 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSGD-X: A Benchmark for Robust Generalization in Schema-Guided Dialogue Systems
Paper and Code

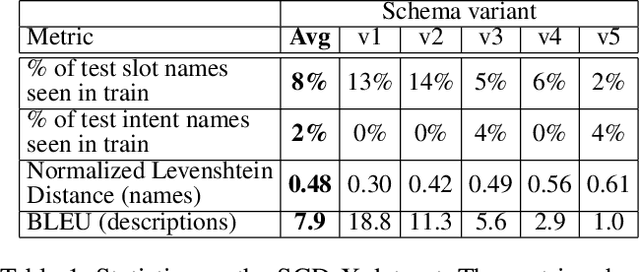
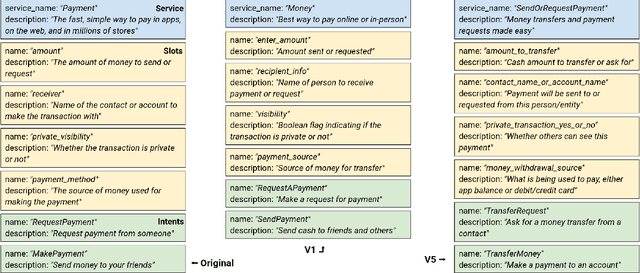
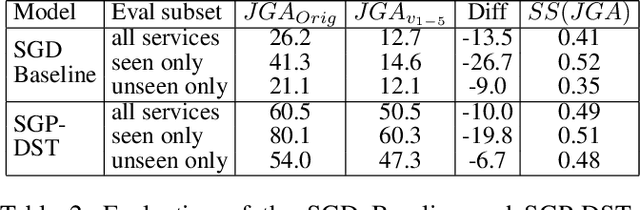
Zero/few-shot transfer to unseen services is a critical challenge in task-oriented dialogue research. The Schema-Guided Dialogue (SGD) dataset introduced a paradigm for enabling models to support an unlimited number of services without additional data collection or re-training through the use of schemas. Schemas describe service APIs in natural language, which models consume to understand the services they need to support. However, the impact of the choice of language in these schemas on model performance remains unexplored. We address this by releasing SGD-X, a benchmark for measuring the robustness of dialogue systems to linguistic variations in schemas. SGD-X extends the SGD dataset with crowdsourced variants for every schema, where variants are semantically similar yet stylistically diverse. We evaluate two dialogue state tracking models on SGD-X and observe that neither generalizes well across schema variations, measured by joint goal accuracy and a novel metric for measuring schema sensitivity. Furthermore, we present a simple model-agnostic data augmentation method to improve schema robustness and zero-shot generalization to unseen services.