 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSegmental Advantage Estimation: Enhancing PPO for Long-Context LLM Training
Jan 12, 2026Training Large Language Models (LLMs) for reasoning tasks is increasingly driven by Reinforcement Learning with Verifiable Rewards (RLVR), where Proximal Policy Optimization (PPO) provides a principled framework for stable policy updates. However, the practical application of PPO is hindered by unreliable advantage estimation in the sparse-reward RLVR regime. This issue arises because the sparse rewards in RLVR lead to inaccurate intermediate value predictions, which in turn introduce significant bias when aggregated at every token by Generalized Advantage Estimation (GAE). To address this, we introduce Segmental Advantage Estimation (SAE), which mitigates the bias that GAE can incur in RLVR. Our key insight is that aggregating $n$-step advantages at every token(as in GAE) is unnecessary and often introduces excessive bias, since individual tokens carry minimal information. Instead, SAE first partitions the generated sequence into coherent sub-segments using low-probability tokens as heuristic boundaries. It then selectively computes variance-reduced advantage estimates only from these information-rich segment transitions, effectively filtering out noise from intermediate tokens. Our experiments demonstrate that SAE achieves superior performance, with marked improvements in final scores, training stability, and sample efficiency. These gains are shown to be consistent across multiple model sizes, and a correlation analysis confirms that our proposed advantage estimator achieves a higher correlation with an approximate ground-truth advantage, justifying its superior performance.
CodeV: Empowering LLMs for Verilog Generation through Multi-Level Summarization
Jul 16, 2024The increasing complexity and high costs associated with modern processor design have led to a surge in demand for processor design automation. Instruction-tuned large language models (LLMs) have demonstrated remarkable performance in automatically generating code for general-purpose programming languages like Python. However, these methods fail on hardware description languages (HDLs) like Verilog due to the scarcity of high-quality instruction tuning data, as even advanced LLMs like GPT-3.5 exhibit limited performance on Verilog generation. Regarding this issue, we observe that (1) Verilog code collected from the real world has higher quality than those generated by LLMs. (2) LLMs like GPT-3.5 excel in summarizing Verilog code rather than generating it. Based on these observations, this paper introduces CodeV, a series of open-source instruction-tuned Verilog generation LLMs. Instead of generating descriptions first and then getting the corresponding code from advanced LLMs, we prompt the LLM with Verilog code and let the LLM generate the corresponding natural language description by multi-level summarization. Experimental results show that CodeV relatively surpasses the previous open-source SOTA by 14.4% (BetterV in VerilogEval) and 11.3% (RTLCoder in RTLLM) respectively, and also relatively outperforms previous commercial SOTA GPT-4 by 22.1% in VerilogEval.
InverseCoder: Unleashing the Power of Instruction-Tuned Code LLMs with Inverse-Instruct
Jul 08, 2024Recent advancements in open-source code large language models (LLMs) have demonstrated remarkable coding abilities by fine-tuning on the data generated from powerful closed-source LLMs such as GPT-3.5 and GPT-4 for instruction tuning. This paper explores how to further improve an instruction-tuned code LLM by generating data from itself rather than querying closed-source LLMs. Our key observation is the misalignment between the translation of formal and informal languages: translating formal language (i.e., code) to informal language (i.e., natural language) is more straightforward than the reverse. Based on this observation, we propose INVERSE-INSTRUCT, which summarizes instructions from code snippets instead of the reverse. Specifically, given an instruction tuning corpus for code and the resulting instruction-tuned code LLM, we ask the code LLM to generate additional high-quality instructions for the original corpus through code summarization and self-evaluation. Then, we fine-tune the base LLM on the combination of the original corpus and the self-generated one, which yields a stronger instruction-tuned LLM. We present a series of code LLMs named InverseCoder, which surpasses the performance of the original code LLMs on a wide range of benchmarks, including Python text-to-code generation, multilingual coding, and data-science code generation.
ANPL: Compiling Natural Programs with Interactive Decomposition
May 29, 2023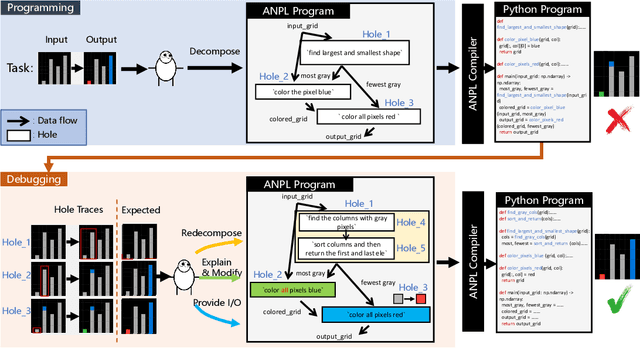

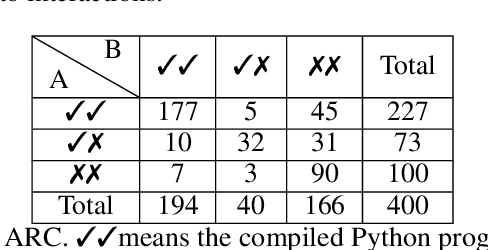
The advents of Large Language Models (LLMs) have shown promise in augmenting programming using natural interactions. However, while LLMs are proficient in compiling common usage patterns into a programming language, e.g., Python, it remains a challenge how to edit and debug an LLM-generated program. We introduce ANPL, a programming system that allows users to decompose user-specific tasks. In an ANPL program, a user can directly manipulate sketch, which specifies the data flow of the generated program. The user annotates the modules, or hole with natural language descriptions offloading the expensive task of generating functionalities to the LLM. Given an ANPL program, the ANPL compiler generates a cohesive Python program that implements the functionalities in hole, while respecting the dataflows specified in sketch. We deploy ANPL on the Abstraction and Reasoning Corpus (ARC), a set of unique tasks that are challenging for state-of-the-art AI systems, showing it outperforms baseline programming systems that (a) without the ability to decompose tasks interactively and (b) without the guarantee that the modules can be correctly composed together. We obtain a dataset consisting of 300/400 ARC tasks that were successfully decomposed and grounded in Python, providing valuable insights into how humans decompose programmatic tasks. See the dataset at https://iprc-dip.github.io/DARC.
Online Symbolic Regression with Informative Query
Feb 21, 2023Symbolic regression, the task of extracting mathematical expressions from the observed data $\{ \vx_i, y_i \}$, plays a crucial role in scientific discovery. Despite the promising performance of existing methods, most of them conduct symbolic regression in an \textit{offline} setting. That is, they treat the observed data points as given ones that are simply sampled from uniform distributions without exploring the expressive potential of data. However, for real-world scientific problems, the data used for symbolic regression are usually actively obtained by doing experiments, which is an \textit{online} setting. Thus, how to obtain informative data that can facilitate the symbolic regression process is an important problem that remains challenging. In this paper, we propose QUOSR, a \textbf{qu}ery-based framework for \textbf{o}nline \textbf{s}ymbolic \textbf{r}egression that can automatically obtain informative data in an iterative manner. Specifically, at each step, QUOSR receives historical data points, generates new $\vx$, and then queries the symbolic expression to get the corresponding $y$, where the $(\vx, y)$ serves as new data points. This process repeats until the maximum number of query steps is reached. To make the generated data points informative, we implement the framework with a neural network and train it by maximizing the mutual information between generated data points and the target expression. Through comprehensive experiments, we show that QUOSR can facilitate modern symbolic regression methods by generating informative data.