 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInverseCoder: Unleashing the Power of Instruction-Tuned Code LLMs with Inverse-Instruct
Jul 08, 2024Recent advancements in open-source code large language models (LLMs) have demonstrated remarkable coding abilities by fine-tuning on the data generated from powerful closed-source LLMs such as GPT-3.5 and GPT-4 for instruction tuning. This paper explores how to further improve an instruction-tuned code LLM by generating data from itself rather than querying closed-source LLMs. Our key observation is the misalignment between the translation of formal and informal languages: translating formal language (i.e., code) to informal language (i.e., natural language) is more straightforward than the reverse. Based on this observation, we propose INVERSE-INSTRUCT, which summarizes instructions from code snippets instead of the reverse. Specifically, given an instruction tuning corpus for code and the resulting instruction-tuned code LLM, we ask the code LLM to generate additional high-quality instructions for the original corpus through code summarization and self-evaluation. Then, we fine-tune the base LLM on the combination of the original corpus and the self-generated one, which yields a stronger instruction-tuned LLM. We present a series of code LLMs named InverseCoder, which surpasses the performance of the original code LLMs on a wide range of benchmarks, including Python text-to-code generation, multilingual coding, and data-science code generation.
Online Prototype Alignment for Few-shot Policy Transfer
Jun 12, 2023Domain adaptation in reinforcement learning (RL) mainly deals with the changes of observation when transferring the policy to a new environment. Many traditional approaches of domain adaptation in RL manage to learn a mapping function between the source and target domain in explicit or implicit ways. However, they typically require access to abundant data from the target domain. Besides, they often rely on visual clues to learn the mapping function and may fail when the source domain looks quite different from the target domain. To address these problems, we propose a novel framework Online Prototype Alignment (OPA) to learn the mapping function based on the functional similarity of elements and is able to achieve the few-shot policy transfer within only several episodes. The key insight of OPA is to introduce an exploration mechanism that can interact with the unseen elements of the target domain in an efficient and purposeful manner, and then connect them with the seen elements in the source domain according to their functionalities (instead of visual clues). Experimental results show that when the target domain looks visually different from the source domain, OPA can achieve better transfer performance even with much fewer samples from the target domain, outperforming prior methods.
Eden: A Unified Environment Framework for Booming Reinforcement Learning Algorithms
Sep 04, 2021

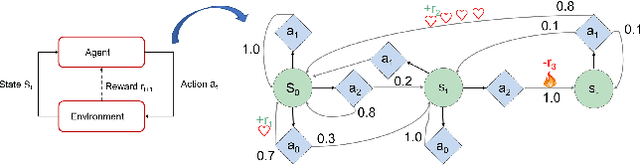

With AlphaGo defeats top human players, reinforcement learning(RL) algorithms have gradually become the code-base of building stronger artificial intelligence(AI). The RL algorithm design firstly needs to adapt to the specific environment, so the designed environment guides the rapid and profound development of RL algorithms. However, the existing environments, which can be divided into real world games and customized toy environments, have obvious shortcomings. For real world games, it is designed for human entertainment, and too much difficult for most of RL researchers. For customized toy environments, there is no widely accepted unified evaluation standard for all RL algorithms. Therefore, we introduce the first virtual user-friendly environment framework for RL. In this framework, the environment can be easily configured to realize all kinds of RL tasks in the mainstream research. Then all the mainstream state-of-the-art(SOTA) RL algorithms can be conveniently evaluated and compared. Therefore, our contributions mainly includes the following aspects: 1.single configured environment for all classification of SOTA RL algorithms; 2.combined environment of more than one classification RL algorithms; 3.the evaluation standard for all kinds of RL algorithms. With all these efforts, a possibility for breeding an AI with capability of general competency in a variety of tasks is provided, and maybe it will open up a new chapter for AI.