 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSegmental Advantage Estimation: Enhancing PPO for Long-Context LLM Training
Jan 12, 2026Training Large Language Models (LLMs) for reasoning tasks is increasingly driven by Reinforcement Learning with Verifiable Rewards (RLVR), where Proximal Policy Optimization (PPO) provides a principled framework for stable policy updates. However, the practical application of PPO is hindered by unreliable advantage estimation in the sparse-reward RLVR regime. This issue arises because the sparse rewards in RLVR lead to inaccurate intermediate value predictions, which in turn introduce significant bias when aggregated at every token by Generalized Advantage Estimation (GAE). To address this, we introduce Segmental Advantage Estimation (SAE), which mitigates the bias that GAE can incur in RLVR. Our key insight is that aggregating $n$-step advantages at every token(as in GAE) is unnecessary and often introduces excessive bias, since individual tokens carry minimal information. Instead, SAE first partitions the generated sequence into coherent sub-segments using low-probability tokens as heuristic boundaries. It then selectively computes variance-reduced advantage estimates only from these information-rich segment transitions, effectively filtering out noise from intermediate tokens. Our experiments demonstrate that SAE achieves superior performance, with marked improvements in final scores, training stability, and sample efficiency. These gains are shown to be consistent across multiple model sizes, and a correlation analysis confirms that our proposed advantage estimator achieves a higher correlation with an approximate ground-truth advantage, justifying its superior performance.
AT$^2$PO: Agentic Turn-based Policy Optimization via Tree Search
Jan 08, 2026LLM agents have emerged as powerful systems for tackling multi-turn tasks by interleaving internal reasoning and external tool interactions. Agentic Reinforcement Learning has recently drawn significant research attention as a critical post-training paradigm to further refine these capabilities. In this paper, we present AT$^2$PO (Agentic Turn-based Policy Optimization via Tree Search), a unified framework for multi-turn agentic RL that addresses three core challenges: limited exploration diversity, sparse credit assignment, and misaligned policy optimization. AT$^2$PO introduces a turn-level tree structure that jointly enables Entropy-Guided Tree Expansion for strategic exploration and Turn-wise Credit Assignment for fine-grained reward propagation from sparse outcomes. Complementing this, we propose Agentic Turn-based Policy Optimization, a turn-level learning objective that aligns policy updates with the natural decision granularity of agentic interactions. ATPO is orthogonal to tree search and can be readily integrated into any multi-turn RL pipeline. Experiments across seven benchmarks demonstrate consistent improvements over the state-of-the-art baseline by up to 1.84 percentage points in average, with ablation studies validating the effectiveness of each component. Our code is available at https://github.com/zzfoutofspace/ATPO.
Adaptive Termination for Multi-round Parallel Reasoning: An Universal Semantic Entropy-Guided Framework
Jul 09, 2025Recent advances in large language models (LLMs) have accelerated progress toward artificial general intelligence, with inference-time scaling emerging as a key technique. Contemporary approaches leverage either sequential reasoning (iteratively extending chains of thought) or parallel reasoning (generating multiple solutions simultaneously) to scale inference. However, both paradigms face fundamental limitations: sequential scaling typically relies on arbitrary token budgets for termination, leading to inefficiency or premature cutoff; while parallel scaling often lacks coordination among parallel branches and requires intrusive fine-tuning to perform effectively. In light of these challenges, we aim to design a flexible test-time collaborative inference framework that exploits the complementary strengths of both sequential and parallel reasoning paradigms. Towards this goal, the core challenge lies in developing an efficient and accurate intrinsic quality metric to assess model responses during collaborative inference, enabling dynamic control and early termination of the reasoning trace. To address this challenge, we introduce semantic entropy (SE), which quantifies the semantic diversity of parallel model responses and serves as a robust indicator of reasoning quality due to its strong negative correlation with accuracy...
Hunyuan-TurboS: Advancing Large Language Models through Mamba-Transformer Synergy and Adaptive Chain-of-Thought
May 21, 2025As Large Language Models (LLMs) rapidly advance, we introduce Hunyuan-TurboS, a novel large hybrid Transformer-Mamba Mixture of Experts (MoE) model. It synergistically combines Mamba's long-sequence processing efficiency with Transformer's superior contextual understanding. Hunyuan-TurboS features an adaptive long-short chain-of-thought (CoT) mechanism, dynamically switching between rapid responses for simple queries and deep "thinking" modes for complex problems, optimizing computational resources. Architecturally, this 56B activated (560B total) parameter model employs 128 layers (Mamba2, Attention, FFN) with an innovative AMF/MF block pattern. Faster Mamba2 ensures linear complexity, Grouped-Query Attention minimizes KV cache, and FFNs use an MoE structure. Pre-trained on 16T high-quality tokens, it supports a 256K context length and is the first industry-deployed large-scale Mamba model. Our comprehensive post-training strategy enhances capabilities via Supervised Fine-Tuning (3M instructions), a novel Adaptive Long-short CoT Fusion method, Multi-round Deliberation Learning for iterative improvement, and a two-stage Large-scale Reinforcement Learning process targeting STEM and general instruction-following. Evaluations show strong performance: overall top 7 rank on LMSYS Chatbot Arena with a score of 1356, outperforming leading models like Gemini-2.0-Flash-001 (1352) and o4-mini-2025-04-16 (1345). TurboS also achieves an average of 77.9% across 23 automated benchmarks. Hunyuan-TurboS balances high performance and efficiency, offering substantial capabilities at lower inference costs than many reasoning models, establishing a new paradigm for efficient large-scale pre-trained models.
A MARL Based Multi-Target Tracking Algorithm Under Jamming Against Radar
Dec 17, 2024



Unmanned aerial vehicles (UAVs) have played an increasingly important role in military operations and social life. Among all application scenarios, multi-target tracking tasks accomplished by UAV swarms have received extensive attention. However, when UAVs use radar to track targets, the tracking performance can be severely compromised by jammers. To track targets in the presence of jammers, UAVs can use passive radar to position the jammer. This paper proposes a system where a UAV swarm selects the radar's active or passive work mode to track multiple differently located and potentially jammer-carrying targets. After presenting the optimization problem and proving its solving difficulty, we use a multi-agent reinforcement learning algorithm to solve this control problem. We also propose a mechanism based on simulated annealing algorithm to avoid cases where UAV actions violate constraints. Simulation experiments demonstrate the effectiveness of the proposed algorithm.
Prompt-based Visual Alignment for Zero-shot Policy Transfer
Jun 05, 2024



Overfitting in RL has become one of the main obstacles to applications in reinforcement learning(RL). Existing methods do not provide explicit semantic constrain for the feature extractor, hindering the agent from learning a unified cross-domain representation and resulting in performance degradation on unseen domains. Besides, abundant data from multiple domains are needed. To address these issues, in this work, we propose prompt-based visual alignment (PVA), a robust framework to mitigate the detrimental domain bias in the image for zero-shot policy transfer. Inspired that Visual-Language Model (VLM) can serve as a bridge to connect both text space and image space, we leverage the semantic information contained in a text sequence as an explicit constraint to train a visual aligner. Thus, the visual aligner can map images from multiple domains to a unified domain and achieve good generalization performance. To better depict semantic information, prompt tuning is applied to learn a sequence of learnable tokens. With explicit constraints of semantic information, PVA can learn unified cross-domain representation under limited access to cross-domain data and achieves great zero-shot generalization ability in unseen domains. We verify PVA on a vision-based autonomous driving task with CARLA simulator. Experiments show that the agent generalizes well on unseen domains under limited access to multi-domain data.
Emergent Communication for Rules Reasoning
Nov 08, 2023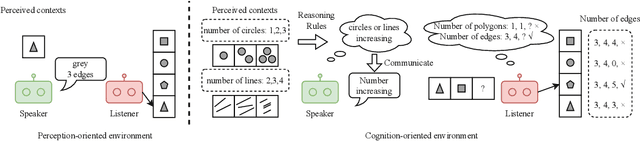

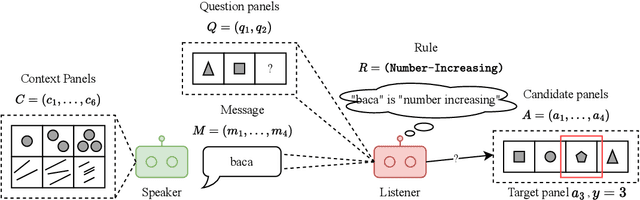

Research on emergent communication between deep-learning-based agents has received extensive attention due to its inspiration for linguistics and artificial intelligence. However, previous attempts have hovered around emerging communication under perception-oriented environmental settings, that forces agents to describe low-level perceptual features intra image or symbol contexts. In this work, inspired by the classic human reasoning test (namely Raven's Progressive Matrix), we propose the Reasoning Game, a cognition-oriented environment that encourages agents to reason and communicate high-level rules, rather than perceived low-level contexts. Moreover, we propose 1) an unbiased dataset (namely rule-RAVEN) as a benchmark to avoid overfitting, 2) and a two-stage curriculum agent training method as a baseline for more stable convergence in the Reasoning Game, where contexts and semantics are bilaterally drifting. Experimental results show that, in the Reasoning Game, a semantically stable and compositional language emerges to solve reasoning problems. The emerged language helps agents apply the extracted rules to the generalization of unseen context attributes, and to the transfer between different context attributes or even tasks.
Context Shift Reduction for Offline Meta-Reinforcement Learning
Nov 07, 2023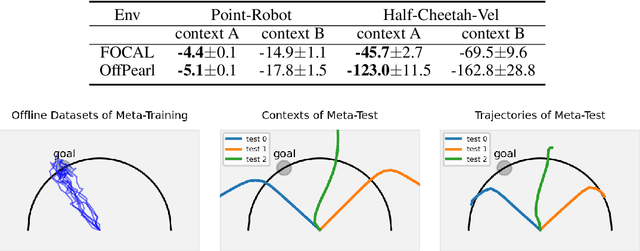

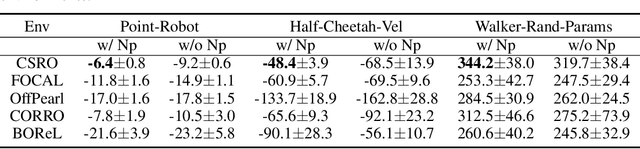
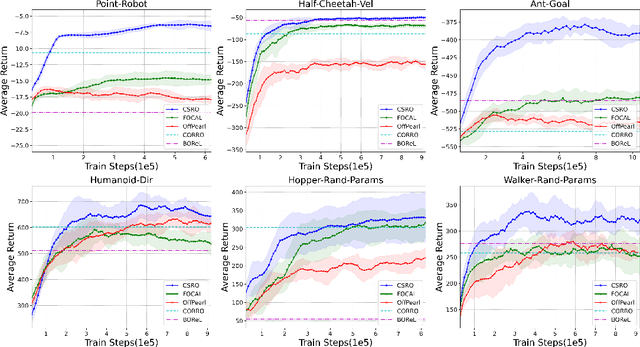
Offline meta-reinforcement learning (OMRL) utilizes pre-collected offline datasets to enhance the agent's generalization ability on unseen tasks. However, the context shift problem arises due to the distribution discrepancy between the contexts used for training (from the behavior policy) and testing (from the exploration policy). The context shift problem leads to incorrect task inference and further deteriorates the generalization ability of the meta-policy. Existing OMRL methods either overlook this problem or attempt to mitigate it with additional information. In this paper, we propose a novel approach called Context Shift Reduction for OMRL (CSRO) to address the context shift problem with only offline datasets. The key insight of CSRO is to minimize the influence of policy in context during both the meta-training and meta-test phases. During meta-training, we design a max-min mutual information representation learning mechanism to diminish the impact of the behavior policy on task representation. In the meta-test phase, we introduce the non-prior context collection strategy to reduce the effect of the exploration policy. Experimental results demonstrate that CSRO significantly reduces the context shift and improves the generalization ability, surpassing previous methods across various challenging domains.
Efficient Symbolic Policy Learning with Differentiable Symbolic Expression
Nov 02, 2023



Deep reinforcement learning (DRL) has led to a wide range of advances in sequential decision-making tasks. However, the complexity of neural network policies makes it difficult to understand and deploy with limited computational resources. Currently, employing compact symbolic expressions as symbolic policies is a promising strategy to obtain simple and interpretable policies. Previous symbolic policy methods usually involve complex training processes and pre-trained neural network policies, which are inefficient and limit the application of symbolic policies. In this paper, we propose an efficient gradient-based learning method named Efficient Symbolic Policy Learning (ESPL) that learns the symbolic policy from scratch in an end-to-end way. We introduce a symbolic network as the search space and employ a path selector to find the compact symbolic policy. By doing so we represent the policy with a differentiable symbolic expression and train it in an off-policy manner which further improves the efficiency. In addition, in contrast with previous symbolic policies which only work in single-task RL because of complexity, we expand ESPL on meta-RL to generate symbolic policies for unseen tasks. Experimentally, we show that our approach generates symbolic policies with higher performance and greatly improves data efficiency for single-task RL. In meta-RL, we demonstrate that compared with neural network policies the proposed symbolic policy achieves higher performance and efficiency and shows the potential to be interpretable.
Contrastive Modules with Temporal Attention for Multi-Task Reinforcement Learning
Nov 02, 2023
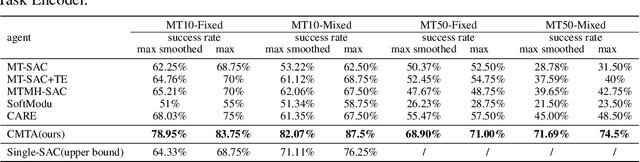
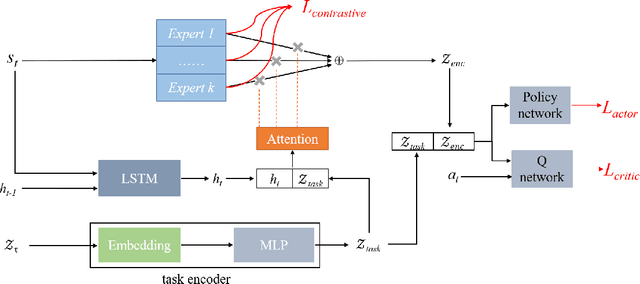
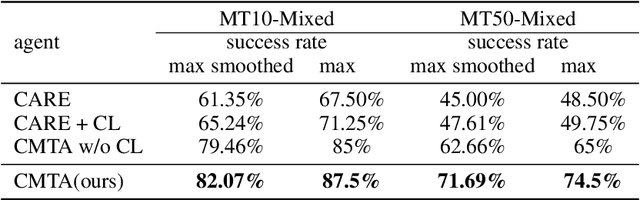
In the field of multi-task reinforcement learning, the modular principle, which involves specializing functionalities into different modules and combining them appropriately, has been widely adopted as a promising approach to prevent the negative transfer problem that performance degradation due to conflicts between tasks. However, most of the existing multi-task RL methods only combine shared modules at the task level, ignoring that there may be conflicts within the task. In addition, these methods do not take into account that without constraints, some modules may learn similar functions, resulting in restricting the model's expressiveness and generalization capability of modular methods. In this paper, we propose the Contrastive Modules with Temporal Attention(CMTA) method to address these limitations. CMTA constrains the modules to be different from each other by contrastive learning and combining shared modules at a finer granularity than the task level with temporal attention, alleviating the negative transfer within the task and improving the generalization ability and the performance for multi-task RL. We conducted the experiment on Meta-World, a multi-task RL benchmark containing various robotics manipulation tasks. Experimental results show that CMTA outperforms learning each task individually for the first time and achieves substantial performance improvements over the baselines.