 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWho Pays the Price? Stakeholder-Centric Prompt Injection Benchmarking for Real-world Web Agents
Jun 11, 2026Web agents driven by large language models (LLMs) are increasingly deployed in real-world environments, where they operate over untrusted web content and execute actions with direct consequences. This makes them vulnerable to prompt-injection attacks, in which seemingly benign content embeds adversarial instructions that manipulate agent behaviour. Existing security benchmarks adopt an \textit{attack-centric} perspective, focusing on the technical feasibility of injections while overlooking the nuanced distribution of resulting harms. In practice, however, prompt-injection risk is victim-dependent: a single exploit can produce asymmetric consequences for different stakeholders, and the same attack pattern may exhibit substantially different effectiveness depending on whom it targets. To capture these properties, we introduce \textbf{\sysname}, a \textit{stakeholder-centric} benchmark to systematically categorize and attribute harm in real-world web agent systems. It distinguishes between affected entities (e.g., user, seller, platform), decomposes the attacks into concrete objectives, and evaluates each case with complementary outcome- and process-level metrics. Our results reveal substantial and heterogeneous vulnerabilities: not a single attack objective is reliably resisted by current agents, and failures distribute across qualitatively distinct modes ranging from \emph{stealthy parasitism} (attack succeeds without disrupting the user's delegated task) to \emph{misaligned disruption} (task disrupted without attack success) and \emph{compounded failure} (both adversarial objective and task integrity simultaneously violated). These patterns are missed by conventional evaluation, highlighting the need for stakeholder-aware assessment of LLM-based agents in real-world deployments. Benchmark is available at https://github.com/StakeBench/SBC.
QiMeng-CodeV-SVA: Training Specialized LLMs for Hardware Assertion Generation via RTL-Grounded Bidirectional Data Synthesis
Mar 15, 2026SystemVerilog Assertions (SVAs) are crucial for hardware verification. Recent studies leverage general-purpose LLMs to translate natural language properties to SVAs (NL2SVA), but they perform poorly due to limited data. We propose a data synthesis framework to tackle two challenges: the scarcity of high-quality real-world SVA corpora and the lack of reliable methods to determine NL-SVA semantic equivalence. For the former, large-scale open-source RTLs are used to guide LLMs to generate real-world SVAs; for the latter, bidirectional translation serves as a data selection method. With the synthesized data, we train CodeV-SVA, a series of SVA generation models. Notably, CodeV-SVA-14B achieves 75.8% on NL2SVA-Human and 84.0% on NL2SVA-Machine in Func.@1, matching or exceeding advanced LLMs like GPT-5 and DeepSeek-R1.
StepFun-Prover Preview: Let's Think and Verify Step by Step
Jul 27, 2025We present StepFun-Prover Preview, a large language model designed for formal theorem proving through tool-integrated reasoning. Using a reinforcement learning pipeline that incorporates tool-based interactions, StepFun-Prover can achieve strong performance in generating Lean 4 proofs with minimal sampling. Our approach enables the model to emulate human-like problem-solving strategies by iteratively refining proofs based on real-time environment feedback. On the miniF2F-test benchmark, StepFun-Prover achieves a pass@1 success rate of $70.0\%$. Beyond advancing benchmark performance, we introduce an end-to-end training framework for developing tool-integrated reasoning models, offering a promising direction for automated theorem proving and Math AI assistant.
CodeV-R1: Reasoning-Enhanced Verilog Generation
May 30, 2025Large language models (LLMs) trained via reinforcement learning with verifiable reward (RLVR) have achieved breakthroughs on tasks with explicit, automatable verification, such as software programming and mathematical problems. Extending RLVR to electronic design automation (EDA), especially automatically generating hardware description languages (HDLs) like Verilog from natural-language (NL) specifications, however, poses three key challenges: the lack of automated and accurate verification environments, the scarcity of high-quality NL-code pairs, and the prohibitive computation cost of RLVR. To this end, we introduce CodeV-R1, an RLVR framework for training Verilog generation LLMs. First, we develop a rule-based testbench generator that performs robust equivalence checking against golden references. Second, we propose a round-trip data synthesis method that pairs open-source Verilog snippets with LLM-generated NL descriptions, verifies code-NL-code consistency via the generated testbench, and filters out inequivalent examples to yield a high-quality dataset. Third, we employ a two-stage "distill-then-RL" training pipeline: distillation for the cold start of reasoning abilities, followed by adaptive DAPO, our novel RLVR algorithm that can reduce training cost by adaptively adjusting sampling rate. The resulting model, CodeV-R1-7B, achieves 68.6% and 72.9% pass@1 on VerilogEval v2 and RTLLM v1.1, respectively, surpassing prior state-of-the-art by 12~20%, while matching or even exceeding the performance of 671B DeepSeek-R1. We will release our model, training pipeline, and dataset to facilitate research in EDA and LLM communities.
Cost-Optimal Grouped-Query Attention for Long-Context LLMs
Mar 12, 2025Building effective and efficient Transformer-based large language models (LLMs) has recently become a research focus, requiring maximizing model language capabilities and minimizing training and deployment costs. Existing efforts have primarily described complex relationships among model performance, parameter size, and data size, as well as searched for the optimal compute allocation to train LLMs. However, they overlook the impacts of context length and attention head configuration (the number of query and key-value heads in grouped-query attention) on training and inference. In this paper, we systematically compare models with different parameter sizes, context lengths, and attention head configurations in terms of model performance, computational cost, and memory cost. Then, we extend the existing scaling methods, which are based solely on parameter size and training compute, to guide the construction of cost-optimal LLMs during both training and inference. Our quantitative scaling studies show that, when processing sufficiently long sequences, a larger model with fewer attention heads can achieve a lower loss while incurring lower computational and memory costs. Our findings provide valuable insights for developing practical LLMs, especially in long-context processing scenarios. We will publicly release our code and data.
Functional connectomes of neural networks
Dec 18, 2024The human brain is a complex system, and understanding its mechanisms has been a long-standing challenge in neuroscience. The study of the functional connectome, which maps the functional connections between different brain regions, has provided valuable insights through various advanced analysis techniques developed over the years. Similarly, neural networks, inspired by the brain's architecture, have achieved notable success in diverse applications but are often noted for their lack of interpretability. In this paper, we propose a novel approach that bridges neural networks and human brain functions by leveraging brain-inspired techniques. Our approach, grounded in the insights from the functional connectome, offers scalable ways to characterize topology of large neural networks using stable statistical and machine learning techniques. Our empirical analysis demonstrates its capability to enhance the interpretability of neural networks, providing a deeper understanding of their underlying mechanisms.
InverseCoder: Unleashing the Power of Instruction-Tuned Code LLMs with Inverse-Instruct
Jul 08, 2024Recent advancements in open-source code large language models (LLMs) have demonstrated remarkable coding abilities by fine-tuning on the data generated from powerful closed-source LLMs such as GPT-3.5 and GPT-4 for instruction tuning. This paper explores how to further improve an instruction-tuned code LLM by generating data from itself rather than querying closed-source LLMs. Our key observation is the misalignment between the translation of formal and informal languages: translating formal language (i.e., code) to informal language (i.e., natural language) is more straightforward than the reverse. Based on this observation, we propose INVERSE-INSTRUCT, which summarizes instructions from code snippets instead of the reverse. Specifically, given an instruction tuning corpus for code and the resulting instruction-tuned code LLM, we ask the code LLM to generate additional high-quality instructions for the original corpus through code summarization and self-evaluation. Then, we fine-tune the base LLM on the combination of the original corpus and the self-generated one, which yields a stronger instruction-tuned LLM. We present a series of code LLMs named InverseCoder, which surpasses the performance of the original code LLMs on a wide range of benchmarks, including Python text-to-code generation, multilingual coding, and data-science code generation.
MMToM-QA: Multimodal Theory of Mind Question Answering
Jan 16, 2024



Theory of Mind (ToM), the ability to understand people's minds, is an essential ingredient for developing machines with human-level social intelligence. Recent machine learning models, particularly large language models, seem to show some aspects of ToM understanding. However, existing ToM benchmarks use unimodal datasets - either video or text. Human ToM, on the other hand, is more than video or text understanding. People can flexibly reason about another person's mind based on conceptual representations (e.g., goals, beliefs, plans) extracted from any available data, which can include visual cues, linguistic narratives, or both. To address this, we introduce a multimodal Theory of Mind question answering (MMToM-QA) benchmark. MMToM-QA comprehensively evaluates machine ToM both on multimodal data and on different kinds of unimodal data about a person's activity in a household environment. To engineer multimodal ToM capacity, we propose a novel method, BIP-ALM (Bayesian Inverse Planning Accelerated by Language Models). BIP-ALM extracts unified representations from multimodal data and utilizes language models for scalable Bayesian inverse planning. We conducted a systematic comparison of human performance, BIP-ALM, and state-of-the-art models, including GPT-4. The experiments demonstrate that large language models and large multimodal models still lack robust ToM capacity. BIP-ALM, on the other hand, shows promising results, by leveraging the power of both model-based mental inference and language models.
Reinforcement Learning-assisted Evolutionary Algorithm: A Survey and Research Opportunities
Aug 28, 2023


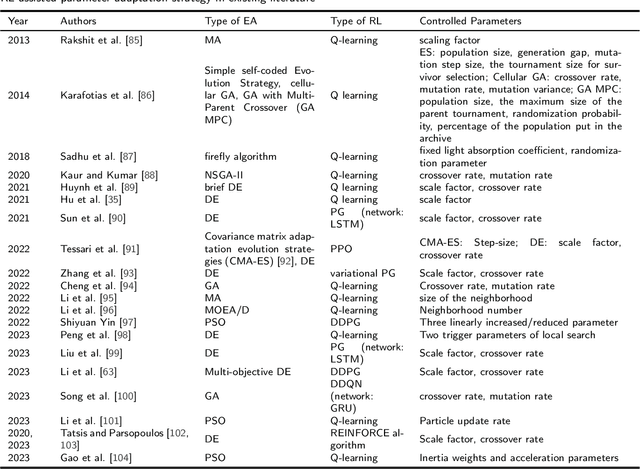
Evolutionary algorithms (EA), a class of stochastic search methods based on the principles of natural evolution, have received widespread acclaim for their exceptional performance in various real-world optimization problems. While researchers worldwide have proposed a wide variety of EAs, certain limitations remain, such as slow convergence speed and poor generalization capabilities. Consequently, numerous scholars actively explore improvements to algorithmic structures, operators, search patterns, etc., to enhance their optimization performance. Reinforcement learning (RL) integrated as a component in the EA framework has demonstrated superior performance in recent years. This paper presents a comprehensive survey on integrating reinforcement learning into the evolutionary algorithm, referred to as reinforcement learning-assisted evolutionary algorithm (RL-EA). We begin with the conceptual outlines of reinforcement learning and the evolutionary algorithm. We then provide a taxonomy of RL-EA. Subsequently, we discuss the RL-EA integration method, the RL-assisted strategy adopted by RL-EA, and its applications according to the existing literature. The RL-assisted procedure is divided according to the implemented functions including solution generation, learnable objective function, algorithm/operator/sub-population selection, parameter adaptation, and other strategies. Finally, we analyze potential directions for future research. This survey serves as a rich resource for researchers interested in RL-EA as it overviews the current state-of-the-art and highlights the associated challenges. By leveraging this survey, readers can swiftly gain insights into RL-EA to develop efficient algorithms, thereby fostering further advancements in this emerging field.
Backdooring Textual Inversion for Concept Censorship
Aug 23, 2023



Recent years have witnessed success in AIGC (AI Generated Content). People can make use of a pre-trained diffusion model to generate images of high quality or freely modify existing pictures with only prompts in nature language. More excitingly, the emerging personalization techniques make it feasible to create specific-desired images with only a few images as references. However, this induces severe threats if such advanced techniques are misused by malicious users, such as spreading fake news or defaming individual reputations. Thus, it is necessary to regulate personalization models (i.e., concept censorship) for their development and advancement. In this paper, we focus on the personalization technique dubbed Textual Inversion (TI), which is becoming prevailing for its lightweight nature and excellent performance. TI crafts the word embedding that contains detailed information about a specific object. Users can easily download the word embedding from public websites like Civitai and add it to their own stable diffusion model without fine-tuning for personalization. To achieve the concept censorship of a TI model, we propose leveraging the backdoor technique for good by injecting backdoors into the Textual Inversion embeddings. Briefly, we select some sensitive words as triggers during the training of TI, which will be censored for normal use. In the subsequent generation stage, if the triggers are combined with personalized embeddings as final prompts, the model will output a pre-defined target image rather than images including the desired malicious concept. To demonstrate the effectiveness of our approach, we conduct extensive experiments on Stable Diffusion, a prevailing open-sourced text-to-image model. Our code, data, and results are available at https://concept-censorship.github.io.