 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Trade-Off Between Transparency and Security in Adversarial Machine Learning
Nov 14, 2025Transparency and security are both central to Responsible AI, but they may conflict in adversarial settings. We investigate the strategic effect of transparency for agents through the lens of transferable adversarial example attacks. In transferable adversarial example attacks, attackers maliciously perturb their inputs using surrogate models to fool a defender's target model. These models can be defended or undefended, with both players having to decide which to use. Using a large-scale empirical evaluation of nine attacks across 181 models, we find that attackers are more successful when they match the defender's decision; hence, obscurity could be beneficial to the defender. With game theory, we analyze this trade-off between transparency and security by modeling this problem as both a Nash game and a Stackelberg game, and comparing the expected outcomes. Our analysis confirms that only knowing whether a defender's model is defended or not can sometimes be enough to damage its security. This result serves as an indicator of the general trade-off between transparency and security, suggesting that transparency in AI systems can be at odds with security. Beyond adversarial machine learning, our work illustrates how game-theoretic reasoning can uncover conflicts between transparency and security.
Hammer and Anvil: A Principled Defense Against Backdoors in Federated Learning
Sep 09, 2025Federated Learning is a distributed learning technique in which multiple clients cooperate to train a machine learning model. Distributed settings facilitate backdoor attacks by malicious clients, who can embed malicious behaviors into the model during their participation in the training process. These malicious behaviors are activated during inference by a specific trigger. No defense against backdoor attacks has stood the test of time, especially against adaptive attackers, a powerful but not fully explored category of attackers. In this work, we first devise a new adaptive adversary that surpasses existing adversaries in capabilities, yielding attacks that only require one or two malicious clients out of 20 to break existing state-of-the-art defenses. Then, we present Hammer and Anvil, a principled defense approach that combines two defenses orthogonal in their underlying principle to produce a combined defense that, given the right set of parameters, must succeed against any attack. We show that our best combined defense, Krum+, is successful against our new adaptive adversary and state-of-the-art attacks.
Relative Bias: A Comparative Framework for Quantifying Bias in LLMs
May 22, 2025

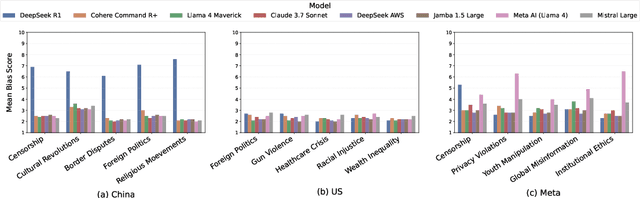

The growing deployment of large language models (LLMs) has amplified concerns regarding their inherent biases, raising critical questions about their fairness, safety, and societal impact. However, quantifying LLM bias remains a fundamental challenge, complicated by the ambiguity of what "bias" entails. This challenge grows as new models emerge rapidly and gain widespread use, while introducing potential biases that have not been systematically assessed. In this paper, we propose the Relative Bias framework, a method designed to assess how an LLM's behavior deviates from other LLMs within a specified target domain. We introduce two complementary methodologies: (1) Embedding Transformation analysis, which captures relative bias patterns through sentence representations over the embedding space, and (2) LLM-as-a-Judge, which employs a language model to evaluate outputs comparatively. Applying our framework to several case studies on bias and alignment scenarios following by statistical tests for validation, we find strong alignment between the two scoring methods, offering a systematic, scalable, and statistically grounded approach for comparative bias analysis in LLMs.
Privacy-Preserving Vertical K-Means Clustering
Apr 10, 2025



Clustering is a fundamental data processing task used for grouping records based on one or more features. In the vertically partitioned setting, data is distributed among entities, with each holding only a subset of those features. A key challenge in this scenario is that computing distances between records requires access to all distributed features, which may be privacy-sensitive and cannot be directly shared with other parties. The goal is to compute the joint clusters while preserving the privacy of each entity's dataset. Existing solutions using secret sharing or garbled circuits implement privacy-preserving variants of Lloyd's algorithm but incur high communication costs, scaling as O(nkt), where n is the number of data points, k the number of clusters, and t the number of rounds. These methods become impractical for large datasets or several parties, limiting their use to LAN settings only. On the other hand, a different line of solutions rely on differential privacy (DP) to outsource the local features of the parties to a central server. However, they often significantly degrade the utility of the clustering outcome due to excessive noise. In this work, we propose a novel solution based on homomorphic encryption and DP, reducing communication complexity to O(n+kt). In our method, parties securely outsource their features once, allowing a computing party to perform clustering operations under encryption. DP is applied only to the clusters' centroids, ensuring privacy with minimal impact on utility. Our solution clusters 100,000 two-dimensional points into five clusters using only 73MB of communication, compared to 101GB for existing works, and completes in just under 3 minutes on a 100Mbps network, whereas existing works take over 1 day. This makes our solution practical even for WAN deployments, all while maintaining accuracy comparable to plaintext k-means algorithms.
FastLloyd: Federated, Accurate, Secure, and Tunable $k$-Means Clustering with Differential Privacy
May 03, 2024We study the problem of privacy-preserving $k$-means clustering in the horizontally federated setting. Existing federated approaches using secure computation, suffer from substantial overheads and do not offer output privacy. At the same time, differentially private (DP) $k$-means algorithms assume a trusted central curator and do not extend to federated settings. Naively combining the secure and DP solutions results in a protocol with impractical overhead. Instead, our work provides enhancements to both the DP and secure computation components, resulting in a design that is faster, more private, and more accurate than previous work. By utilizing the computational DP model, we design a lightweight, secure aggregation-based approach that achieves four orders of magnitude speed-up over state-of-the-art related work. Furthermore, we not only maintain the utility of the state-of-the-art in the central model of DP, but we improve the utility further by taking advantage of constrained clustering techniques.
SoK: Analyzing Adversarial Examples: A Framework to Study Adversary Knowledge
Feb 22, 2024Adversarial examples are malicious inputs to machine learning models that trigger a misclassification. This type of attack has been studied for close to a decade, and we find that there is a lack of study and formalization of adversary knowledge when mounting attacks. This has yielded a complex space of attack research with hard-to-compare threat models and attacks. We focus on the image classification domain and provide a theoretical framework to study adversary knowledge inspired by work in order theory. We present an adversarial example game, inspired by cryptographic games, to standardize attacks. We survey recent attacks in the image classification domain and classify their adversary's knowledge in our framework. From this systematization, we compile results that both confirm existing beliefs about adversary knowledge, such as the potency of information about the attacked model as well as allow us to derive new conclusions on the difficulty associated with the white-box and transferable threat models, for example, that transferable attacks might not be as difficult as previously thought.
Universal Backdoor Attacks
Nov 30, 2023



Web-scraped datasets are vulnerable to data poisoning, which can be used for backdooring deep image classifiers during training. Since training on large datasets is expensive, a model is trained once and re-used many times. Unlike adversarial examples, backdoor attacks often target specific classes rather than any class learned by the model. One might expect that targeting many classes through a naive composition of attacks vastly increases the number of poison samples. We show this is not necessarily true and more efficient, universal data poisoning attacks exist that allow controlling misclassifications from any source class into any target class with a small increase in poison samples. Our idea is to generate triggers with salient characteristics that the model can learn. The triggers we craft exploit a phenomenon we call inter-class poison transferability, where learning a trigger from one class makes the model more vulnerable to learning triggers for other classes. We demonstrate the effectiveness and robustness of our universal backdoor attacks by controlling models with up to 6,000 classes while poisoning only 0.15% of the training dataset.
Leveraging Optimization for Adaptive Attacks on Image Watermarks
Sep 29, 2023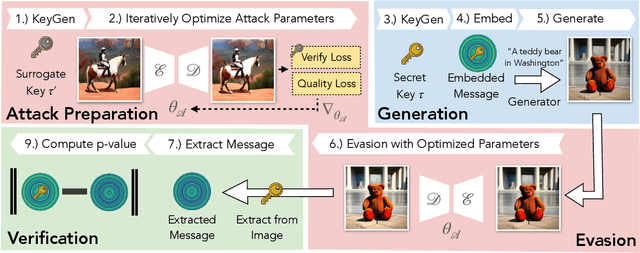
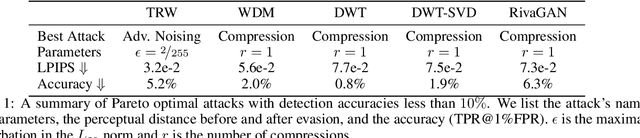
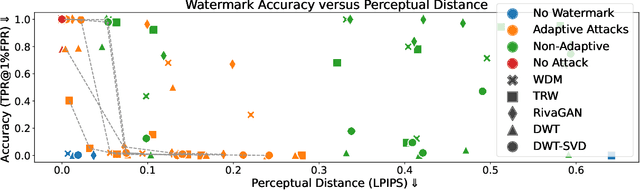
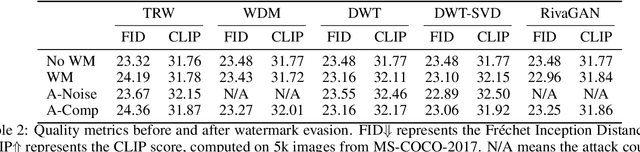
Untrustworthy users can misuse image generators to synthesize high-quality deepfakes and engage in online spam or disinformation campaigns. Watermarking deters misuse by marking generated content with a hidden message, enabling its detection using a secret watermarking key. A core security property of watermarking is robustness, which states that an attacker can only evade detection by substantially degrading image quality. Assessing robustness requires designing an adaptive attack for the specific watermarking algorithm. A challenge when evaluating watermarking algorithms and their (adaptive) attacks is to determine whether an adaptive attack is optimal, i.e., it is the best possible attack. We solve this problem by defining an objective function and then approach adaptive attacks as an optimization problem. The core idea of our adaptive attacks is to replicate secret watermarking keys locally by creating surrogate keys that are differentiable and can be used to optimize the attack's parameters. We demonstrate for Stable Diffusion models that such an attacker can break all five surveyed watermarking methods at negligible degradation in image quality. These findings emphasize the need for more rigorous robustness testing against adaptive, learnable attackers.
Identifying and Mitigating the Security Risks of Generative AI
Aug 28, 2023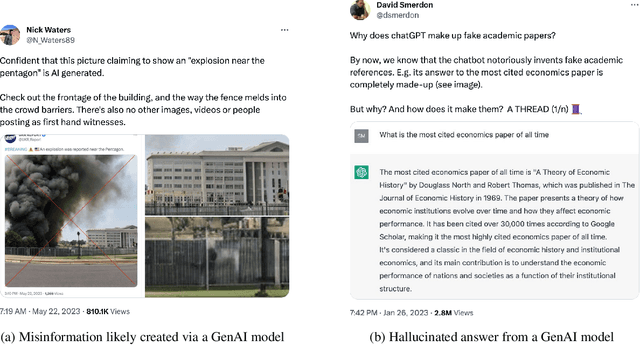
Every major technical invention resurfaces the dual-use dilemma -- the new technology has the potential to be used for good as well as for harm. Generative AI (GenAI) techniques, such as large language models (LLMs) and diffusion models, have shown remarkable capabilities (e.g., in-context learning, code-completion, and text-to-image generation and editing). However, GenAI can be used just as well by attackers to generate new attacks and increase the velocity and efficacy of existing attacks. This paper reports the findings of a workshop held at Google (co-organized by Stanford University and the University of Wisconsin-Madison) on the dual-use dilemma posed by GenAI. This paper is not meant to be comprehensive, but is rather an attempt to synthesize some of the interesting findings from the workshop. We discuss short-term and long-term goals for the community on this topic. We hope this paper provides both a launching point for a discussion on this important topic as well as interesting problems that the research community can work to address.
Backdooring Textual Inversion for Concept Censorship
Aug 23, 2023



Recent years have witnessed success in AIGC (AI Generated Content). People can make use of a pre-trained diffusion model to generate images of high quality or freely modify existing pictures with only prompts in nature language. More excitingly, the emerging personalization techniques make it feasible to create specific-desired images with only a few images as references. However, this induces severe threats if such advanced techniques are misused by malicious users, such as spreading fake news or defaming individual reputations. Thus, it is necessary to regulate personalization models (i.e., concept censorship) for their development and advancement. In this paper, we focus on the personalization technique dubbed Textual Inversion (TI), which is becoming prevailing for its lightweight nature and excellent performance. TI crafts the word embedding that contains detailed information about a specific object. Users can easily download the word embedding from public websites like Civitai and add it to their own stable diffusion model without fine-tuning for personalization. To achieve the concept censorship of a TI model, we propose leveraging the backdoor technique for good by injecting backdoors into the Textual Inversion embeddings. Briefly, we select some sensitive words as triggers during the training of TI, which will be censored for normal use. In the subsequent generation stage, if the triggers are combined with personalized embeddings as final prompts, the model will output a pre-defined target image rather than images including the desired malicious concept. To demonstrate the effectiveness of our approach, we conduct extensive experiments on Stable Diffusion, a prevailing open-sourced text-to-image model. Our code, data, and results are available at https://concept-censorship.github.io.