 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoK: Enhancing Cryptographic Collaborative Learning with Differential Privacy
Jan 14, 2026In collaborative learning (CL), multiple parties jointly train a machine learning model on their private datasets. However, data can not be shared directly due to privacy concerns. To ensure input confidentiality, cryptographic techniques, e.g., multi-party computation (MPC), enable training on encrypted data. Yet, even securely trained models are vulnerable to inference attacks aiming to extract memorized data from model outputs. To ensure output privacy and mitigate inference attacks, differential privacy (DP) injects calibrated noise during training. While cryptography and DP offer complementary guarantees, combining them efficiently for cryptographic and differentially private CL (CPCL) is challenging. Cryptography incurs performance overheads, while DP degrades accuracy, creating a privacy-accuracy-performance trade-off that needs careful design considerations. This work systematizes the CPCL landscape. We introduce a unified framework that generalizes common phases across CPCL paradigms, and identify secure noise sampling as the foundational phase to achieve CPCL. We analyze trade-offs of different secure noise sampling techniques, noise types, and DP mechanisms discussing their implementation challenges and evaluating their accuracy and cryptographic overhead across CPCL paradigms. Additionally, we implement identified secure noise sampling options in MPC and evaluate their computation and communication costs in WAN and LAN. Finally, we propose future research directions based on identified key observations, gaps and possible enhancements in the literature.
Differentially Private Language Models for Secure Data Sharing
Oct 26, 2022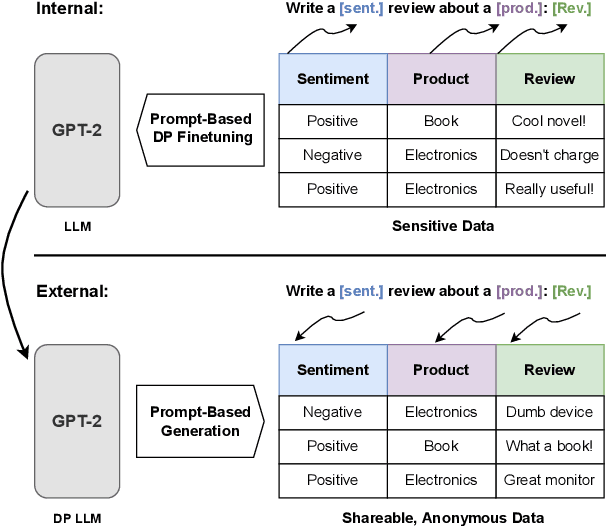
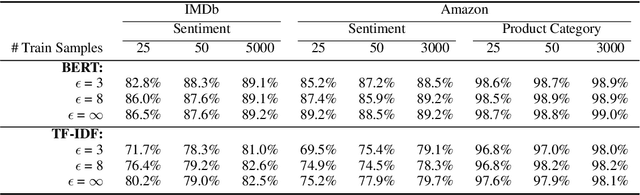

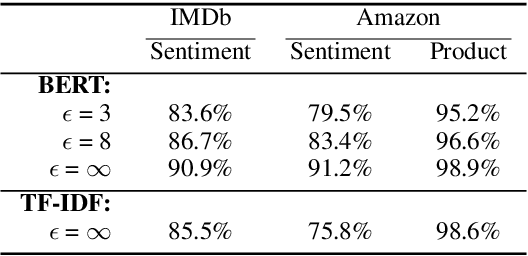
To protect the privacy of individuals whose data is being shared, it is of high importance to develop methods allowing researchers and companies to release textual data while providing formal privacy guarantees to its originators. In the field of NLP, substantial efforts have been directed at building mechanisms following the framework of local differential privacy, thereby anonymizing individual text samples before releasing them. In practice, these approaches are often dissatisfying in terms of the quality of their output language due to the strong noise required for local differential privacy. In this paper, we approach the problem at hand using global differential privacy, particularly by training a generative language model in a differentially private manner and consequently sampling data from it. Using natural language prompts and a new prompt-mismatch loss, we are able to create highly accurate and fluent textual datasets taking on specific desired attributes such as sentiment or topic and resembling statistical properties of the training data. We perform thorough experiments indicating that our synthetic datasets do not leak information from our original data and are of high language quality and highly suitable for training models for further analysis on real-world data. Notably, we also demonstrate that training classifiers on private synthetic data outperforms directly training classifiers on real data with DP-SGD.
The Limits of Word Level Differential Privacy
May 02, 2022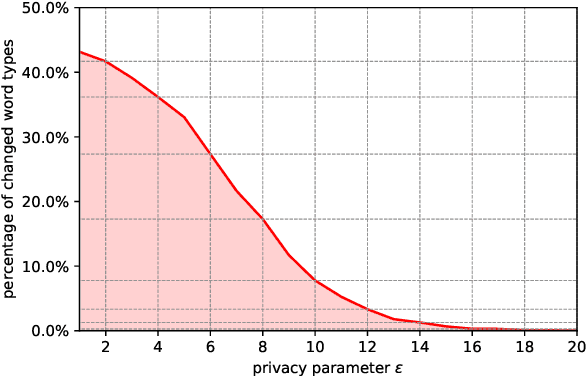
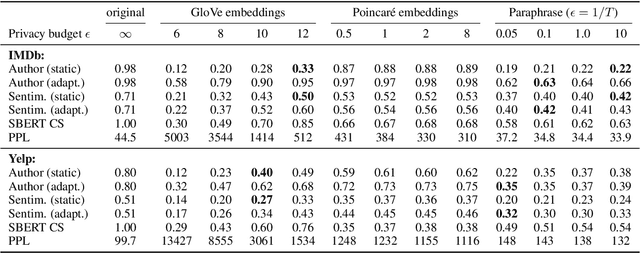
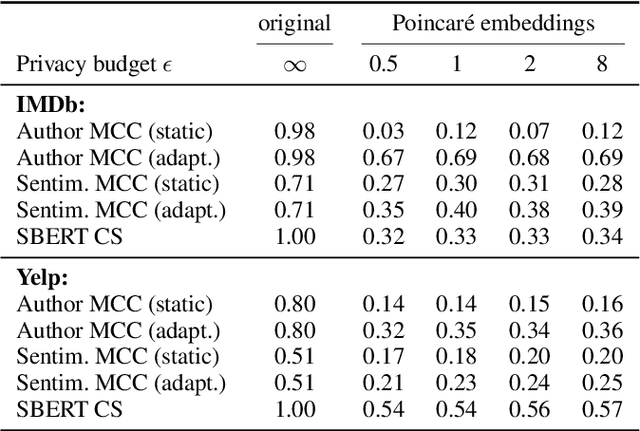
As the issues of privacy and trust are receiving increasing attention within the research community, various attempts have been made to anonymize textual data. A significant subset of these approaches incorporate differentially private mechanisms to perturb word embeddings, thus replacing individual words in a sentence. While these methods represent very important contributions, have various advantages over other techniques and do show anonymization capabilities, they have several shortcomings. In this paper, we investigate these weaknesses and demonstrate significant mathematical constraints diminishing the theoretical privacy guarantee as well as major practical shortcomings with regard to the protection against deanonymization attacks, the preservation of content of the original sentences as well as the quality of the language output. Finally, we propose a new method for text anonymization based on transformer based language models fine-tuned for paraphrasing that circumvents most of the identified weaknesses and also offers a formal privacy guarantee. We evaluate the performance of our method via thorough experimentation and demonstrate superior performance over the discussed mechanisms.