 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMedViz: An Agent-based, Visual-guided Research Assistant for Navigating Biomedical Literature
Jan 28, 2026Biomedical researchers face increasing challenges in navigating millions of publications in diverse domains. Traditional search engines typically return articles as ranked text lists, offering little support for global exploration or in-depth analysis. Although recent advances in generative AI and large language models have shown promise in tasks such as summarization, extraction, and question answering, their dialog-based implementations are poorly integrated with literature search workflows. To address this gap, we introduce MedViz, a visual analytics system that integrates multiple AI agents with interactive visualization to support the exploration of the large-scale biomedical literature. MedViz combines a semantic map of millions of articles with agent-driven functions for querying, summarizing, and hypothesis generation, allowing researchers to iteratively refine questions, identify trends, and uncover hidden connections. By bridging intelligent agents with interactive visualization, MedViz transforms biomedical literature search into a dynamic, exploratory process that accelerates knowledge discovery.
EHRNavigator: A Multi-Agent System for Patient-Level Clinical Question Answering over Heterogeneous Electronic Health Records
Jan 15, 2026Clinical decision-making increasingly relies on timely and context-aware access to patient information within Electronic Health Records (EHRs), yet most existing natural language question-answering (QA) systems are evaluated solely on benchmark datasets, limiting their practical relevance. To overcome this limitation, we introduce EHRNavigator, a multi-agent framework that harnesses AI agents to perform patient-level question answering across heterogeneous and multimodal EHR data. We assessed its performance using both public benchmark and institutional datasets under realistic hospital conditions characterized by diverse schemas, temporal reasoning demands, and multimodal evidence integration. Through quantitative evaluation and clinician-validated chart review, EHRNavigator demonstrated strong generalization, achieving 86% accuracy on real-world cases while maintaining clinically acceptable response times. Overall, these findings confirm that EHRNavigator effectively bridges the gap between benchmark evaluation and clinical deployment, offering a robust, adaptive, and efficient solution for real-world EHR question answering.
SimRPD: Optimizing Recruitment Proactive Dialogue Agents through Simulator-Based Data Evaluation and Selection
Jan 08, 2026Task-oriented proactive dialogue agents play a pivotal role in recruitment, particularly for steering conversations towards specific business outcomes, such as acquiring social-media contacts for private-channel conversion. Although supervised fine-tuning and reinforcement learning have proven effective for training such agents, their performance is heavily constrained by the scarcity of high-quality, goal-oriented domain-specific training data. To address this challenge, we propose SimRPD, a three-stage framework for training recruitment proactive dialogue agents. First, we develop a high-fidelity user simulator to synthesize large-scale conversational data through multi-turn online dialogue. Then we introduce a multi-dimensional evaluation framework based on Chain-of-Intention (CoI) to comprehensively assess the simulator and effectively select high-quality data, incorporating both global-level and instance-level metrics. Finally, we train the recruitment proactive dialogue agent on the selected dataset. Experiments in a real-world recruitment scenario demonstrate that SimRPD outperforms existing simulator-based data selection strategies, highlighting its practical value for industrial deployment and its potential applicability to other business-oriented dialogue scenarios.
CDEMapper: Enhancing NIH Common Data Element Normalization using Large Language Models
Nov 30, 2024Common Data Elements (CDEs) standardize data collection and sharing across studies, enhancing data interoperability and improving research reproducibility. However, implementing CDEs presents challenges due to the broad range and variety of data elements. This study aims to develop an effective and efficient mapping tool to bridge the gap between local data elements and National Institutes of Health (NIH) CDEs. We propose CDEMapper, a large language model (LLM) powered mapping tool designed to assist in mapping local data elements to NIH CDEs. CDEMapper has three core modules: (1) CDE indexing and embeddings. NIH CDEs were indexed and embedded to support semantic search; (2) CDE recommendations. The tool combines Elasticsearch (BM25 similarity methods) with state of the art GPT services to recommend candidate CDEs and their permissible values; and (3) Human review. Users review and select the NIH CDEs and values that best match their data elements and value sets. We evaluate the tool recommendation accuracy against manually annotated mapping results. CDEMapper offers a publicly available, LLM-powered, and intuitive user interface that consolidates essential and advanced mapping services into a streamlined pipeline. It provides a step by step, quality assured mapping workflow designed with a user-centered approach. The evaluation results demonstrated that augmenting BM25 with GPT embeddings and a ranker consistently enhances CDEMapper mapping accuracy in three different mapping settings across four evaluation datasets. This work opens up the potential of using LLMs to assist with CDE recommendation and human curation when aligning local data elements with NIH CDEs. Additionally, this effort enhances clinical research data interoperability and helps researchers better understand the gaps between local data elements and NIH CDEs.
MAP: Low-compute Model Merging with Amortized Pareto Fronts via Quadratic Approximation
Jun 11, 2024



Model merging has emerged as an effective approach to combine multiple single-task models, fine-tuned from the same pre-trained model, into a multitask model. This process typically involves computing a weighted average of the model parameters without any additional training. Existing model-merging methods focus on enhancing average task accuracy. However, interference and conflicts between the objectives of different tasks can lead to trade-offs during model merging. In real-world applications, a set of solutions with various trade-offs can be more informative, helping practitioners make decisions based on diverse preferences. In this paper, we introduce a novel low-compute algorithm, Model Merging with Amortized Pareto Front (MAP). MAP identifies a Pareto set of scaling coefficients for merging multiple models to reflect the trade-offs. The core component of MAP is approximating the evaluation metrics of the various tasks using a quadratic approximation surrogate model derived from a pre-selected set of scaling coefficients, enabling amortized inference. Experimental results on vision and natural language processing tasks show that MAP can accurately identify the Pareto front. To further reduce the required computation of MAP, we propose (1) a Bayesian adaptive sampling algorithm and (2) a nested merging scheme with multiple stages.
Me LLaMA: Foundation Large Language Models for Medical Applications
Feb 20, 2024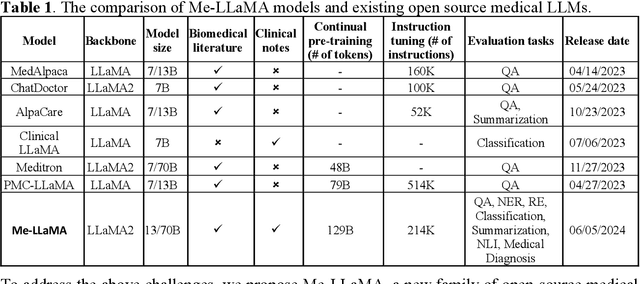
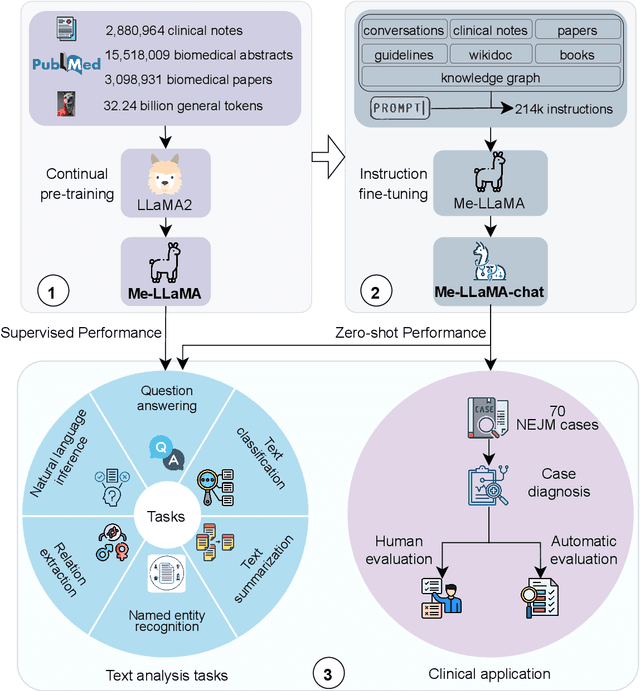

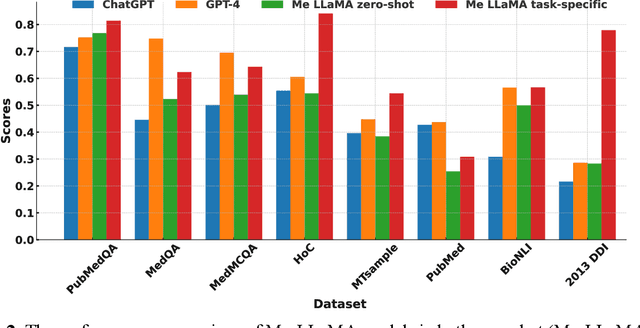
Recent large language models (LLMs) like ChatGPT and LLaMA have shown great promise in many AI applications. However, their performance on medical tasks is suboptimal and can be further improved by training on large domain-specific datasets. This study introduces Me LLaMA, a medical LLM family including foundation models - Me LLaMA 13/70B and their chat-enhanced versions - Me LLaMA 13/70B-chat, developed through the continual pre-training and instruction tuning of LLaMA2 using large medical data. Our domain-specific data suite for training and evaluation, includes a large-scale continual pre-training dataset with 129B tokens, an instruction tuning dataset with 214k samples, and a medical evaluation benchmark (MIBE) across six tasks with 14 datasets. Our extensive evaluation using MIBE shows that Me LLaMA models surpass existing open-source medical LLMs in zero-shot and few-shot learning and outperform commercial giants like ChatGPT on 6 out of 8 datasets and GPT-4 in 3 out of 8 datasets. In addition, we empirically investigated the catastrophic forgetting problem, and our results show that Me LLaMA models outperform other medical LLMs. Me LLaMA is one of the first and largest open-source foundational LLMs designed for the medical domain, using both biomedical and clinical data. It exhibits superior performance across both general and medical tasks compared to other medical LLMs, rendering it an attractive choice for medical AI applications. All resources are available at: https://github.com/BIDS-Xu-Lab/Me-LLaMA.
Reducing operator complexity in Algebraic Multigrid with Machine Learning Approaches
Jul 15, 2023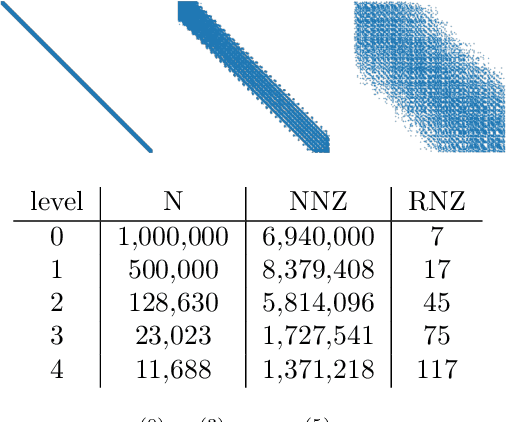
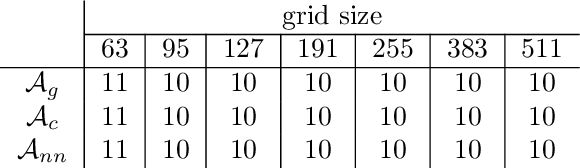
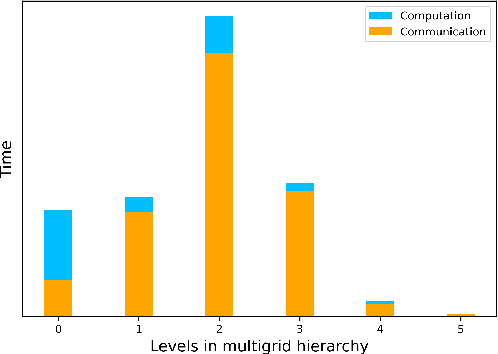
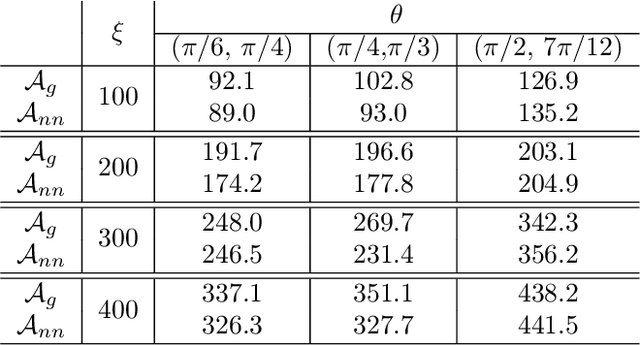
We propose a data-driven and machine-learning-based approach to compute non-Galerkin coarse-grid operators in algebraic multigrid (AMG) methods, addressing the well-known issue of increasing operator complexity. Guided by the AMG theory on spectrally equivalent coarse-grid operators, we have developed novel ML algorithms that utilize neural networks (NNs) combined with smooth test vectors from multigrid eigenvalue problems. The proposed method demonstrates promise in reducing the complexity of coarse-grid operators while maintaining overall AMG convergence for solving parametric partial differential equation (PDE) problems. Numerical experiments on anisotropic rotated Laplacian and linear elasticity problems are provided to showcase the performance and compare with existing methods for computing non-Galerkin coarse-grid operators.
Encoding Time-Series Explanations through Self-Supervised Model Behavior Consistency
Jun 03, 2023Interpreting time series models is uniquely challenging because it requires identifying both the location of time series signals that drive model predictions and their matching to an interpretable temporal pattern. While explainers from other modalities can be applied to time series, their inductive biases do not transfer well to the inherently uninterpretable nature of time series. We present TimeX, a time series consistency model for training explainers. TimeX trains an interpretable surrogate to mimic the behavior of a pretrained time series model. It addresses the issue of model faithfulness by introducing model behavior consistency, a novel formulation that preserves relations in the latent space induced by the pretrained model with relations in the latent space induced by TimeX. TimeX provides discrete attribution maps and, unlike existing interpretability methods, it learns a latent space of explanations that can be used in various ways, such as to provide landmarks to visually aggregate similar explanations and easily recognize temporal patterns. We evaluate TimeX on 8 synthetic and real-world datasets and compare its performance against state-of-the-art interpretability methods. We also conduct case studies using physiological time series. Quantitative evaluations demonstrate that TimeX achieves the highest or second-highest performance in every metric compared to baselines across all datasets. Through case studies, we show that the novel components of TimeX show potential for training faithful, interpretable models that capture the behavior of pretrained time series models.
GNNDelete: A General Strategy for Unlearning in Graph Neural Networks
Feb 26, 2023



Graph unlearning, which involves deleting graph elements such as nodes, node labels, and relationships from a trained graph neural network (GNN) model, is crucial for real-world applications where data elements may become irrelevant, inaccurate, or privacy-sensitive. However, existing methods for graph unlearning either deteriorate model weights shared across all nodes or fail to effectively delete edges due to their strong dependence on local graph neighborhoods. To address these limitations, we introduce GNNDelete, a novel model-agnostic layer-wise operator that optimizes two critical properties, namely, Deleted Edge Consistency and Neighborhood Influence, for graph unlearning. Deleted Edge Consistency ensures that the influence of deleted elements is removed from both model weights and neighboring representations, while Neighborhood Influence guarantees that the remaining model knowledge is preserved after deletion. GNNDelete updates representations to delete nodes and edges from the model while retaining the rest of the learned knowledge. We conduct experiments on seven real-world graphs, showing that GNNDelete outperforms existing approaches by up to 38.8% (AUC) on edge, node, and node feature deletion tasks, and 32.2% on distinguishing deleted edges from non-deleted ones. Additionally, GNNDelete is efficient, taking 12.3x less time and 9.3x less space than retraining GNN from scratch on WordNet18.
MedDiff: Generating Electronic Health Records using Accelerated Denoising Diffusion Model
Feb 08, 2023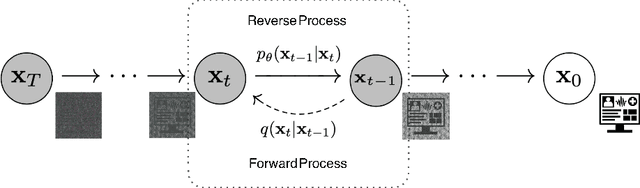

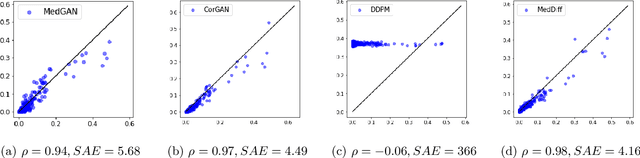
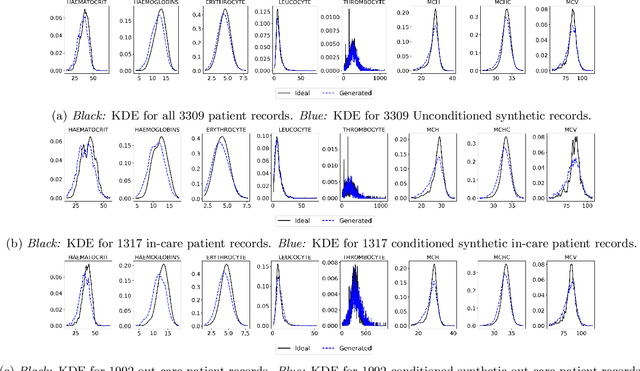
Due to patient privacy protection concerns, machine learning research in healthcare has been undeniably slower and limited than in other application domains. High-quality, realistic, synthetic electronic health records (EHRs) can be leveraged to accelerate methodological developments for research purposes while mitigating privacy concerns associated with data sharing. The current state-of-the-art model for synthetic EHR generation is generative adversarial networks, which are notoriously difficult to train and can suffer from mode collapse. Denoising Diffusion Probabilistic Models, a class of generative models inspired by statistical thermodynamics, have recently been shown to generate high-quality synthetic samples in certain domains. It is unknown whether these can generalize to generation of large-scale, high-dimensional EHRs. In this paper, we present a novel generative model based on diffusion models that is the first successful application on electronic health records. Our model proposes a mechanism to perform class-conditional sampling to preserve label information. We also introduce a new sampling strategy to accelerate the inference speed. We empirically show that our model outperforms existing state-of-the-art synthetic EHR generation methods.