 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatticeGen: A Cooperative Framework which Hides Generated Text in a Lattice for Privacy-Aware Generation on Cloud
Oct 02, 2023



In the current user-server interaction paradigm of prompted generation with large language models (LLM) on cloud, the server fully controls the generation process, which leaves zero options for users who want to keep the generated text to themselves. We propose LatticeGen, a cooperative framework in which the server still handles most of the computation while the user controls the sampling operation. The key idea is that the true generated sequence is mixed with noise tokens by the user and hidden in a noised lattice. Considering potential attacks from a hypothetically malicious server and how the user can defend against it, we propose the repeated beam-search attack and the mixing noise scheme. In our experiments we apply LatticeGen to protect both prompt and generation. It is shown that while the noised lattice degrades generation quality, LatticeGen successfully protects the true generation to a remarkable degree under strong attacks (more than 50% of the semantic remains hidden as measured by BERTScore).
Privacy-Preserving In-Context Learning with Differentially Private Few-Shot Generation
Sep 21, 2023



We study the problem of in-context learning (ICL) with large language models (LLMs) on private datasets. This scenario poses privacy risks, as LLMs may leak or regurgitate the private examples demonstrated in the prompt. We propose a novel algorithm that generates synthetic few-shot demonstrations from the private dataset with formal differential privacy (DP) guarantees, and show empirically that it can achieve effective ICL. We conduct extensive experiments on standard benchmarks and compare our algorithm with non-private ICL and zero-shot solutions. Our results demonstrate that our algorithm can achieve competitive performance with strong privacy levels. These results open up new possibilities for ICL with privacy protection for a broad range of applications.
Membership Inference Attacks against Language Models via Neighbourhood Comparison
May 29, 2023



Membership Inference attacks (MIAs) aim to predict whether a data sample was present in the training data of a machine learning model or not, and are widely used for assessing the privacy risks of language models. Most existing attacks rely on the observation that models tend to assign higher probabilities to their training samples than non-training points. However, simple thresholding of the model score in isolation tends to lead to high false-positive rates as it does not account for the intrinsic complexity of a sample. Recent work has demonstrated that reference-based attacks which compare model scores to those obtained from a reference model trained on similar data can substantially improve the performance of MIAs. However, in order to train reference models, attacks of this kind make the strong and arguably unrealistic assumption that an adversary has access to samples closely resembling the original training data. Therefore, we investigate their performance in more realistic scenarios and find that they are highly fragile in relation to the data distribution used to train reference models. To investigate whether this fragility provides a layer of safety, we propose and evaluate neighbourhood attacks, which compare model scores for a given sample to scores of synthetically generated neighbour texts and therefore eliminate the need for access to the training data distribution. We show that, in addition to being competitive with reference-based attacks that have perfect knowledge about the training data distribution, our attack clearly outperforms existing reference-free attacks as well as reference-based attacks with imperfect knowledge, which demonstrates the need for a reevaluation of the threat model of adversarial attacks.
Are Chatbots Ready for Privacy-Sensitive Applications? An Investigation into Input Regurgitation and Prompt-Induced Sanitization
May 24, 2023



LLM-powered chatbots are becoming widely adopted in applications such as healthcare, personal assistants, industry hiring decisions, etc. In many of these cases, chatbots are fed sensitive, personal information in their prompts, as samples for in-context learning, retrieved records from a database, or as part of the conversation. The information provided in the prompt could directly appear in the output, which might have privacy ramifications if there is sensitive information there. As such, in this paper, we aim to understand the input copying and regurgitation capabilities of these models during inference and how they can be directly instructed to limit this copying by complying with regulations such as HIPAA and GDPR, based on their internal knowledge of them. More specifically, we find that when ChatGPT is prompted to summarize cover letters of a 100 candidates, it would retain personally identifiable information (PII) verbatim in 57.4% of cases, and we find this retention to be non-uniform between different subgroups of people, based on attributes such as gender identity. We then probe ChatGPT's perception of privacy-related policies and privatization mechanisms by directly instructing it to provide compliant outputs and observe a significant omission of PII from output.
Smaller Language Models are Better Black-box Machine-Generated Text Detectors
May 17, 2023



With the advent of fluent generative language models that can produce convincing utterances very similar to those written by humans, distinguishing whether a piece of text is machine-generated or human-written becomes more challenging and more important, as such models could be used to spread misinformation, fake news, fake reviews and to mimic certain authors and figures. To this end, there have been a slew of methods proposed to detect machine-generated text. Most of these methods need access to the logits of the target model or need the ability to sample from the target. One such black-box detection method relies on the observation that generated text is locally optimal under the likelihood function of the generator, while human-written text is not. We find that overall, smaller and partially-trained models are better universal text detectors: they can more precisely detect text generated from both small and larger models. Interestingly, we find that whether the detector and generator were trained on the same data is not critically important to the detection success. For instance the OPT-125M model has an AUC of 0.81 in detecting ChatGPT generations, whereas a larger model from the GPT family, GPTJ-6B, has AUC of 0.45.
Privacy-Preserving Domain Adaptation of Semantic Parsers
Dec 20, 2022



Task-oriented dialogue systems often assist users with personal or confidential matters. For this reason, the developers of such a system are generally prohibited from observing actual usage. So how can they know where the system is failing and needs more training data or new functionality? In this work, we study ways in which realistic user utterances can be generated synthetically, to help increase the linguistic and functional coverage of the system, without compromising the privacy of actual users. To this end, we propose a two-stage Differentially Private (DP) generation method which first generates latent semantic parses, and then generates utterances based on the parses. Our proposed approach improves MAUVE by 3.8$\times$ and parse tree node-type overlap by 1.4$\times$ relative to current approaches for private synthetic data generation, improving both on fluency and semantic coverage. We further validate our approach on a realistic domain adaptation task of adding new functionality from private user data to a semantic parser, and show gains of 1.3$\times$ on its accuracy with the new feature.
Non-Parametric Temporal Adaptation for Social Media Topic Classification
Sep 13, 2022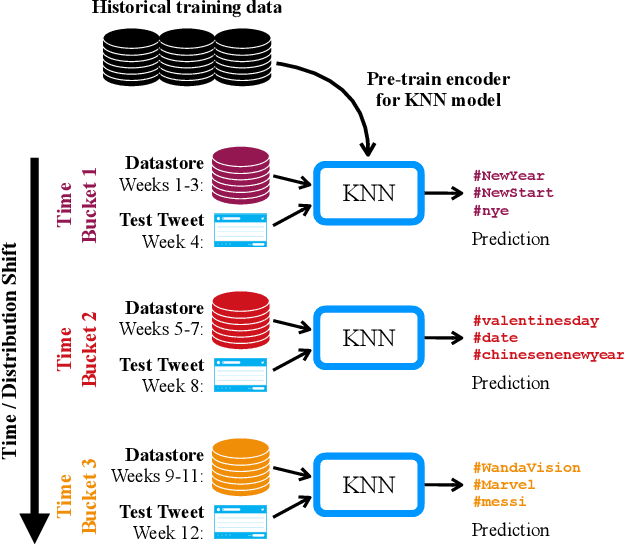
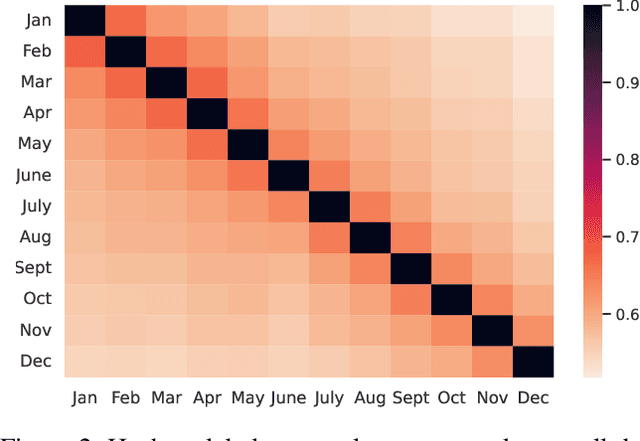
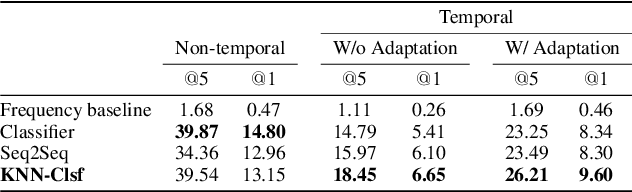
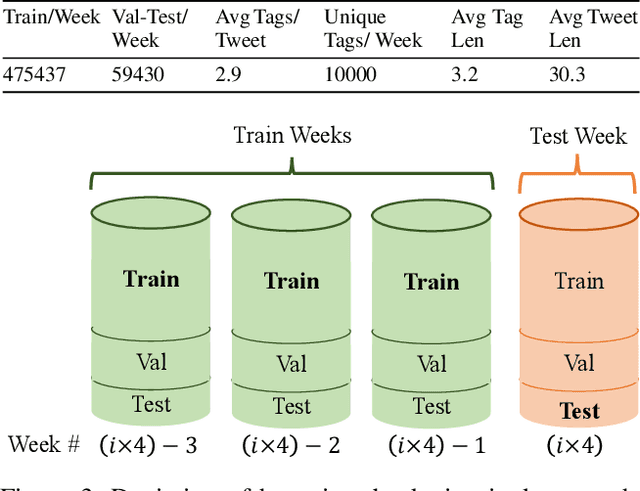
User-generated social media data is constantly changing as new trends influence online discussion, causing distribution shift in test data for social media NLP applications. In addition, training data is often subject to change as user data is deleted. Most current NLP systems are static and rely on fixed training data. As a result, they are unable to adapt to temporal change -- both test distribution shift and deleted training data -- without frequent, costly re-training. In this paper, we study temporal adaptation through the task of longitudinal hashtag prediction and propose a non-parametric technique as a simple but effective solution: non-parametric classifiers use datastores which can be updated, either to adapt to test distribution shift or training data deletion, without re-training. We release a new benchmark dataset comprised of 7.13M Tweets from 2021, along with their hashtags, broken into consecutive temporal buckets. We compare parametric neural hashtag classification and hashtag generation models, which need re-training for adaptation, with a non-parametric, training-free dense retrieval method that returns the nearest neighbor's hashtags based on text embedding distance. In experiments on our longitudinal Twitter dataset we find that dense nearest neighbor retrieval has a relative performance gain of 64.12% over the best parametric baseline on test sets that exhibit distribution shift without requiring gradient-based re-training. Furthermore, we show that our datastore approach is particularly well-suited to dynamically deleted user data, with negligible computational cost and performance loss. Our novel benchmark dataset and empirical analysis can support future inquiry into the important challenges presented by temporality in the deployment of AI systems on real-world user data.
Differentially Private Model Compression
Jun 03, 2022

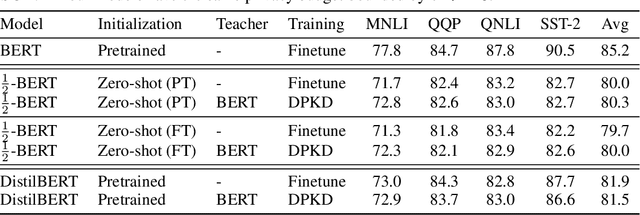
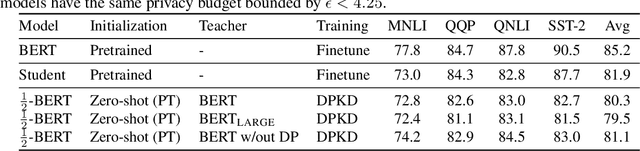
Recent papers have shown that large pre-trained language models (LLMs) such as BERT, GPT-2 can be fine-tuned on private data to achieve performance comparable to non-private models for many downstream Natural Language Processing (NLP) tasks while simultaneously guaranteeing differential privacy. The inference cost of these models -- which consist of hundreds of millions of parameters -- however, can be prohibitively large. Hence, often in practice, LLMs are compressed before they are deployed in specific applications. In this paper, we initiate the study of differentially private model compression and propose frameworks for achieving 50% sparsity levels while maintaining nearly full performance. We demonstrate these ideas on standard GLUE benchmarks using BERT models, setting benchmarks for future research on this topic.
Memorization in NLP Fine-tuning Methods
May 25, 2022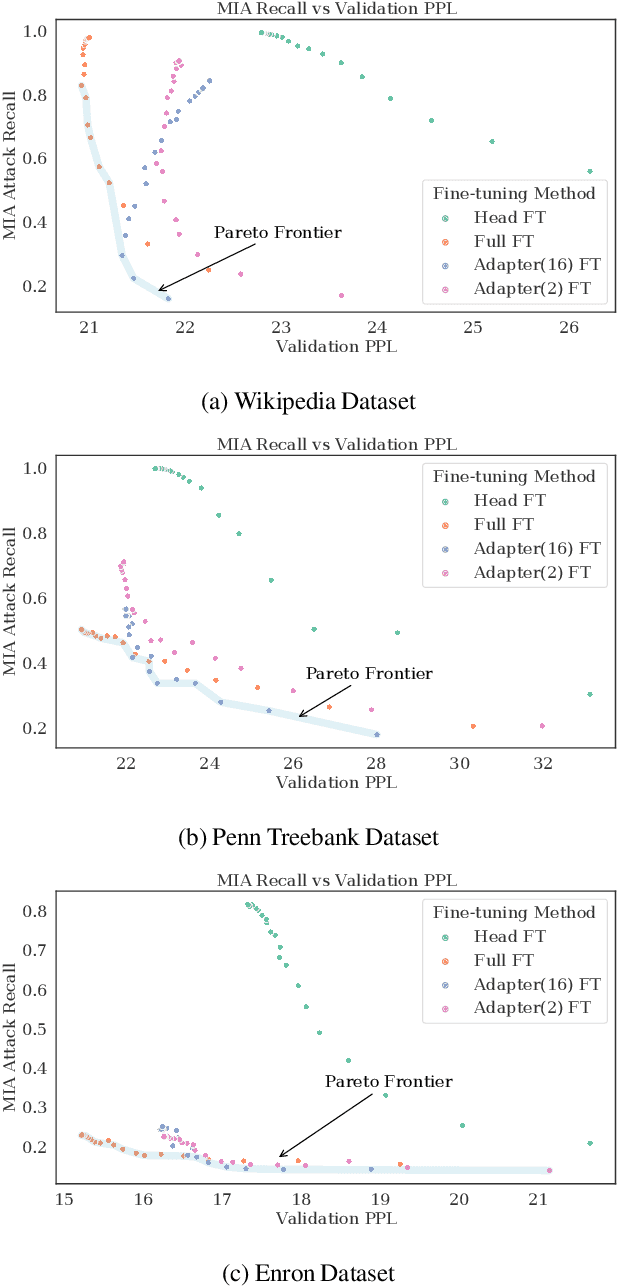
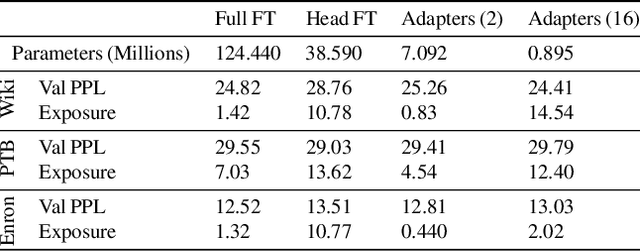
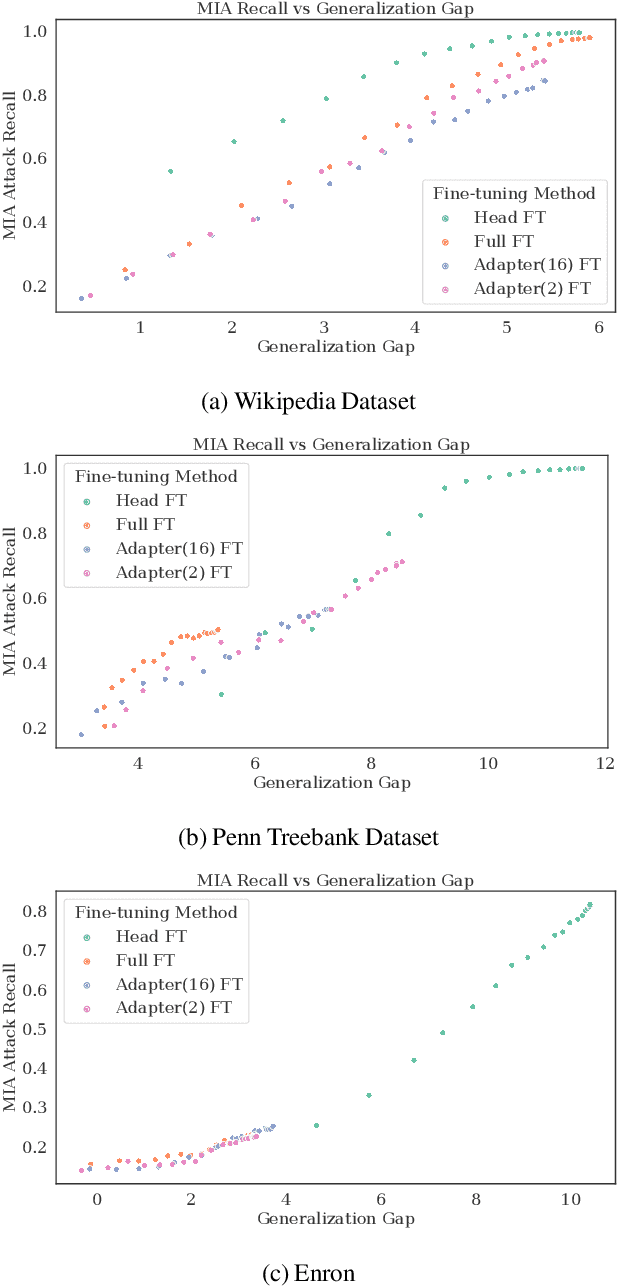

Large language models are shown to present privacy risks through memorization of training data, and several recent works have studied such risks for the pre-training phase. Little attention, however, has been given to the fine-tuning phase and it is not well understood how different fine-tuning methods (such as fine-tuning the full model, the model head, and adapter) compare in terms of memorization risk. This presents increasing concern as the "pre-train and fine-tune" paradigm proliferates. In this paper, we empirically study memorization of fine-tuning methods using membership inference and extraction attacks, and show that their susceptibility to attacks is very different. We observe that fine-tuning the head of the model has the highest susceptibility to attacks, whereas fine-tuning smaller adapters appears to be less vulnerable to known extraction attacks.
Mix and Match: Learning-free Controllable Text Generation using Energy Language Models
Apr 04, 2022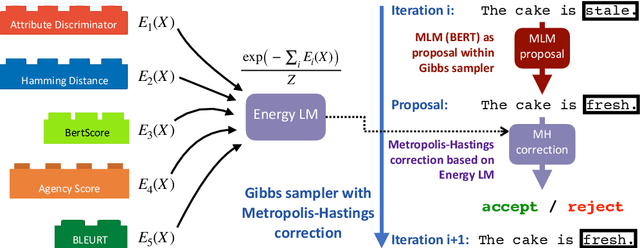

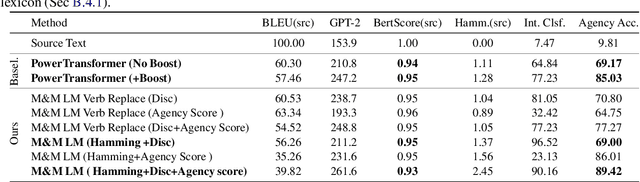
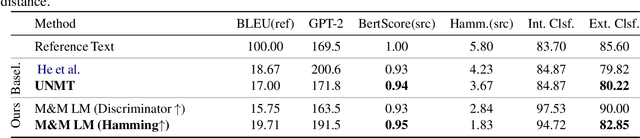
Recent work on controlled text generation has either required attribute-based fine-tuning of the base language model (LM), or has restricted the parameterization of the attribute discriminator to be compatible with the base autoregressive LM. In this work, we propose Mix and Match LM, a global score-based alternative for controllable text generation that combines arbitrary pre-trained black-box models for achieving the desired attributes in the generated text without involving any fine-tuning or structural assumptions about the black-box models. We interpret the task of controllable generation as drawing samples from an energy-based model whose energy values are a linear combination of scores from black-box models that are separately responsible for fluency, the control attribute, and faithfulness to any conditioning context. We use a Metropolis-Hastings sampling scheme to sample from this energy-based model using bidirectional context and global attribute features. We validate the effectiveness of our approach on various controlled generation and style-based text revision tasks by outperforming recently proposed methods that involve extra training, fine-tuning, or restrictive assumptions over the form of models.