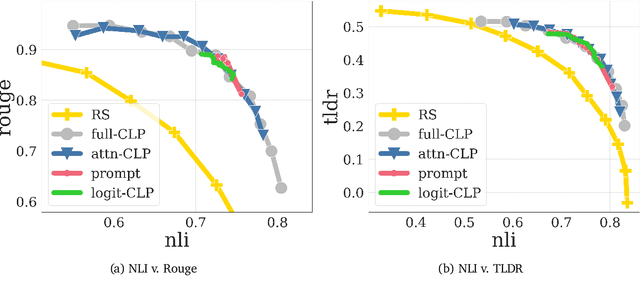
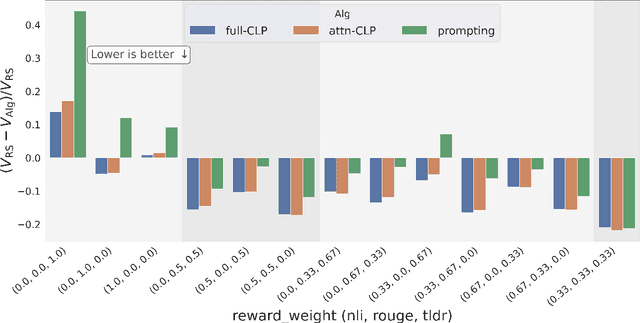
Reward-based finetuning is crucial for aligning language policies with intended behaviors (e.g., creativity and safety). A key challenge here is to develop steerable language models that trade-off multiple (conflicting) objectives in a flexible and efficient manner. This paper presents Conditioned Language Policy (CLP), a general framework for finetuning language models on multiple objectives. Building on techniques from multi-task training and parameter-efficient finetuning, CLP can learn steerable models that effectively trade-off conflicting objectives at inference time. Notably, this does not require training or maintaining multiple models to achieve different trade-offs between the objectives. Through an extensive set of experiments and ablations, we show that the CLP framework learns steerable models that outperform and Pareto-dominate the current state-of-the-art approaches for multi-objective finetuning.
Introducing Super RAGs in Mistral 8x7B-v1
Apr 13, 2024The relentless pursuit of enhancing Large Language Models (LLMs) has led to the advent of Super Retrieval-Augmented Generation (Super RAGs), a novel approach designed to elevate the performance of LLMs by integrating external knowledge sources with minimal structural modifications. This paper presents the integration of Super RAGs into the Mistral 8x7B v1, a state-of-the-art LLM, and examines the resultant improvements in accuracy, speed, and user satisfaction. Our methodology uses a fine-tuned instruct model setup and a cache tuning fork system, ensuring efficient and relevant data retrieval. The evaluation, conducted over several epochs, demonstrates significant enhancements across all metrics. The findings suggest that Super RAGs can effectively augment LLMs, paving the way for more sophisticated and reliable AI systems. This research contributes to the field by providing empirical evidence of the benefits of Super RAGs and offering insights into their potential applications.
Conversational Recommendation as Retrieval: A Simple, Strong Baseline
May 23, 2023Conversational recommendation systems (CRS) aim to recommend suitable items to users through natural language conversation. However, most CRS approaches do not effectively utilize the signal provided by these conversations. They rely heavily on explicit external knowledge e.g., knowledge graphs to augment the models' understanding of the items and attributes, which is quite hard to scale. To alleviate this, we propose an alternative information retrieval (IR)-styled approach to the CRS item recommendation task, where we represent conversations as queries and items as documents to be retrieved. We expand the document representation used for retrieval with conversations from the training set. With a simple BM25-based retriever, we show that our task formulation compares favorably with much more complex baselines using complex external knowledge on a popular CRS benchmark. We demonstrate further improvements using user-centric modeling and data augmentation to counter the cold start problem for CRSs.
AnyTOD: A Programmable Task-Oriented Dialog System
Dec 20, 2022
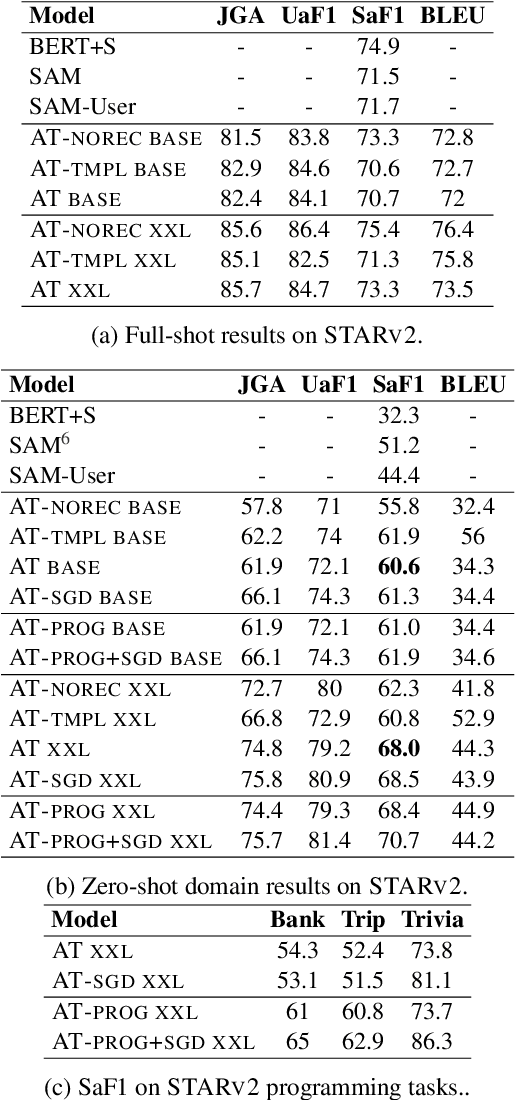
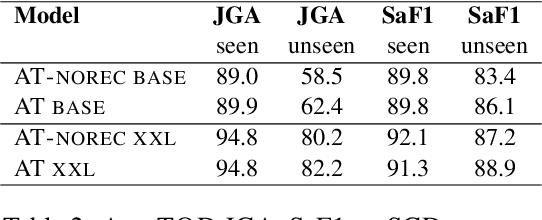

We propose AnyTOD, an end-to-end task-oriented dialog (TOD) system with zero-shot capability for unseen tasks. We view TOD as a program executed by a language model (LM), where program logic and ontology is provided by a designer in the form of a schema. To enable generalization onto unseen schemas and programs without prior training, AnyTOD adopts a neuro-symbolic approach. A neural LM keeps track of events that occur during a conversation, and a symbolic program implementing the dialog policy is executed to recommend next actions AnyTOD should take. This approach drastically reduces data annotation and model training requirements, addressing a long-standing challenge in TOD research: rapidly adapting a TOD system to unseen tasks and domains. We demonstrate state-of-the-art results on the STAR and ABCD benchmarks, as well as AnyTOD's strong zero-shot transfer capability in low-resource settings. In addition, we release STARv2, an updated version of the STAR dataset with richer data annotations, for benchmarking zero-shot end-to-end TOD models.
Show, Don't Tell: Demonstrations Outperform Descriptions for Schema-Guided Task-Oriented Dialogue
Apr 08, 2022
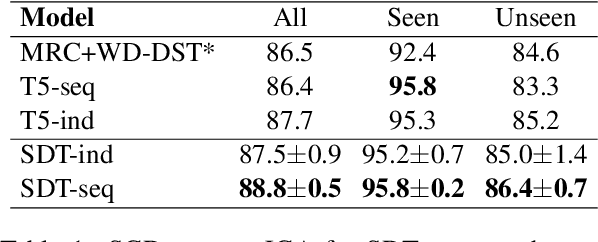
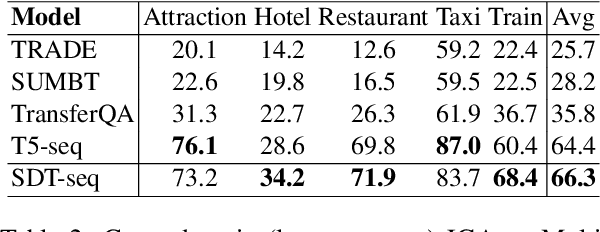

Building universal dialogue systems that can seamlessly operate across multiple domains/APIs and generalize to new ones with minimal supervision and maintenance is a critical challenge. Recent works have leveraged natural language descriptions for schema elements to enable such systems; however, descriptions can only indirectly convey schema semantics. In this work, we propose Show, Don't Tell, a prompt format for seq2seq modeling which uses a short labeled example dialogue to show the semantics of schema elements rather than tell the model via descriptions. While requiring similar effort from service developers, we show that using short examples as schema representations with large language models results in stronger performance and better generalization on two popular dialogue state tracking benchmarks: the Schema-Guided Dialogue dataset and the MultiWoZ leave-one-out benchmark.
Description-Driven Task-Oriented Dialog Modeling
Jan 21, 2022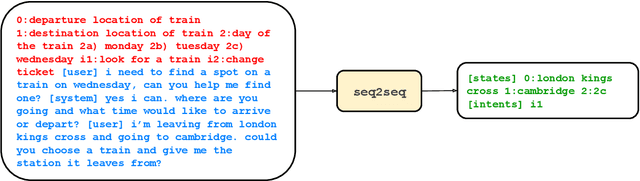

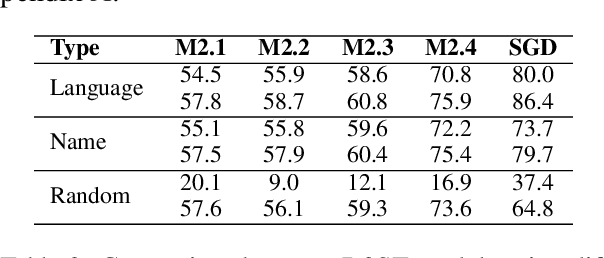

Task-oriented dialogue (TOD) systems are required to identify key information from conversations for the completion of given tasks. Such information is conventionally specified in terms of intents and slots contained in task-specific ontology or schemata. Since these schemata are designed by system developers, the naming convention for slots and intents is not uniform across tasks, and may not convey their semantics effectively. This can lead to models memorizing arbitrary patterns in data, resulting in suboptimal performance and generalization. In this paper, we propose that schemata should be modified by replacing names or notations entirely with natural language descriptions. We show that a language description-driven system exhibits better understanding of task specifications, higher performance on state tracking, improved data efficiency, and effective zero-shot transfer to unseen tasks. Following this paradigm, we present a simple yet effective Description-Driven Dialog State Tracking (D3ST) model, which relies purely on schema descriptions and an "index-picking" mechanism. We demonstrate the superiority in quality, data efficiency and robustness of our approach as measured on the MultiWOZ (Budzianowski et al.,2018), SGD (Rastogi et al., 2020), and the recent SGD-X (Lee et al., 2021) benchmarks.
SGD-X: A Benchmark for Robust Generalization in Schema-Guided Dialogue Systems
Oct 13, 2021
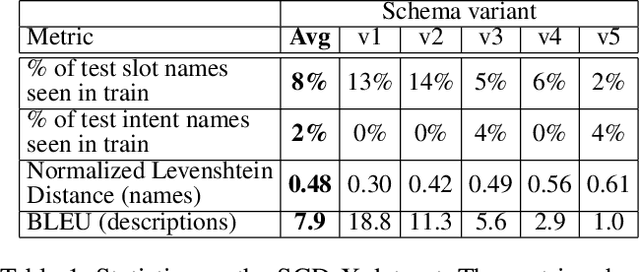
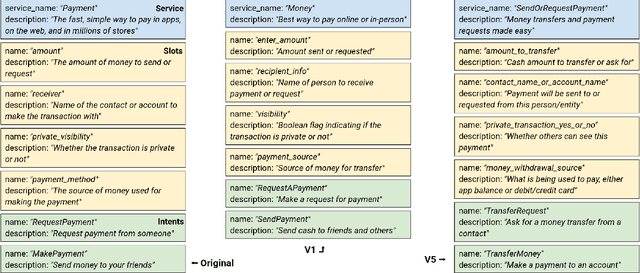
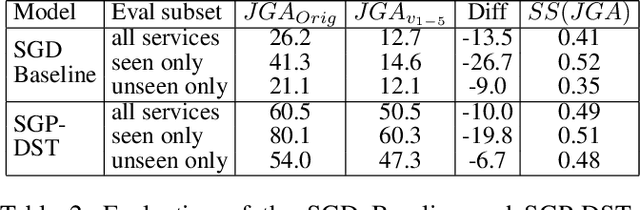
Zero/few-shot transfer to unseen services is a critical challenge in task-oriented dialogue research. The Schema-Guided Dialogue (SGD) dataset introduced a paradigm for enabling models to support an unlimited number of services without additional data collection or re-training through the use of schemas. Schemas describe service APIs in natural language, which models consume to understand the services they need to support. However, the impact of the choice of language in these schemas on model performance remains unexplored. We address this by releasing SGD-X, a benchmark for measuring the robustness of dialogue systems to linguistic variations in schemas. SGD-X extends the SGD dataset with crowdsourced variants for every schema, where variants are semantically similar yet stylistically diverse. We evaluate two dialogue state tracking models on SGD-X and observe that neither generalizes well across schema variations, measured by joint goal accuracy and a novel metric for measuring schema sensitivity. Furthermore, we present a simple model-agnostic data augmentation method to improve schema robustness and zero-shot generalization to unseen services.
Evaluation of deep convolutional neural networks in classifying human embryo images based on their morphological quality
May 21, 2020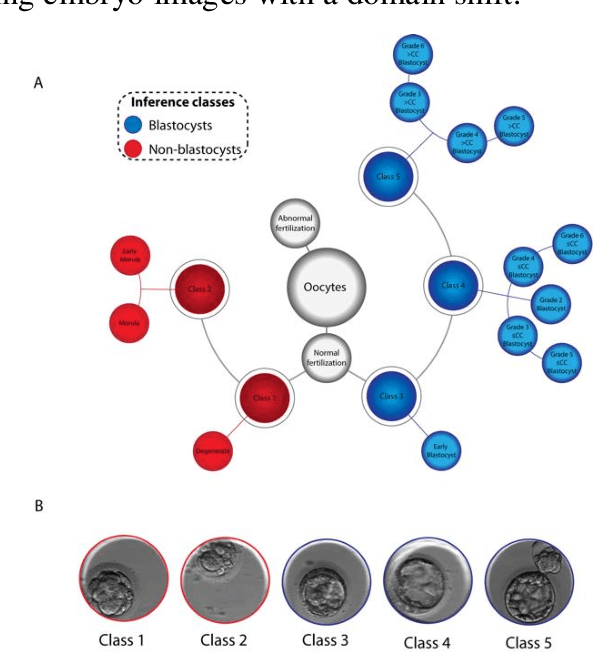
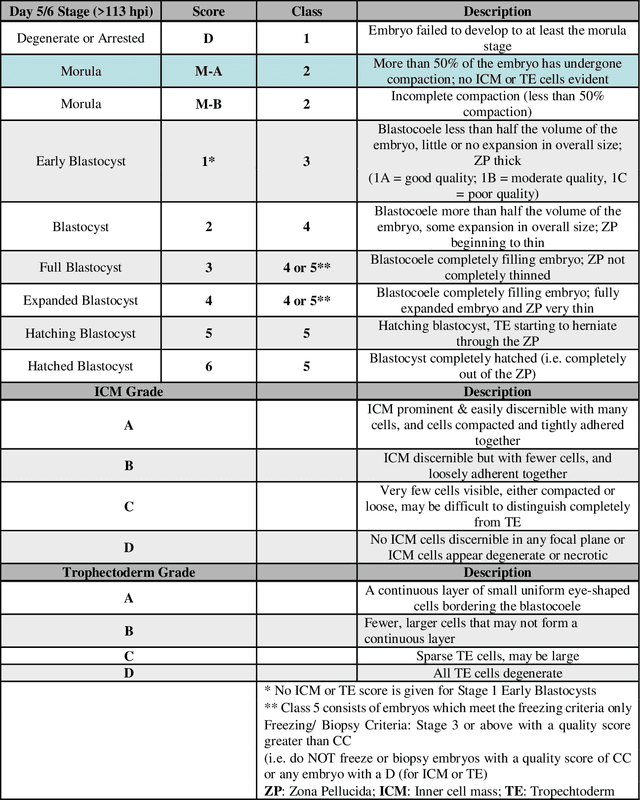

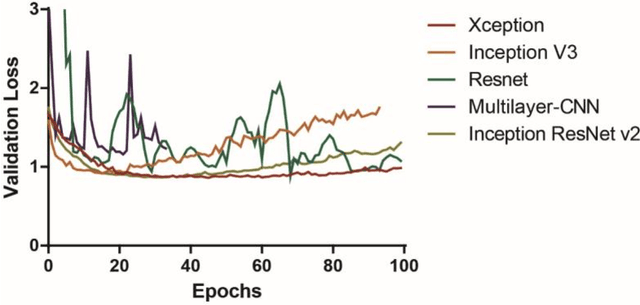
A critical factor that influences the success of an in-vitro fertilization (IVF) procedure is the quality of the transferred embryo. Embryo morphology assessments, conventionally performed through manual microscopic analysis suffer from disparities in practice, selection criteria, and subjectivity due to the experience of the embryologist. Convolutional neural networks (CNNs) are powerful, promising algorithms with significant potential for accurate classifications across many object categories. Network architectures and hyper-parameters affect the efficiency of CNNs for any given task. Here, we evaluate multi-layered CNNs developed from scratch and popular deep-learning architectures such as Inception v3, ResNET, Inception-ResNET-v2, and Xception in differentiating between embryos based on their morphological quality at 113 hours post insemination (hpi). Xception performed the best in differentiating between the embryos based on their morphological quality.
Deep learning mediated single time-point image-based prediction of embryo developmental outcome at the cleavage stage
May 21, 2020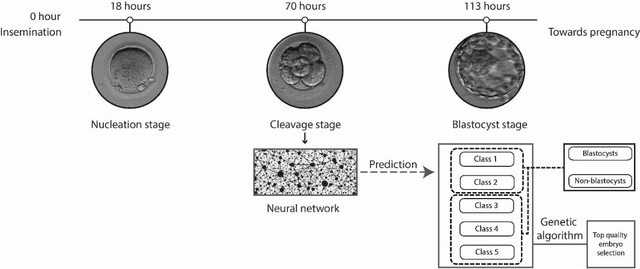
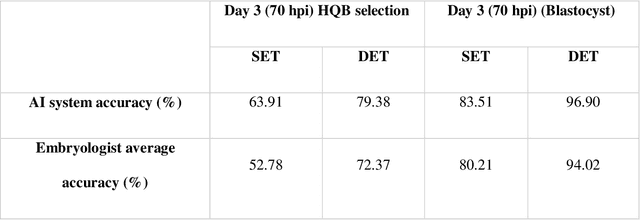
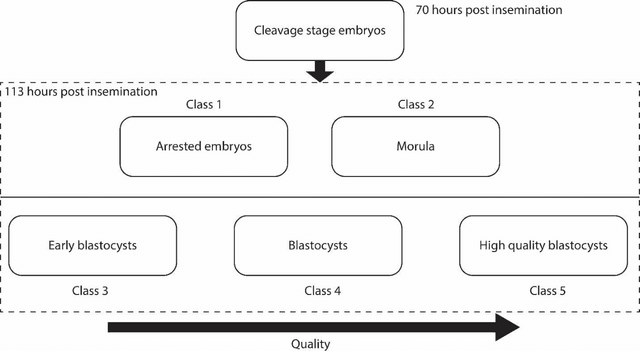
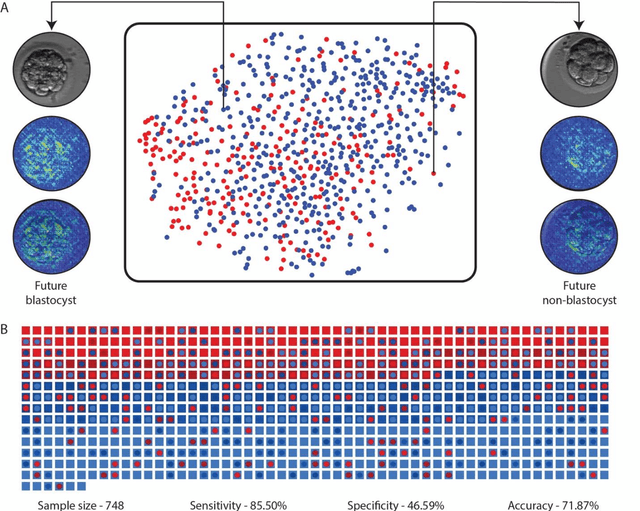
In conventional clinical in-vitro fertilization practices embryos are transferred either at the cleavage or blastocyst stages of development. Cleavage stage transfers, particularly, are beneficial for patients with relatively poor prognosis and at fertility centers in resource-limited settings where there is a higher chance of developmental failure in embryos in-vitro. However, one of the major limitations of embryo selections at the cleavage stage is the availability of very low number of manually discernable features to predict developmental outcomes. Although, time-lapse imaging systems have been proposed as possible solutions, they are cost-prohibitive and require bulky and expensive hardware, and labor-intensive. Advances in convolutional neural networks (CNNs) have been utilized to provide accurate classifications across many medical and non-medical object categories. Here, we report an automated system for classification and selection of human embryos at the cleavage stage using a trained CNN combined with a genetic algorithm. The system selected the cleavage stage embryo at 70 hours post insemination (hpi) that ultimately developed into top-quality blastocyst at 70 hpi with 64% accuracy, outperforming the abilities of embryologists in identifying embryos with the highest developmental potential. Such systems can have a significant impact on IVF procedures by empowering embryologists for accurate and consistent embryo assessment in both resource-poor and resource-rich settings.