 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCodeV: Empowering LLMs for Verilog Generation through Multi-Level Summarization
Jul 16, 2024The increasing complexity and high costs associated with modern processor design have led to a surge in demand for processor design automation. Instruction-tuned large language models (LLMs) have demonstrated remarkable performance in automatically generating code for general-purpose programming languages like Python. However, these methods fail on hardware description languages (HDLs) like Verilog due to the scarcity of high-quality instruction tuning data, as even advanced LLMs like GPT-3.5 exhibit limited performance on Verilog generation. Regarding this issue, we observe that (1) Verilog code collected from the real world has higher quality than those generated by LLMs. (2) LLMs like GPT-3.5 excel in summarizing Verilog code rather than generating it. Based on these observations, this paper introduces CodeV, a series of open-source instruction-tuned Verilog generation LLMs. Instead of generating descriptions first and then getting the corresponding code from advanced LLMs, we prompt the LLM with Verilog code and let the LLM generate the corresponding natural language description by multi-level summarization. Experimental results show that CodeV relatively surpasses the previous open-source SOTA by 14.4% (BetterV in VerilogEval) and 11.3% (RTLCoder in RTLLM) respectively, and also relatively outperforms previous commercial SOTA GPT-4 by 22.1% in VerilogEval.
Eden: A Unified Environment Framework for Booming Reinforcement Learning Algorithms
Sep 04, 2021

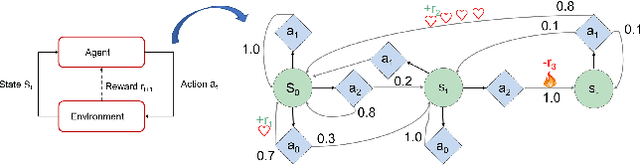

With AlphaGo defeats top human players, reinforcement learning(RL) algorithms have gradually become the code-base of building stronger artificial intelligence(AI). The RL algorithm design firstly needs to adapt to the specific environment, so the designed environment guides the rapid and profound development of RL algorithms. However, the existing environments, which can be divided into real world games and customized toy environments, have obvious shortcomings. For real world games, it is designed for human entertainment, and too much difficult for most of RL researchers. For customized toy environments, there is no widely accepted unified evaluation standard for all RL algorithms. Therefore, we introduce the first virtual user-friendly environment framework for RL. In this framework, the environment can be easily configured to realize all kinds of RL tasks in the mainstream research. Then all the mainstream state-of-the-art(SOTA) RL algorithms can be conveniently evaluated and compared. Therefore, our contributions mainly includes the following aspects: 1.single configured environment for all classification of SOTA RL algorithms; 2.combined environment of more than one classification RL algorithms; 3.the evaluation standard for all kinds of RL algorithms. With all these efforts, a possibility for breeding an AI with capability of general competency in a variety of tasks is provided, and maybe it will open up a new chapter for AI.