 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeE2Former-V2: On-the-Fly Equivariant Attention with Linear Activation Memory
Jan 23, 2026Equivariant Graph Neural Networks (EGNNs) have become a widely used approach for modeling 3D atomistic systems. However, mainstream architectures face critical scalability bottlenecks due to the explicit construction of geometric features or dense tensor products on \textit{every} edge. To overcome this, we introduce \textbf{E2Former-V2}, a scalable architecture that integrates algebraic sparsity with hardware-aware execution. We first propose \textbf{E}quivariant \textbf{A}xis-\textbf{A}ligned \textbf{S}parsification (EAAS). EAAS builds on Wigner-$6j$ convolution by exploiting an $\mathrm{SO}(3) \rightarrow \mathrm{SO}(2)$ change of basis to transform computationally expensive dense tensor contractions into efficient, sparse parity re-indexing operations. Building on this representation, we introduce \textbf{On-the-Fly Equivariant Attention}, a fully node-centric mechanism implemented via a custom fused Triton kernel. By eliminating materialized edge tensors and maximizing SRAM utilization, our kernel achieves a \textbf{20$\times$ improvement in TFLOPS} compared to standard implementations. Extensive experiments on the SPICE and OMol25 datasets demonstrate that E2Former-V2 maintains comparable predictive performance while notably accelerating inference. This work demonstrates that large equivariant transformers can be trained efficiently using widely accessible GPU platforms. The code is avalible at https://github.com/IQuestLab/UBio-MolFM/tree/e2formerv2.
Technical Report on classification of literature related to children speech disorder
May 20, 2025This technical report presents a natural language processing (NLP)-based approach for systematically classifying scientific literature on childhood speech disorders. We retrieved and filtered 4,804 relevant articles published after 2015 from the PubMed database using domain-specific keywords. After cleaning and pre-processing the abstracts, we applied two topic modeling techniques - Latent Dirichlet Allocation (LDA) and BERTopic - to identify latent thematic structures in the corpus. Our models uncovered 14 clinically meaningful clusters, such as infantile hyperactivity and abnormal epileptic behavior. To improve relevance and precision, we incorporated a custom stop word list tailored to speech pathology. Evaluation results showed that the LDA model achieved a coherence score of 0.42 and a perplexity of -7.5, indicating strong topic coherence and predictive performance. The BERTopic model exhibited a low proportion of outlier topics (less than 20%), demonstrating its capacity to classify heterogeneous literature effectively. These results provide a foundation for automating literature reviews in speech-language pathology.
A MARL Based Multi-Target Tracking Algorithm Under Jamming Against Radar
Dec 17, 2024



Unmanned aerial vehicles (UAVs) have played an increasingly important role in military operations and social life. Among all application scenarios, multi-target tracking tasks accomplished by UAV swarms have received extensive attention. However, when UAVs use radar to track targets, the tracking performance can be severely compromised by jammers. To track targets in the presence of jammers, UAVs can use passive radar to position the jammer. This paper proposes a system where a UAV swarm selects the radar's active or passive work mode to track multiple differently located and potentially jammer-carrying targets. After presenting the optimization problem and proving its solving difficulty, we use a multi-agent reinforcement learning algorithm to solve this control problem. We also propose a mechanism based on simulated annealing algorithm to avoid cases where UAV actions violate constraints. Simulation experiments demonstrate the effectiveness of the proposed algorithm.
ChatGPT and a New Academic Reality: Artificial Intelligence-Written Research Papers and the Ethics of the Large Language Models in Scholarly Publishing
Mar 31, 2023This paper discusses OpenAIs ChatGPT, a generative pre-trained transformer, which uses natural language processing to fulfill text-based user requests (i.e., a chatbot). The history and principles behind ChatGPT and similar models are discussed. This technology is then discussed in relation to its potential impact on academia and scholarly research and publishing. ChatGPT is seen as a potential model for the automated preparation of essays and other types of scholarly manuscripts. Potential ethical issues that could arise with the emergence of large language models like GPT-3, the underlying technology behind ChatGPT, and its usage by academics and researchers, are discussed and situated within the context of broader advancements in artificial intelligence, machine learning, and natural language processing for research and scholarly publishing.
Integrating Semantic and Structural Information with Graph Convolutional Network for Controversy Detection
May 16, 2020

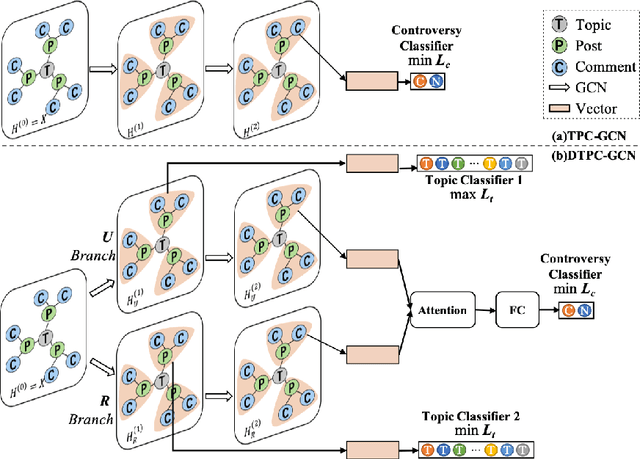
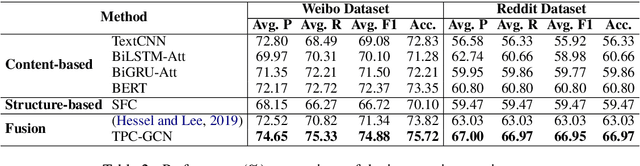
Identifying controversial posts on social media is a fundamental task for mining public sentiment, assessing the influence of events, and alleviating the polarized views. However, existing methods fail to 1) effectively incorporate the semantic information from content-related posts; 2) preserve the structural information for reply relationship modeling; 3) properly handle posts from topics dissimilar to those in the training set. To overcome the first two limitations, we propose Topic-Post-Comment Graph Convolutional Network (TPC-GCN), which integrates the information from the graph structure and content of topics, posts, and comments for post-level controversy detection. As to the third limitation, we extend our model to Disentangled TPC-GCN (DTPC-GCN), to disentangle topic-related and topic-unrelated features and then fuse dynamically. Extensive experiments on two real-world datasets demonstrate that our models outperform existing methods. Analysis of the results and cases proves that our models can integrate both semantic and structural information with significant generalizability.