 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePFT: Phonon Fine-tuning for Machine Learned Interatomic Potentials
Jan 12, 2026Many materials properties depend on higher-order derivatives of the potential energy surface, yet machine learned interatomic potentials (MLIPs) trained with standard a standard loss on energy, force, and stress errors can exhibit error in curvature, degrading the prediction of vibrational properties. We introduce phonon fine-tuning (PFT), which directly supervises second-order force constants of materials by matching MLIP energy Hessians to DFT-computed force constants from finite displacement phonon calculations. To scale to large supercells, PFT stochastically samples Hessian columns and computes the loss with a single Hessian-vector product. We also use a simple co-training scheme to incorporate upstream data to mitigate catastrophic forgetting. On the MDR Phonon benchmark, PFT improves Nequix MP (trained on Materials Project) by 55% on average across phonon thermodynamic properties and achieves state-of-the-art performance among models trained on Materials Project trajectories. PFT also generalizes to improve properties beyond second-derivatives, improving thermal conductivity predictions that rely on third-order derivatives of the potential energy.
UniTS: Building a Unified Time Series Model
Feb 29, 2024



Foundation models, especially LLMs, are profoundly transforming deep learning. Instead of training many task-specific models, we can adapt a single pretrained model to many tasks via fewshot prompting or fine-tuning. However, current foundation models apply to sequence data but not to time series, which present unique challenges due to the inherent diverse and multidomain time series datasets, diverging task specifications across forecasting, classification and other types of tasks, and the apparent need for task-specialized models. We developed UNITS, a unified time series model that supports a universal task specification, accommodating classification, forecasting, imputation, and anomaly detection tasks. This is achieved through a novel unified network backbone, which incorporates sequence and variable attention along with a dynamic linear operator and is trained as a unified model. Across 38 multi-domain datasets, UNITS demonstrates superior performance compared to task-specific models and repurposed natural language-based LLMs. UNITS exhibits remarkable zero-shot, few-shot, and prompt learning capabilities when evaluated on new data domains and tasks. The source code and datasets are available at https://github.com/mims-harvard/UniTS.
Higher-Order Equivariant Neural Networks for Charge Density Prediction in Materials
Dec 08, 2023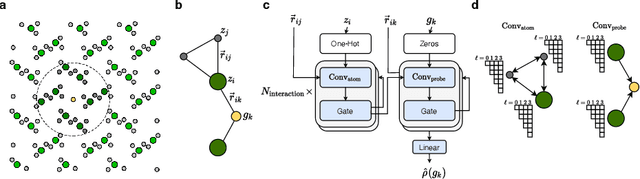

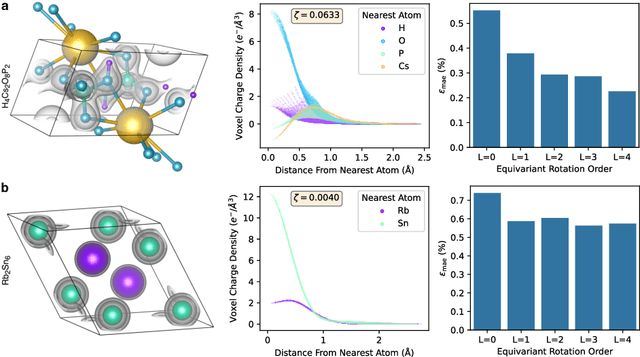
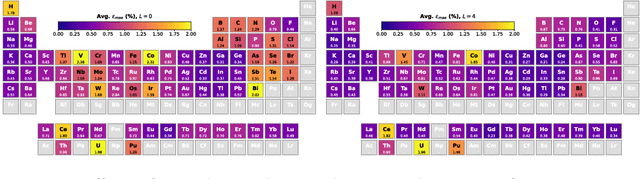
The calculation of electron density distribution using density functional theory (DFT) in materials and molecules is central to the study of their quantum and macro-scale properties, yet accurate and efficient calculation remains a long-standing challenge in the field of material science. This work introduces ChargE3Net, an E(3)-equivariant graph neural network for predicting electron density in atomic systems. ChargE3Net achieves equivariance through the use of higher-order tensor representations, and directly predicts the charge density at any arbitrary point in the system. We show that our method achieves greater performance than prior work on large and diverse sets of molecules and materials, and scales to larger systems than what is feasible to compute with DFT. Using predicted electron densities as an initialization, we show that fewer self-consistent iterations are required to converge DFT over the default initialization. In addition, we show that non-self-consistent calculations using the predicted electron densities can predict electronic and thermodynamic properties of materials at near-DFT accuracy.
Encoding Time-Series Explanations through Self-Supervised Model Behavior Consistency
Jun 03, 2023Interpreting time series models is uniquely challenging because it requires identifying both the location of time series signals that drive model predictions and their matching to an interpretable temporal pattern. While explainers from other modalities can be applied to time series, their inductive biases do not transfer well to the inherently uninterpretable nature of time series. We present TimeX, a time series consistency model for training explainers. TimeX trains an interpretable surrogate to mimic the behavior of a pretrained time series model. It addresses the issue of model faithfulness by introducing model behavior consistency, a novel formulation that preserves relations in the latent space induced by the pretrained model with relations in the latent space induced by TimeX. TimeX provides discrete attribution maps and, unlike existing interpretability methods, it learns a latent space of explanations that can be used in various ways, such as to provide landmarks to visually aggregate similar explanations and easily recognize temporal patterns. We evaluate TimeX on 8 synthetic and real-world datasets and compare its performance against state-of-the-art interpretability methods. We also conduct case studies using physiological time series. Quantitative evaluations demonstrate that TimeX achieves the highest or second-highest performance in every metric compared to baselines across all datasets. Through case studies, we show that the novel components of TimeX show potential for training faithful, interpretable models that capture the behavior of pretrained time series models.
Domain Adaptation for Time Series Under Feature and Label Shifts
Feb 06, 2023
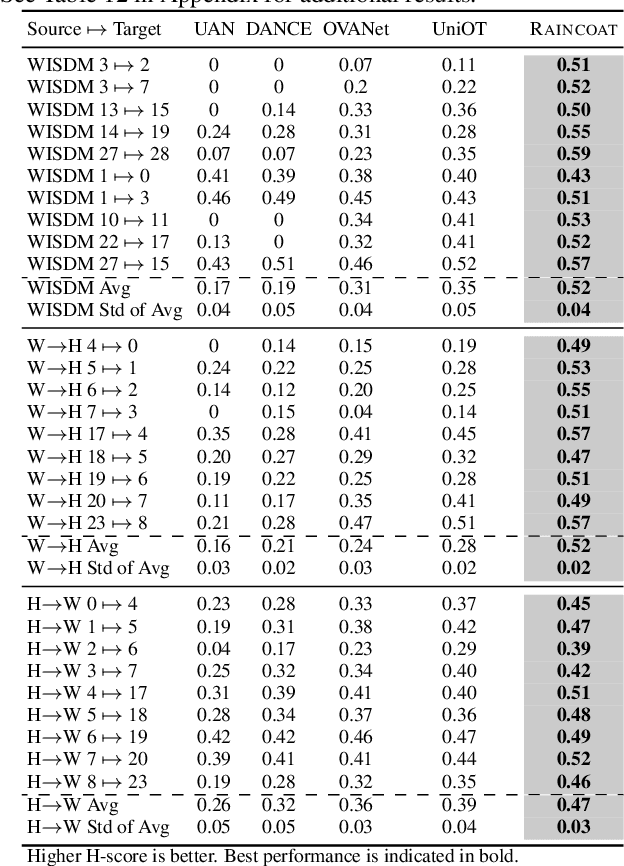
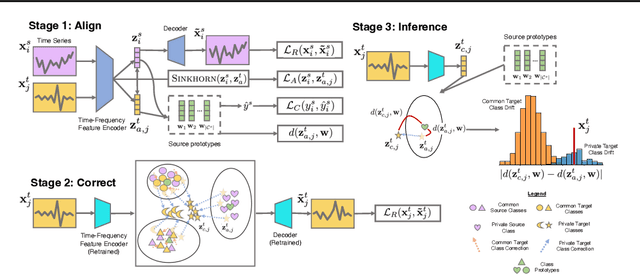

The transfer of models trained on labeled datasets in a source domain to unlabeled target domains is made possible by unsupervised domain adaptation (UDA). However, when dealing with complex time series models, the transferability becomes challenging due to the dynamic temporal structure that varies between domains, resulting in feature shifts and gaps in the time and frequency representations. Furthermore, tasks in the source and target domains can have vastly different label distributions, making it difficult for UDA to mitigate label shifts and recognize labels that only exist in the target domain. We present RAINCOAT, the first model for both closed-set and universal DA on complex time series. RAINCOAT addresses feature and label shifts by considering both temporal and frequency features, aligning them across domains, and correcting for misalignments to facilitate the detection of private labels. Additionally,RAINCOAT improves transferability by identifying label shifts in target domains. Our experiments with 5 datasets and 13 state-of-the-art UDA methods demonstrate that RAINCOAT can achieve an improvement in performance of up to 16.33%, and can effectively handle both closed-set and universal adaptation.
Graph Contrastive Learning for Materials
Nov 24, 2022


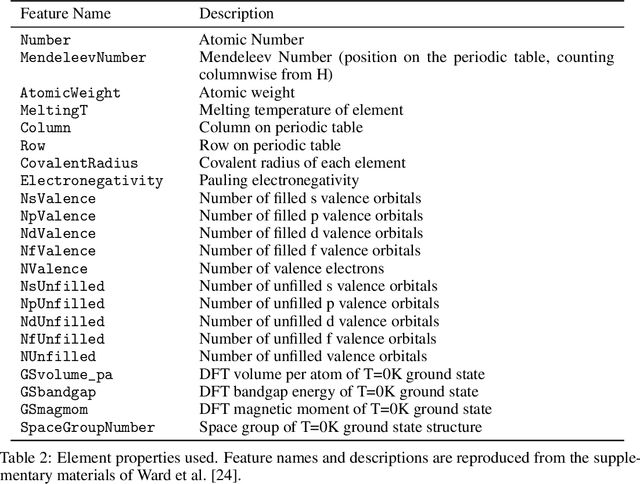
Recent work has shown the potential of graph neural networks to efficiently predict material properties, enabling high-throughput screening of materials. Training these models, however, often requires large quantities of labelled data, obtained via costly methods such as ab initio calculations or experimental evaluation. By leveraging a series of material-specific transformations, we introduce CrystalCLR, a framework for constrastive learning of representations with crystal graph neural networks. With the addition of a novel loss function, our framework is able to learn representations competitive with engineered fingerprinting methods. We also demonstrate that via model finetuning, contrastive pretraining can improve the performance of graph neural networks for prediction of material properties and significantly outperform traditional ML models that use engineered fingerprints. Lastly, we observe that CrystalCLR produces material representations that form clusters by compound class.
AAVAE: Augmentation-Augmented Variational Autoencoders
Jul 26, 2021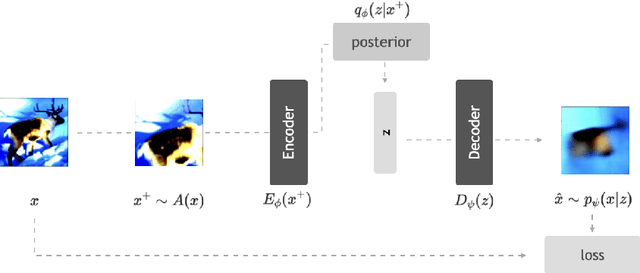
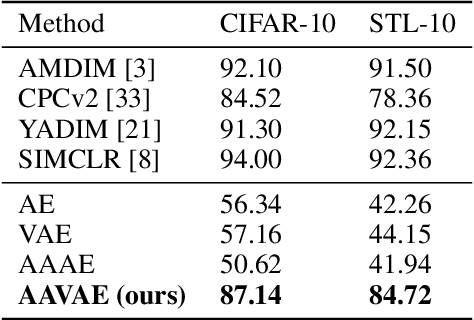
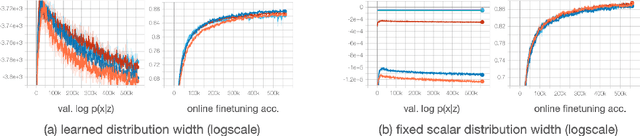
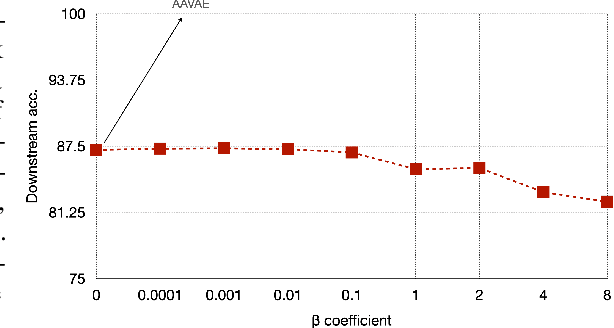
Recent methods for self-supervised learning can be grouped into two paradigms: contrastive and non-contrastive approaches. Their success can largely be attributed to data augmentation pipelines which generate multiple views of a single input that preserve the underlying semantics. In this work, we introduce augmentation-augmented variational autoencoders (AAVAE), a third approach to self-supervised learning based on autoencoding. We derive AAVAE starting from the conventional variational autoencoder (VAE), by replacing the KL divergence regularization, which is agnostic to the input domain, with data augmentations that explicitly encourage the internal representations to encode domain-specific invariances and equivariances. We empirically evaluate the proposed AAVAE on image classification, similar to how recent contrastive and non-contrastive learning algorithms have been evaluated. Our experiments confirm the effectiveness of data augmentation as a replacement for KL divergence regularization. The AAVAE outperforms the VAE by 30% on CIFAR-10 and 40% on STL-10. The results for AAVAE are largely comparable to the state-of-the-art for self-supervised learning.
U-Noise: Learnable Noise Masks for Interpretable Image Segmentation
Jan 20, 2021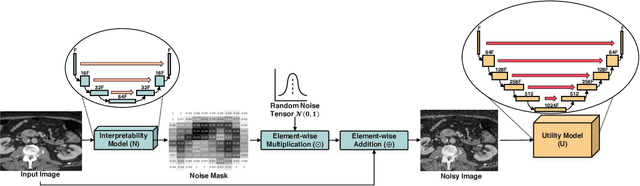
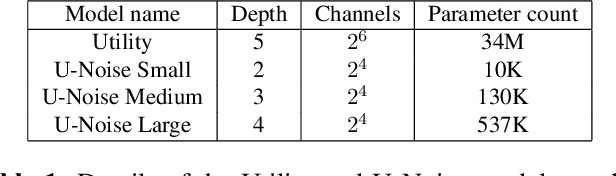
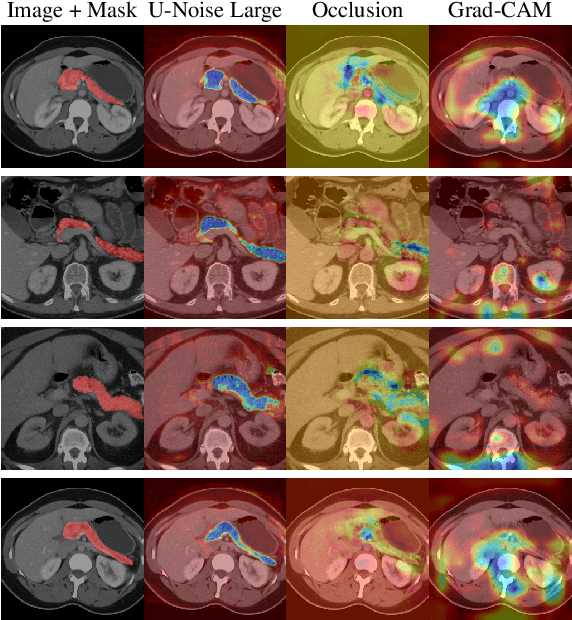

Deep Neural Networks (DNNs) are widely used for decision making in a myriad of critical applications, ranging from medical to societal and even judicial. Given the importance of these decisions, it is crucial for us to be able to interpret these models. We introduce a new method for interpreting image segmentation models by learning regions of images in which noise can be applied without hindering downstream model performance. We apply this method to segmentation of the pancreas in CT scans, and qualitatively compare the quality of the method to existing explainability techniques, such as Grad-CAM and occlusion sensitivity. Additionally we show that, unlike other methods, our interpretability model can be quantitatively evaluated based on the downstream performance over obscured images.