 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-Time Human Activity Recognition on Edge Microcontrollers: Dynamic Hierarchical Inference with Multi-Spectral Sensor Fusion
Jan 29, 2026The demand for accurate on-device pattern recognition in edge applications is intensifying, yet existing approaches struggle to reconcile accuracy with computational constraints. To address this challenge, a resource-aware hierarchical network based on multi-spectral fusion and interpretable modules, namely the Hierarchical Parallel Pseudo-image Enhancement Fusion Network (HPPI-Net), is proposed for real-time, on-device Human Activity Recognition (HAR). Deployed on an ARM Cortex-M4 microcontroller for low-power real-time inference, HPPI-Net achieves 96.70% accuracy while utilizing only 22.3 KiB of RAM and 439.5 KiB of ROM after optimization. HPPI-Net employs a two-layer architecture. The first layer extracts preliminary features using Fast Fourier Transform (FFT) spectrograms, while the second layer selectively activates either a dedicated module for stationary activity recognition or a parallel LSTM-MobileNet network (PLMN) for dynamic states. PLMN fuses FFT, Wavelet, and Gabor spectrograms through three parallel LSTM encoders and refines the concatenated features using Efficient Channel Attention (ECA) and Depthwise Separable Convolution (DSC), thereby offering channel-level interpretability while substantially reducing multiply-accumulate operations. Compared with MobileNetV3, HPPI-Net improves accuracy by 1.22% and reduces RAM usage by 71.2% and ROM usage by 42.1%. These results demonstrate that HPPI-Net achieves a favorable accuracy-efficiency trade-off and provides explainable predictions, establishing a practical solution for wearable, industrial, and smart home HAR on memory-constrained edge platforms.
Seedance 1.5 pro: A Native Audio-Visual Joint Generation Foundation Model
Dec 23, 2025Recent strides in video generation have paved the way for unified audio-visual generation. In this work, we present Seedance 1.5 pro, a foundational model engineered specifically for native, joint audio-video generation. Leveraging a dual-branch Diffusion Transformer architecture, the model integrates a cross-modal joint module with a specialized multi-stage data pipeline, achieving exceptional audio-visual synchronization and superior generation quality. To ensure practical utility, we implement meticulous post-training optimizations, including Supervised Fine-Tuning (SFT) on high-quality datasets and Reinforcement Learning from Human Feedback (RLHF) with multi-dimensional reward models. Furthermore, we introduce an acceleration framework that boosts inference speed by over 10X. Seedance 1.5 pro distinguishes itself through precise multilingual and dialect lip-syncing, dynamic cinematic camera control, and enhanced narrative coherence, positioning it as a robust engine for professional-grade content creation. Seedance 1.5 pro is now accessible on Volcano Engine at https://console.volcengine.com/ark/region:ark+cn-beijing/experience/vision?type=GenVideo.
Virtual Width Networks
Nov 17, 2025



We introduce Virtual Width Networks (VWN), a framework that delivers the benefits of wider representations without incurring the quadratic cost of increasing the hidden size. VWN decouples representational width from backbone width, expanding the embedding space while keeping backbone compute nearly constant. In our large-scale experiment, an 8-times expansion accelerates optimization by over 2 times for next-token and 3 times for next-2-token prediction. The advantage amplifies over training as both the loss gap grows and the convergence-speedup ratio increases, showing that VWN is not only token-efficient but also increasingly effective with scale. Moreover, we identify an approximately log-linear scaling relation between virtual width and loss reduction, offering an initial empirical basis and motivation for exploring virtual-width scaling as a new dimension of large-model efficiency.
ParaS2S: Benchmarking and Aligning Spoken Language Models for Paralinguistic-aware Speech-to-Speech Interaction
Nov 11, 2025Speech-to-Speech (S2S) models have shown promising dialogue capabilities, but their ability to handle paralinguistic cues--such as emotion, tone, and speaker attributes--and to respond appropriately in both content and style remains underexplored. Progress is further hindered by the scarcity of high-quality and expressive demonstrations. To address this, we introduce a novel reinforcement learning (RL) framework for paralinguistic-aware S2S, ParaS2S, which evaluates and optimizes both content and speaking style directly at the waveform level. We first construct ParaS2SBench, a benchmark comprehensively evaluates S2S models' output for content and style appropriateness from diverse and challenging input queries. It scores the fitness of input-output pairs and aligns well with human judgments, serving as an automatic judge for model outputs. With this scalable scoring feedback, we enable the model to explore and learn from diverse unlabeled speech via Group Relative Policy Optimization (GRPO). Experiments show that existing S2S models fail to respond appropriately to paralinguistic attributes, performing no better than pipeline-based baselines. Our RL approach achieves a 11% relative improvement in response content and style's appropriateness on ParaS2SBench over supervised fine-tuning (SFT), surpassing all prior models while requiring substantially fewer warm-up annotations than pure SFT.
A Study of Large Language Models for Patient Information Extraction: Model Architecture, Fine-Tuning Strategy, and Multi-task Instruction Tuning
Sep 05, 2025



Natural language processing (NLP) is a key technology to extract important patient information from clinical narratives to support healthcare applications. The rapid development of large language models (LLMs) has revolutionized many NLP tasks in the clinical domain, yet their optimal use in patient information extraction tasks requires further exploration. This study examines LLMs' effectiveness in patient information extraction, focusing on LLM architectures, fine-tuning strategies, and multi-task instruction tuning techniques for developing robust and generalizable patient information extraction systems. This study aims to explore key concepts of using LLMs for clinical concept and relation extraction tasks, including: (1) encoder-only or decoder-only LLMs, (2) prompt-based parameter-efficient fine-tuning (PEFT) algorithms, and (3) multi-task instruction tuning on few-shot learning performance. We benchmarked a suite of LLMs, including encoder-based LLMs (BERT, GatorTron) and decoder-based LLMs (GatorTronGPT, Llama 3.1, GatorTronLlama), across five datasets. We compared traditional full-size fine-tuning and prompt-based PEFT. We explored a multi-task instruction tuning framework that combines both tasks across four datasets to evaluate the zero-shot and few-shot learning performance using the leave-one-dataset-out strategy.
Seed-Prover: Deep and Broad Reasoning for Automated Theorem Proving
Aug 01, 2025LLMs have demonstrated strong mathematical reasoning abilities by leveraging reinforcement learning with long chain-of-thought, yet they continue to struggle with theorem proving due to the lack of clear supervision signals when solely using natural language. Dedicated domain-specific languages like Lean provide clear supervision via formal verification of proofs, enabling effective training through reinforcement learning. In this work, we propose \textbf{Seed-Prover}, a lemma-style whole-proof reasoning model. Seed-Prover can iteratively refine its proof based on Lean feedback, proved lemmas, and self-summarization. To solve IMO-level contest problems, we design three test-time inference strategies that enable both deep and broad reasoning. Seed-Prover proves $78.1\%$ of formalized past IMO problems, saturates MiniF2F, and achieves over 50\% on PutnamBench, outperforming the previous state-of-the-art by a large margin. To address the lack of geometry support in Lean, we introduce a geometry reasoning engine \textbf{Seed-Geometry}, which outperforms previous formal geometry engines. We use these two systems to participate in IMO 2025 and fully prove 5 out of 6 problems. This work represents a significant advancement in automated mathematical reasoning, demonstrating the effectiveness of formal verification with long chain-of-thought reasoning.
Seed LiveInterpret 2.0: End-to-end Simultaneous Speech-to-speech Translation with Your Voice
Jul 24, 2025



Simultaneous Interpretation (SI) represents one of the most daunting frontiers in the translation industry, with product-level automatic systems long plagued by intractable challenges: subpar transcription and translation quality, lack of real-time speech generation, multi-speaker confusion, and translated speech inflation, especially in long-form discourses. In this study, we introduce Seed-LiveInterpret 2.0, an end-to-end SI model that delivers high-fidelity, ultra-low-latency speech-to-speech generation with voice cloning capabilities. As a fully operational product-level solution, Seed-LiveInterpret 2.0 tackles these challenges head-on through our novel duplex speech-to-speech understanding-generating framework. Experimental results demonstrate that through large-scale pretraining and reinforcement learning, the model achieves a significantly better balance between translation accuracy and latency, validated by human interpreters to exceed 70% correctness in complex scenarios. Notably, Seed-LiveInterpret 2.0 outperforms commercial SI solutions by significant margins in translation quality, while slashing the average latency of cloned speech from nearly 10 seconds to a near-real-time 3 seconds, which is around a near 70% reduction that drastically enhances practical usability.
Truncated Proximal Policy Optimization
Jun 18, 2025



Recently, test-time scaling Large Language Models (LLMs) have demonstrated exceptional reasoning capabilities across scientific and professional tasks by generating long chains-of-thought (CoT). As a crucial component for developing these reasoning models, reinforcement learning (RL), exemplified by Proximal Policy Optimization (PPO) and its variants, allows models to learn through trial and error. However, PPO can be time-consuming due to its inherent on-policy nature, which is further exacerbated by increasing response lengths. In this work, we propose Truncated Proximal Policy Optimization (T-PPO), a novel extension to PPO that improves training efficiency by streamlining policy update and length-restricted response generation. T-PPO mitigates the issue of low hardware utilization, an inherent drawback of fully synchronized long-generation procedures, where resources often sit idle during the waiting periods for complete rollouts. Our contributions are two-folds. First, we propose Extended Generalized Advantage Estimation (EGAE) for advantage estimation derived from incomplete responses while maintaining the integrity of policy learning. Second, we devise a computationally optimized mechanism that allows for the independent optimization of the policy and value models. By selectively filtering prompt and truncated tokens, this mechanism reduces redundant computations and accelerates the training process without sacrificing convergence performance. We demonstrate the effectiveness and efficacy of T-PPO on AIME 2024 with a 32B base model. The experimental results show that T-PPO improves the training efficiency of reasoning LLMs by up to 2.5x and outperforms its existing competitors.
A Topic Modeling Analysis of Stigma Dimensions, Social, and Related Behavioral Circumstances in Clinical Notes Among Patients with HIV
Jun 10, 2025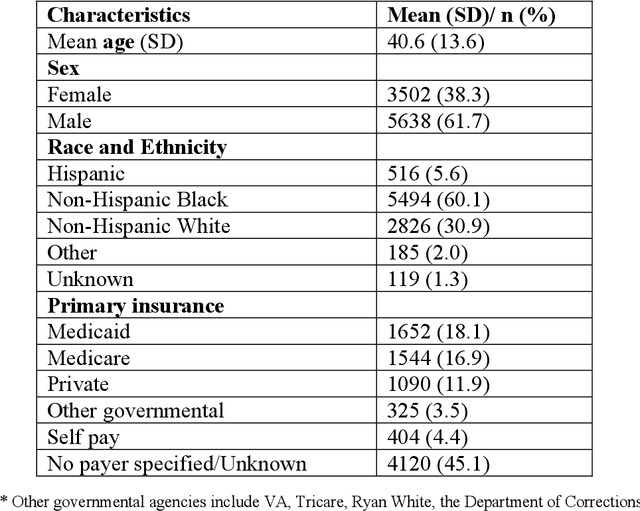
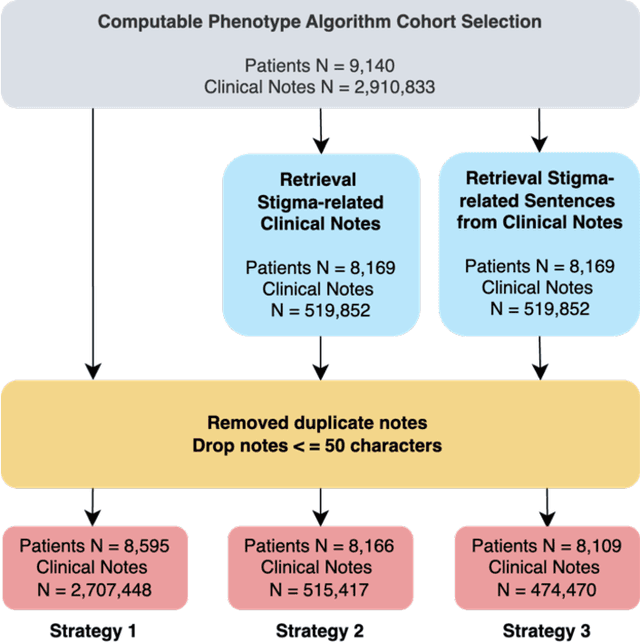
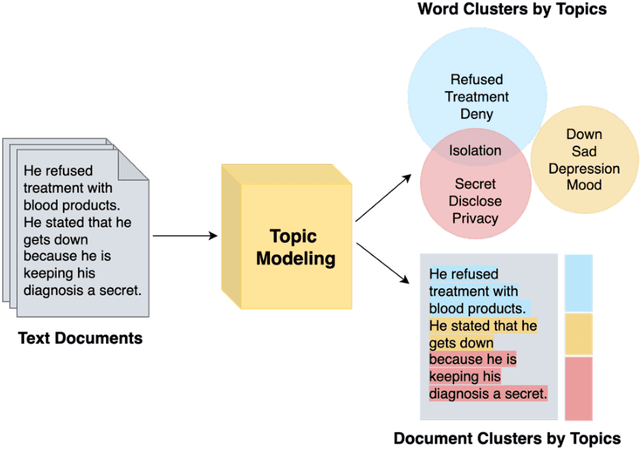
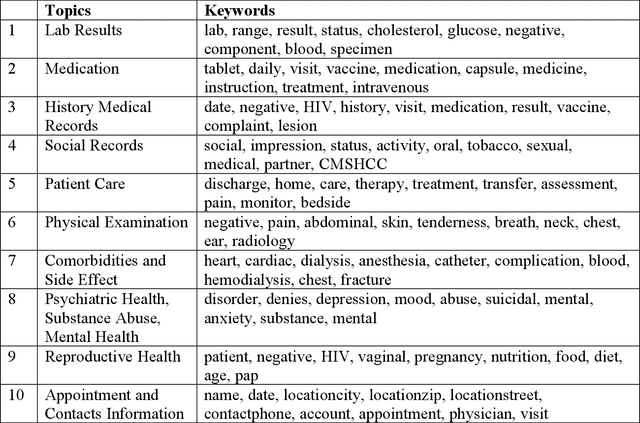
Objective: To characterize stigma dimensions, social, and related behavioral circumstances in people living with HIV (PLWHs) seeking care, using natural language processing methods applied to a large collection of electronic health record (EHR) clinical notes from a large integrated health system in the southeast United States. Methods: We identified 9,140 cohort of PLWHs from the UF Health IDR and performed topic modeling analysis using Latent Dirichlet Allocation (LDA) to uncover stigma dimensions, social, and related behavioral circumstances. Domain experts created a seed list of HIV-related stigma keywords, then applied a snowball strategy to iteratively review notes for additional terms until saturation was reached. To identify more target topics, we tested three keyword-based filtering strategies. Domain experts manually reviewed the detected topics using the prevalent terms and key discussion topics. Word frequency analysis was used to highlight the prevalent terms associated with each topic. In addition, we conducted topic variation analysis among subgroups to examine differences across age and sex-specific demographics. Results and Conclusion: Topic modeling on sentences containing at least one keyword uncovered a wide range of topic themes associated with HIV-related stigma, social, and related behaviors circumstances, including "Mental Health Concern and Stigma", "Social Support and Engagement", "Limited Healthcare Access and Severe Illness", "Treatment Refusal and Isolation" and so on. Topic variation analysis across age subgroups revealed differences. Extracting and understanding the HIV-related stigma dimensions, social, and related behavioral circumstances from EHR clinical notes enables scalable, time-efficient assessment, overcoming the limitations of traditional questionnaires and improving patient outcomes.
Scaling Up Biomedical Vision-Language Models: Fine-Tuning, Instruction Tuning, and Multi-Modal Learning
May 23, 2025To advance biomedical vison-language model capabilities through scaling up, fine-tuning, and instruction tuning, develop vision-language models with improved performance in handling long text, explore strategies to efficiently adopt vision language models for diverse multi-modal biomedical tasks, and examine the zero-shot learning performance. We developed two biomedical vision language models, BiomedGPT-Large and BiomedGPT-XLarge, based on an encoder-decoder-based transformer architecture. We fine-tuned the two models on 23 benchmark datasets from 6 multi-modal biomedical tasks including one image-only task (image classification), three language-only tasks (text understanding, text summarization and question answering), and two vision-language tasks (visual question answering and image captioning). We compared the developed scaled models with our previous BiomedGPT-Base model and existing prestigious models reported in the literature. We instruction-tuned the two models using a large-scale multi-modal biomedical instruction-tuning dataset and assessed the zero-shot learning performance and alignment accuracy.