 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeINTELLECT-3: Technical Report
Dec 18, 2025We present INTELLECT-3, a 106B-parameter Mixture-of-Experts model (12B active) trained with large-scale reinforcement learning on our end-to-end RL infrastructure stack. INTELLECT-3 achieves state of the art performance for its size across math, code, science and reasoning benchmarks, outperforming many larger frontier models. We open-source the model together with the full infrastructure stack used to create it, including RL frameworks, complete recipe, and a wide collection of environments, built with the verifiers library, for training and evaluation from our Environments Hub community platform. Built for this effort, we introduce prime-rl, an open framework for large-scale asynchronous reinforcement learning, which scales seamlessly from a single node to thousands of GPUs, and is tailored for agentic RL with first-class support for multi-turn interactions and tool use. Using this stack, we run both SFT and RL training on top of the GLM-4.5-Air-Base model, scaling RL training up to 512 H200s with high training efficiency.
INTELLECT-2: A Reasoning Model Trained Through Globally Decentralized Reinforcement Learning
May 12, 2025We introduce INTELLECT-2, the first globally distributed reinforcement learning (RL) training run of a 32 billion parameter language model. Unlike traditional centralized training efforts, INTELLECT-2 trains a reasoning model using fully asynchronous RL across a dynamic, heterogeneous swarm of permissionless compute contributors. To enable a training run with this unique infrastructure, we built various components from scratch: we introduce PRIME-RL, our training framework purpose-built for distributed asynchronous reinforcement learning, based on top of novel components such as TOPLOC, which verifies rollouts from untrusted inference workers, and SHARDCAST, which efficiently broadcasts policy weights from training nodes to inference workers. Beyond infrastructure components, we propose modifications to the standard GRPO training recipe and data filtering techniques that were crucial to achieve training stability and ensure that our model successfully learned its training objective, thus improving upon QwQ-32B, the state of the art reasoning model in the 32B parameter range. We open-source INTELLECT-2 along with all of our code and data, hoping to encourage and enable more open research in the field of decentralized training.
Membership Inference Attacks against Language Models via Neighbourhood Comparison
May 29, 2023



Membership Inference attacks (MIAs) aim to predict whether a data sample was present in the training data of a machine learning model or not, and are widely used for assessing the privacy risks of language models. Most existing attacks rely on the observation that models tend to assign higher probabilities to their training samples than non-training points. However, simple thresholding of the model score in isolation tends to lead to high false-positive rates as it does not account for the intrinsic complexity of a sample. Recent work has demonstrated that reference-based attacks which compare model scores to those obtained from a reference model trained on similar data can substantially improve the performance of MIAs. However, in order to train reference models, attacks of this kind make the strong and arguably unrealistic assumption that an adversary has access to samples closely resembling the original training data. Therefore, we investigate their performance in more realistic scenarios and find that they are highly fragile in relation to the data distribution used to train reference models. To investigate whether this fragility provides a layer of safety, we propose and evaluate neighbourhood attacks, which compare model scores for a given sample to scores of synthetically generated neighbour texts and therefore eliminate the need for access to the training data distribution. We show that, in addition to being competitive with reference-based attacks that have perfect knowledge about the training data distribution, our attack clearly outperforms existing reference-free attacks as well as reference-based attacks with imperfect knowledge, which demonstrates the need for a reevaluation of the threat model of adversarial attacks.
Smaller Language Models are Better Black-box Machine-Generated Text Detectors
May 17, 2023



With the advent of fluent generative language models that can produce convincing utterances very similar to those written by humans, distinguishing whether a piece of text is machine-generated or human-written becomes more challenging and more important, as such models could be used to spread misinformation, fake news, fake reviews and to mimic certain authors and figures. To this end, there have been a slew of methods proposed to detect machine-generated text. Most of these methods need access to the logits of the target model or need the ability to sample from the target. One such black-box detection method relies on the observation that generated text is locally optimal under the likelihood function of the generator, while human-written text is not. We find that overall, smaller and partially-trained models are better universal text detectors: they can more precisely detect text generated from both small and larger models. Interestingly, we find that whether the detector and generator were trained on the same data is not critically important to the detection success. For instance the OPT-125M model has an AUC of 0.81 in detecting ChatGPT generations, whereas a larger model from the GPT family, GPTJ-6B, has AUC of 0.45.
Psychologically-Inspired Causal Prompts
May 02, 2023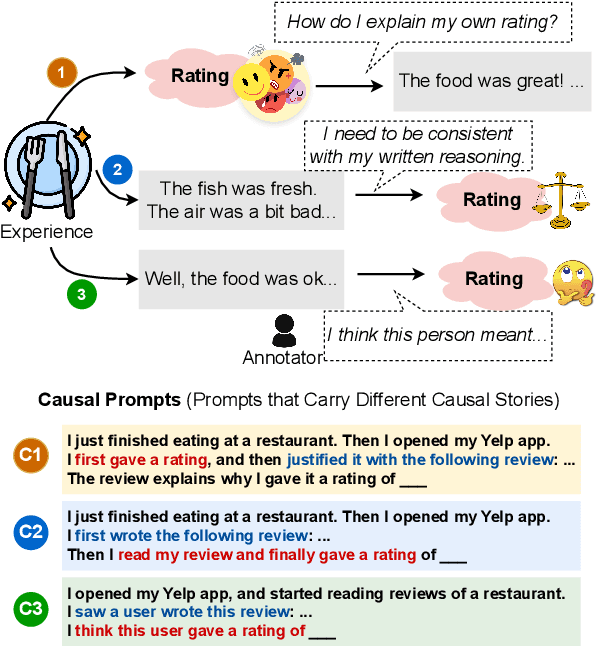


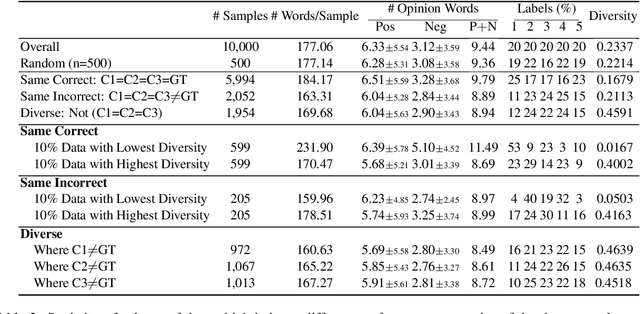
NLP datasets are richer than just input-output pairs; rather, they carry causal relations between the input and output variables. In this work, we take sentiment classification as an example and look into the causal relations between the review (X) and sentiment (Y). As psychology studies show that language can affect emotion, different psychological processes are evoked when a person first makes a rating and then self-rationalizes their feeling in a review (where the sentiment causes the review, i.e., Y -> X), versus first describes their experience, and weighs the pros and cons to give a final rating (where the review causes the sentiment, i.e., X -> Y ). Furthermore, it is also a completely different psychological process if an annotator infers the original rating of the user by theory of mind (ToM) (where the review causes the rating, i.e., X -ToM-> Y ). In this paper, we verbalize these three causal mechanisms of human psychological processes of sentiment classification into three different causal prompts, and study (1) how differently they perform, and (2) what nature of sentiment classification data leads to agreement or diversity in the model responses elicited by the prompts. We suggest future work raise awareness of different causal structures in NLP tasks. Our code and data are at https://github.com/cogito233/psych-causal-prompt
Unique Identification of 50,000+ Virtual Reality Users from Head & Hand Motion Data
Feb 17, 2023



With the recent explosive growth of interest and investment in virtual reality (VR) and the so-called "metaverse," public attention has rightly shifted toward the unique security and privacy threats that these platforms may pose. While it has long been known that people reveal information about themselves via their motion, the extent to which this makes an individual globally identifiable within virtual reality has not yet been widely understood. In this study, we show that a large number of real VR users (N=55,541) can be uniquely and reliably identified across multiple sessions using just their head and hand motion relative to virtual objects. After training a classification model on 5 minutes of data per person, a user can be uniquely identified amongst the entire pool of 50,000+ with 94.33% accuracy from 100 seconds of motion, and with 73.20% accuracy from just 10 seconds of motion. This work is the first to truly demonstrate the extent to which biomechanics may serve as a unique identifier in VR, on par with widely used biometrics such as facial or fingerprint recognition.
Understanding Stereotypes in Language Models: Towards Robust Measurement and Zero-Shot Debiasing
Dec 20, 2022Generated texts from large pretrained language models have been shown to exhibit a variety of harmful, human-like biases about various demographics. These findings prompted large efforts aiming to understand and measure such effects, with the goal of providing benchmarks that can guide the development of techniques mitigating these stereotypical associations. However, as recent research has pointed out, the current benchmarks lack a robust experimental setup, consequently hindering the inference of meaningful conclusions from their evaluation metrics. In this paper, we extend these arguments and demonstrate that existing techniques and benchmarks aiming to measure stereotypes tend to be inaccurate and consist of a high degree of experimental noise that severely limits the knowledge we can gain from benchmarking language models based on them. Accordingly, we propose a new framework for robustly measuring and quantifying biases exhibited by generative language models. Finally, we use this framework to investigate GPT-3's occupational gender bias and propose prompting techniques for mitigating these biases without the need for fine-tuning.
Differentially Private Language Models for Secure Data Sharing
Oct 26, 2022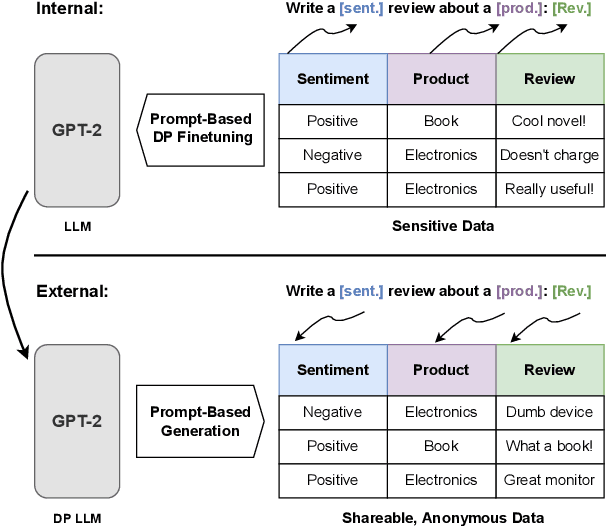
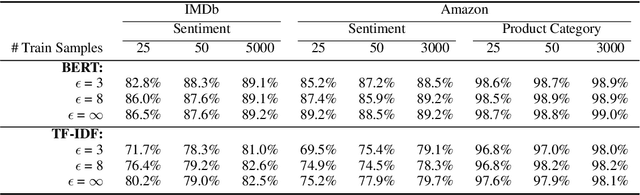

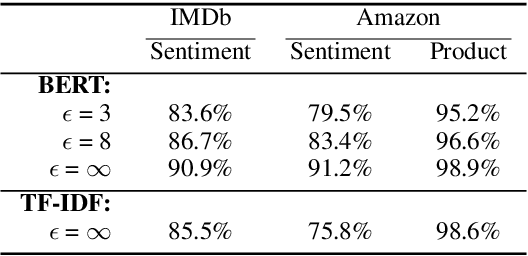
To protect the privacy of individuals whose data is being shared, it is of high importance to develop methods allowing researchers and companies to release textual data while providing formal privacy guarantees to its originators. In the field of NLP, substantial efforts have been directed at building mechanisms following the framework of local differential privacy, thereby anonymizing individual text samples before releasing them. In practice, these approaches are often dissatisfying in terms of the quality of their output language due to the strong noise required for local differential privacy. In this paper, we approach the problem at hand using global differential privacy, particularly by training a generative language model in a differentially private manner and consequently sampling data from it. Using natural language prompts and a new prompt-mismatch loss, we are able to create highly accurate and fluent textual datasets taking on specific desired attributes such as sentiment or topic and resembling statistical properties of the training data. We perform thorough experiments indicating that our synthetic datasets do not leak information from our original data and are of high language quality and highly suitable for training models for further analysis on real-world data. Notably, we also demonstrate that training classifiers on private synthetic data outperforms directly training classifiers on real data with DP-SGD.
The Limits of Word Level Differential Privacy
May 02, 2022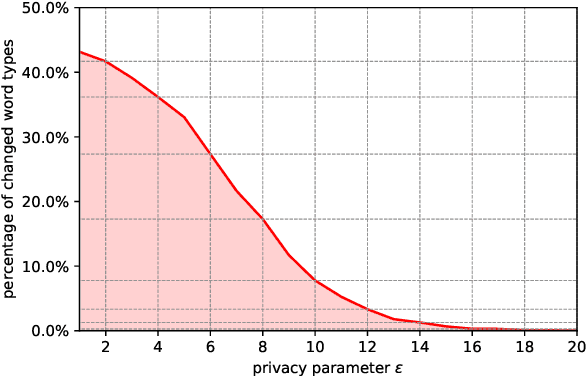
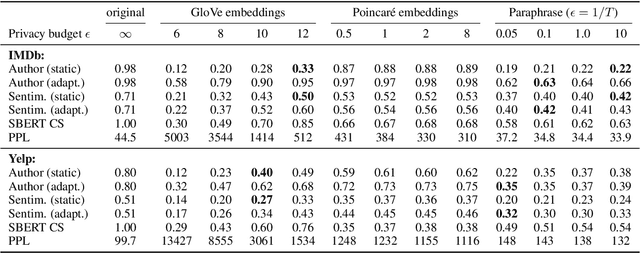
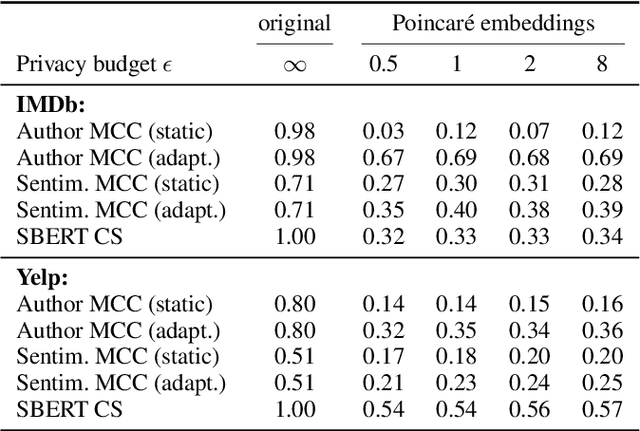
As the issues of privacy and trust are receiving increasing attention within the research community, various attempts have been made to anonymize textual data. A significant subset of these approaches incorporate differentially private mechanisms to perturb word embeddings, thus replacing individual words in a sentence. While these methods represent very important contributions, have various advantages over other techniques and do show anonymization capabilities, they have several shortcomings. In this paper, we investigate these weaknesses and demonstrate significant mathematical constraints diminishing the theoretical privacy guarantee as well as major practical shortcomings with regard to the protection against deanonymization attacks, the preservation of content of the original sentences as well as the quality of the language output. Finally, we propose a new method for text anonymization based on transformer based language models fine-tuned for paraphrasing that circumvents most of the identified weaknesses and also offers a formal privacy guarantee. We evaluate the performance of our method via thorough experimentation and demonstrate superior performance over the discussed mechanisms.
Measuring the Impact of (Psycho-)Linguistic and Readability Features and Their Spill Over Effects on the Prediction of Eye Movement Patterns
Mar 15, 2022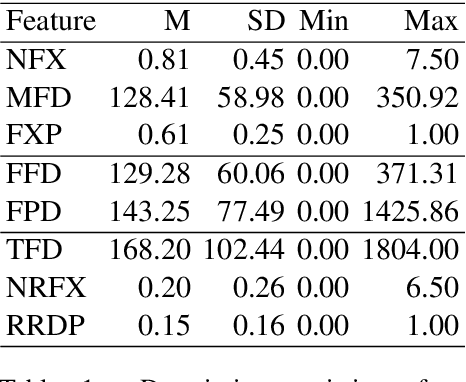
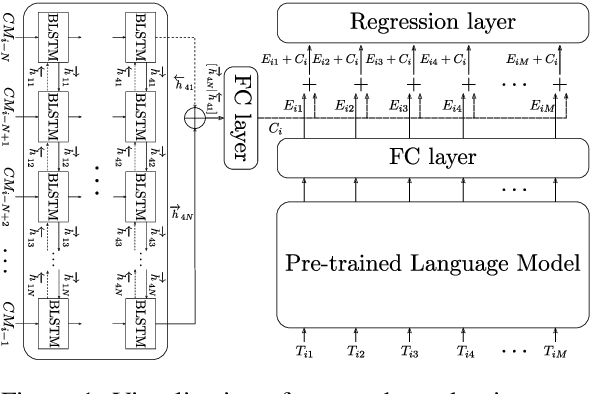
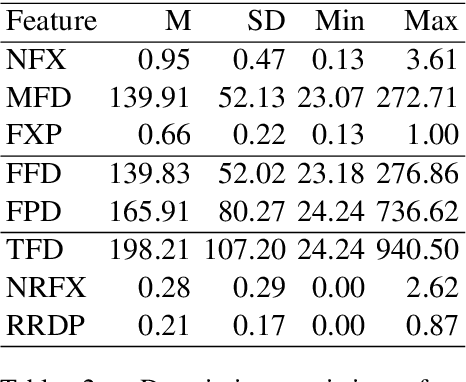
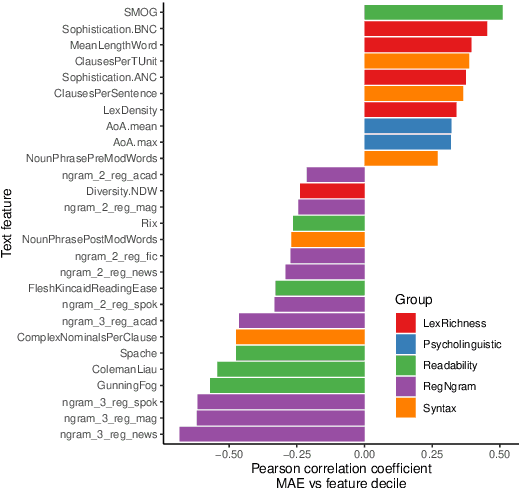
There is a growing interest in the combined use of NLP and machine learning methods to predict gaze patterns during naturalistic reading. While promising results have been obtained through the use of transformer-based language models, little work has been undertaken to relate the performance of such models to general text characteristics. In this paper we report on experiments with two eye-tracking corpora of naturalistic reading and two language models (BERT and GPT-2). In all experiments, we test effects of a broad spectrum of features for predicting human reading behavior that fall into five categories (syntactic complexity, lexical richness, register-based multiword combinations, readability and psycholinguistic word properties). Our experiments show that both the features included and the architecture of the transformer-based language models play a role in predicting multiple eye-tracking measures during naturalistic reading. We also report the results of experiments aimed at determining the relative importance of features from different groups using SP-LIME.