 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRTLSeek: Boosting the LLM-Based RTL Generation with Multi-Stage Diversity-Oriented Reinforcement Learning
Mar 29, 2026Register Transfer Level (RTL) design translates high-level specifications into hardware using HDLs such as Verilog. Although LLM-based RTL generation is promising, the scarcity of functionally verifiable high-quality data limits both accuracy and diversity. Existing post-training typically produces a single HDL implementation per specification, lacking awareness of RTL variations needed for different design goals. We propose RTLSeek, a post-training paradigm that applies rule-based Diversity-Oriented Reinforcement Learning to improve RTL correctness and diversity. Our Diversity-Centric Multi-Objective Reward Scheduling integrates expert knowledge with EDA feedback, and a three-stage framework maximizes the utility of limited data. Experiments on the RTLLM benchmark show that RTLSeek surpasses prior methods, with ablation results confirming that encouraging broader design-space exploration improves RTL quality and achieves the principle of "the more generated, the better results." Implementation framework, including the dataset, source code, and model weights, is shown at https://anonymous.4open.science/r/DAC2026ID71-ACB4/.
CodeV: Empowering LLMs for Verilog Generation through Multi-Level Summarization
Jul 16, 2024The increasing complexity and high costs associated with modern processor design have led to a surge in demand for processor design automation. Instruction-tuned large language models (LLMs) have demonstrated remarkable performance in automatically generating code for general-purpose programming languages like Python. However, these methods fail on hardware description languages (HDLs) like Verilog due to the scarcity of high-quality instruction tuning data, as even advanced LLMs like GPT-3.5 exhibit limited performance on Verilog generation. Regarding this issue, we observe that (1) Verilog code collected from the real world has higher quality than those generated by LLMs. (2) LLMs like GPT-3.5 excel in summarizing Verilog code rather than generating it. Based on these observations, this paper introduces CodeV, a series of open-source instruction-tuned Verilog generation LLMs. Instead of generating descriptions first and then getting the corresponding code from advanced LLMs, we prompt the LLM with Verilog code and let the LLM generate the corresponding natural language description by multi-level summarization. Experimental results show that CodeV relatively surpasses the previous open-source SOTA by 14.4% (BetterV in VerilogEval) and 11.3% (RTLCoder in RTLLM) respectively, and also relatively outperforms previous commercial SOTA GPT-4 by 22.1% in VerilogEval.
TensorTEE: Unifying Heterogeneous TEE Granularity for Efficient Secure Collaborative Tensor Computing
Jul 12, 2024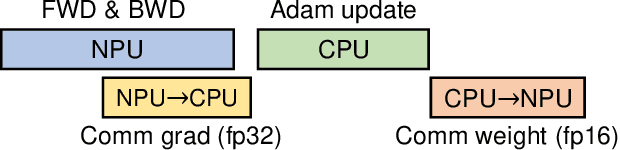
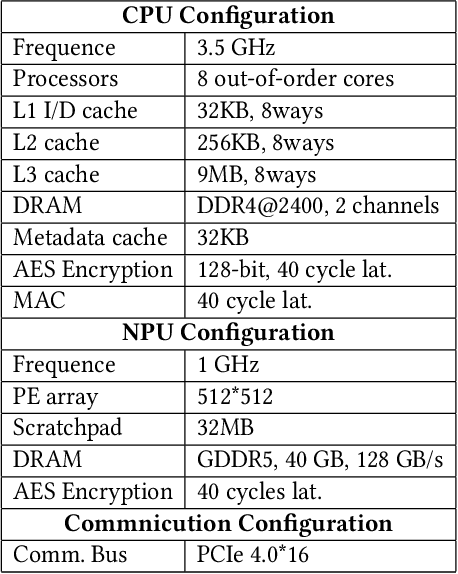
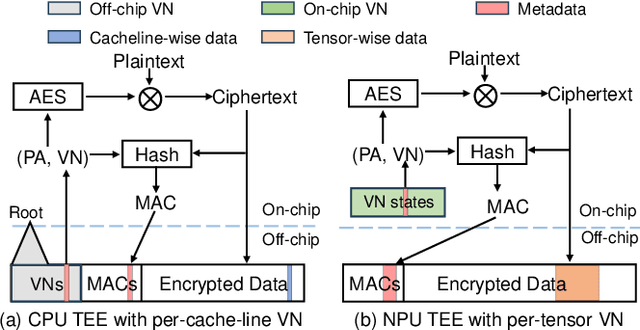
Heterogeneous collaborative computing with NPU and CPU has received widespread attention due to its substantial performance benefits. To ensure data confidentiality and integrity during computing, Trusted Execution Environments (TEE) is considered a promising solution because of its comparatively lower overhead. However, existing heterogeneous TEE designs are inefficient for collaborative computing due to fine and different memory granularities between CPU and NPU. 1) The cacheline granularity of CPU TEE intensifies memory pressure due to its extra memory access, and 2) the cacheline granularity MAC of NPU escalates the pressure on the limited memory storage. 3) Data transfer across heterogeneous enclaves relies on the transit of non-secure regions, resulting in cumbersome re-encryption and scheduling. To address these issues, we propose TensorTEE, a unified tensor-granularity heterogeneous TEE for efficient secure collaborative tensor computing. First, we virtually support tensor granularity in CPU TEE to eliminate the off-chip metadata access by detecting and maintaining tensor structures on-chip. Second, we propose tensor-granularity MAC management with predictive execution to avoid computational stalls while eliminating off-chip MAC storage and access. Moreover, based on the unified granularity, we enable direct data transfer without re-encryption and scheduling dilemmas. Our evaluation is built on enhanced Gem5 and a cycle-accurate NPU simulator. The results show that TensorTEE improves the performance of Large Language Model (LLM) training workloads by 4.0x compared to existing work and incurs only 2.1% overhead compared to non-secure training, offering a practical security assurance for LLM training.