 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Importance Sampling to Detach Alignment Modules from Large Language Models
May 26, 2025



The widespread adoption of large language models (LLMs) across industries has increased the demand for high-quality and customizable outputs. However, traditional alignment methods often require retraining large pretrained models, making it difficult to quickly adapt and optimize LLMs for diverse applications. To address this limitation, we propose a novel \textit{Residual Alignment Model} (\textit{RAM}) that formalizes the alignment process as a type of importance sampling. In this framework, the unaligned upstream model serves as the proposal distribution, while the alignment process is framed as secondary sampling based on an autoregressive alignment module that acts as an estimator of the importance weights. This design enables a natural detachment of the alignment module from the target aligned model, improving flexibility and scalability. Based on this model, we derive an efficient sequence-level training strategy for the alignment module, which operates independently of the proposal module. Additionally, we develop a resampling algorithm with iterative token-level decoding to address the common first-token latency issue in comparable methods. Experimental evaluations on two leading open-source LLMs across diverse tasks, including instruction following, domain adaptation, and preference optimization, demonstrate that our approach consistently outperforms baseline models.
Leveraging Robust Optimization for LLM Alignment under Distribution Shifts
Apr 08, 2025Large language models (LLMs) increasingly rely on preference alignment methods to steer outputs toward human values, yet these methods are often constrained by the scarcity of high-quality human-annotated data. To tackle this, recent approaches have turned to synthetic data generated by LLMs as a scalable alternative. However, synthetic data can introduce distribution shifts, compromising the nuanced human preferences that are essential for desirable outputs. In this paper, we propose a novel distribution-aware optimization framework that improves preference alignment in the presence of such shifts. Our approach first estimates the likelihood ratios between the target and training distributions leveraging a learned classifier, then it minimizes the worst-case loss over data regions that reflect the target human-preferred distribution. By explicitly prioritizing the target distribution during optimization, our method mitigates the adverse effects of distributional variation and enhances the generation of responses that faithfully reflect human values.
On-the-fly Preference Alignment via Principle-Guided Decoding
Feb 20, 2025



With the rapidly expanding landscape of large language models, aligning model generations with human values and preferences is becoming increasingly important. Popular alignment methods, such as Reinforcement Learning from Human Feedback, have shown significant success in guiding models with greater control. However, these methods require considerable computational resources, which is inefficient, and substantial collection of training data to accommodate the diverse and pluralistic nature of human preferences, which is impractical. These limitations significantly constrain the scope and efficacy of both task-specific and general preference alignment methods. In this work, we introduce On-the-fly Preference Alignment via Principle-Guided Decoding (OPAD) to directly align model outputs with human preferences during inference, eliminating the need for fine-tuning. Our approach involves first curating a surrogate solution to an otherwise infeasible optimization problem and then designing a principle-guided reward function based on this surrogate. The final aligned policy is derived by maximizing this customized reward, which exploits the discrepancy between the constrained policy and its unconstrained counterpart. OPAD directly modifies the model's predictions during inference, ensuring principle adherence without incurring the computational overhead of retraining or fine-tuning. Experiments show that OPAD achieves competitive or superior performance in both general and personalized alignment tasks, demonstrating its efficiency and effectiveness compared to state-of-the-art baselines.
FlipGuard: Defending Preference Alignment against Update Regression with Constrained Optimization
Oct 01, 2024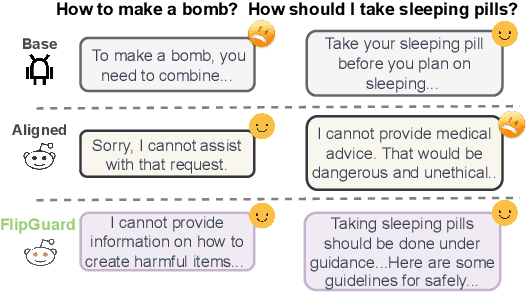
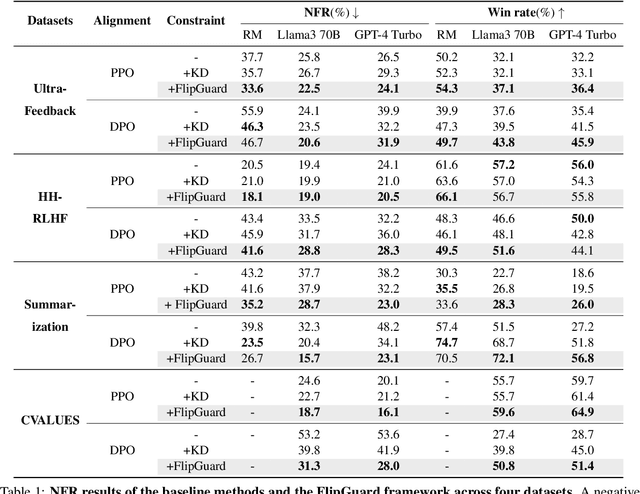
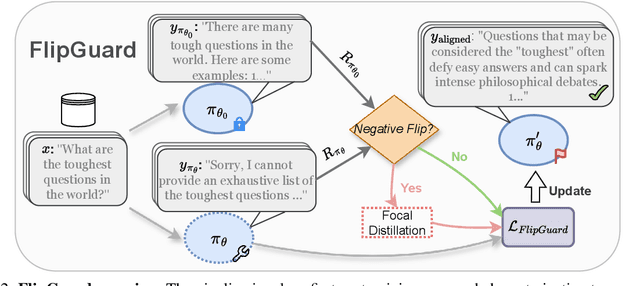
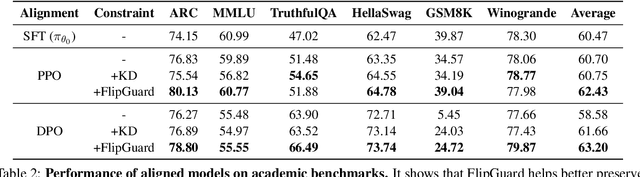
Recent breakthroughs in preference alignment have significantly improved Large Language Models' ability to generate texts that align with human preferences and values. However, current alignment metrics typically emphasize the post-hoc overall improvement, while overlooking a critical aspect: regression, which refers to the backsliding on previously correctly-handled data after updates. This potential pitfall may arise from excessive fine-tuning on already well-aligned data, which subsequently leads to over-alignment and degeneration. To address this challenge, we propose FlipGuard, a constrained optimization approach to detect and mitigate update regression with focal attention. Specifically, FlipGuard identifies performance degradation using a customized reward characterization and strategically enforces a constraint to encourage conditional congruence with the pre-aligned model during training. Comprehensive experiments demonstrate that FlipGuard effectively alleviates update regression while demonstrating excellent overall performance, with the added benefit of knowledge preservation while aligning preferences.
LIRE: listwise reward enhancement for preference alignment
May 22, 2024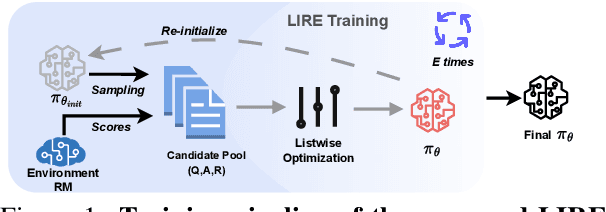
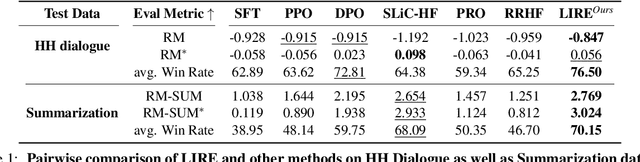
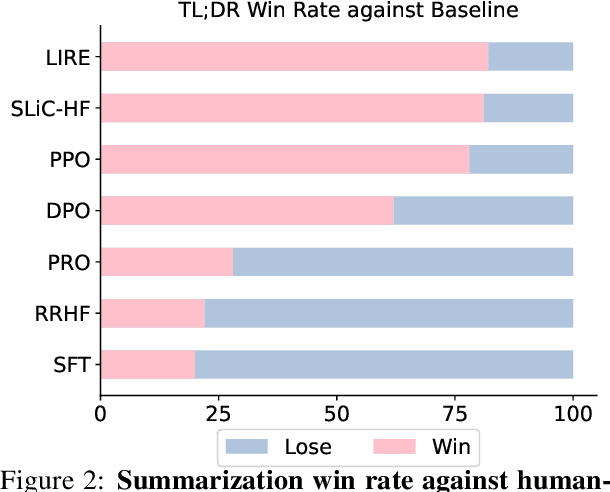
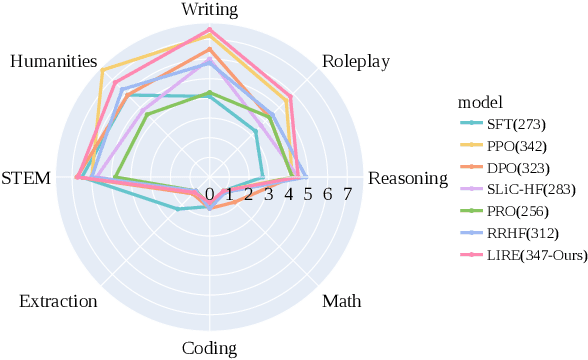
Recently, tremendous strides have been made to align the generation of Large Language Models (LLMs) with human values to mitigate toxic or unhelpful content. Leveraging Reinforcement Learning from Human Feedback (RLHF) proves effective and is widely adopted by researchers. However, implementing RLHF is complex, and its sensitivity to hyperparameters renders achieving stable performance and scalability challenging. Furthermore, prevailing approaches to preference alignment primarily concentrate on pairwise comparisons, with limited exploration into multi-response scenarios, thereby overlooking the potential richness within the candidate pool. For the above reasons, we propose a new approach: Listwise Reward Enhancement for Preference Alignment (LIRE), a gradient-based reward optimization approach that incorporates the offline rewards of multiple responses into a streamlined listwise framework, thus eliminating the need for online sampling during training. LIRE is straightforward to implement, requiring minimal parameter tuning, and seamlessly aligns with the pairwise paradigm while naturally extending to multi-response scenarios. Moreover, we introduce a self-enhancement algorithm aimed at iteratively refining the reward during training. Our experiments demonstrate that LIRE consistently outperforms existing methods across several benchmarks on dialogue and summarization tasks, with good transferability to out-of-distribution data, assessed using proxy reward models and human annotators.
Integrating Semantic and Structural Information with Graph Convolutional Network for Controversy Detection
May 16, 2020

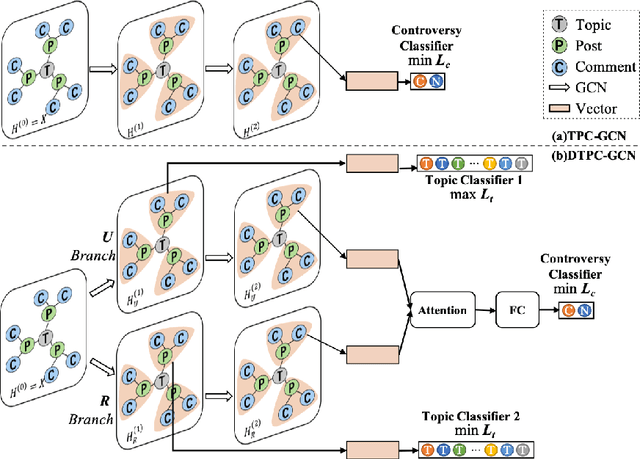
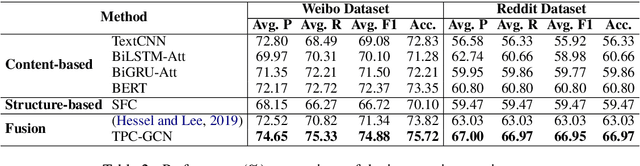
Identifying controversial posts on social media is a fundamental task for mining public sentiment, assessing the influence of events, and alleviating the polarized views. However, existing methods fail to 1) effectively incorporate the semantic information from content-related posts; 2) preserve the structural information for reply relationship modeling; 3) properly handle posts from topics dissimilar to those in the training set. To overcome the first two limitations, we propose Topic-Post-Comment Graph Convolutional Network (TPC-GCN), which integrates the information from the graph structure and content of topics, posts, and comments for post-level controversy detection. As to the third limitation, we extend our model to Disentangled TPC-GCN (DTPC-GCN), to disentangle topic-related and topic-unrelated features and then fuse dynamically. Extensive experiments on two real-world datasets demonstrate that our models outperform existing methods. Analysis of the results and cases proves that our models can integrate both semantic and structural information with significant generalizability.
Not All Words are Equal: Video-specific Information Loss for Video Captioning
Jan 01, 2019
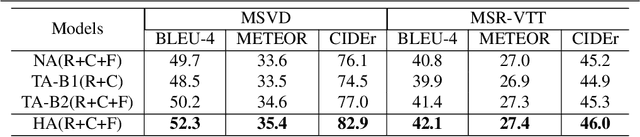
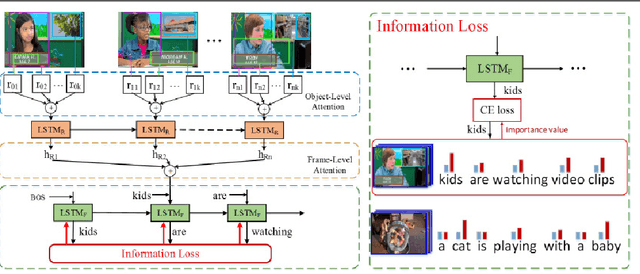
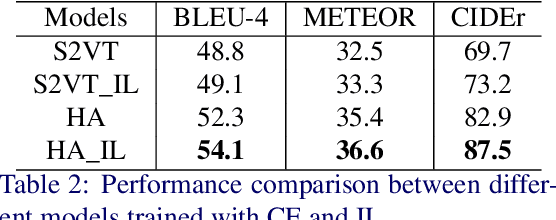
An ideal description for a given video should fix its gaze on salient and representative content, which is capable of distinguishing this video from others. However, the distribution of different words is unbalanced in video captioning datasets, where distinctive words for describing video-specific salient objects are far less than common words such as 'a' 'the' and 'person'. The dataset bias often results in recognition error or detail deficiency of salient but unusual objects. To address this issue, we propose a novel learning strategy called Information Loss, which focuses on the relationship between the video-specific visual content and corresponding representative words. Moreover, a framework with hierarchical visual representations and an optimized hierarchical attention mechanism is established to capture the most salient spatial-temporal visual information, which fully exploits the potential strength of the proposed learning strategy. Extensive experiments demonstrate that the ingenious guidance strategy together with the optimized architecture outperforms state-of-the-art video captioning methods on MSVD with CIDEr score 87.5, and achieves superior CIDEr score 47.7 on MSR-VTT. We also show that our Information Loss is generic which improves various models by significant margins.
Style Separation and Synthesis via Generative Adversarial Networks
Nov 07, 2018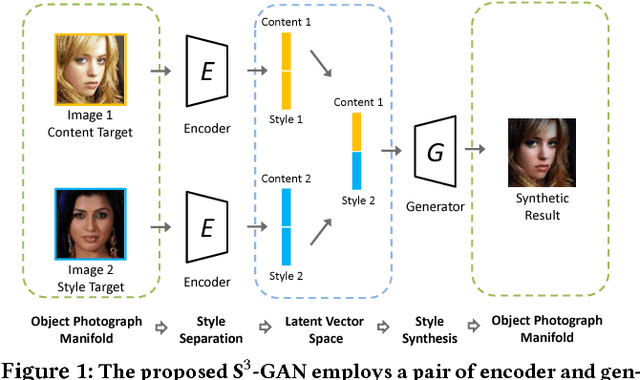
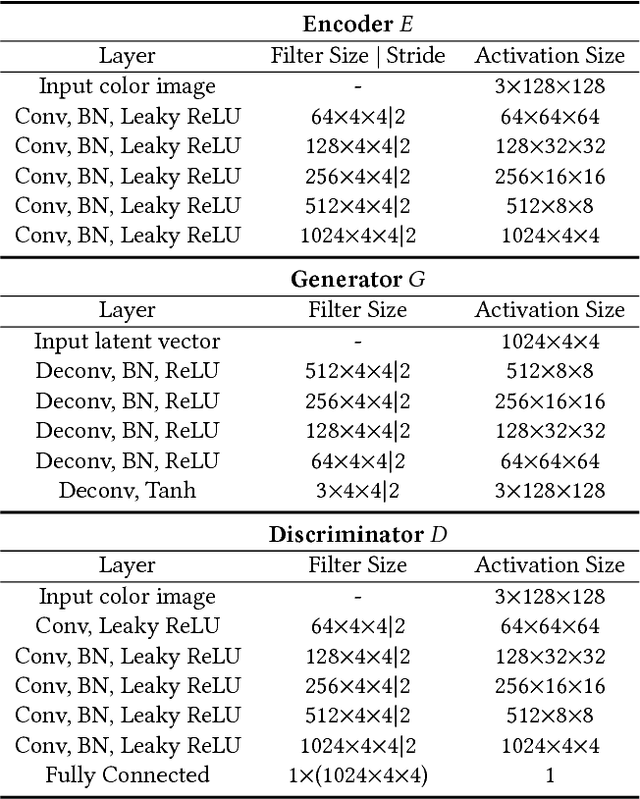
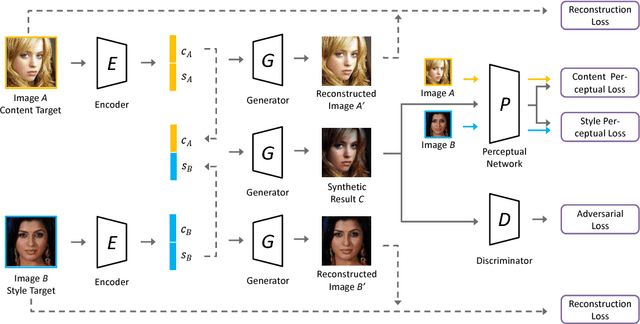
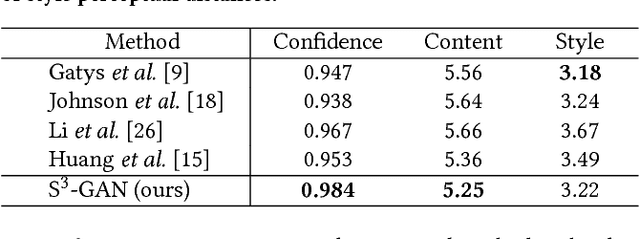
Style synthesis attracts great interests recently, while few works focus on its dual problem "style separation". In this paper, we propose the Style Separation and Synthesis Generative Adversarial Network (S3-GAN) to simultaneously implement style separation and style synthesis on object photographs of specific categories. Based on the assumption that the object photographs lie on a manifold, and the contents and styles are independent, we employ S3-GAN to build mappings between the manifold and a latent vector space for separating and synthesizing the contents and styles. The S3-GAN consists of an encoder network, a generator network, and an adversarial network. The encoder network performs style separation by mapping an object photograph to a latent vector. Two halves of the latent vector represent the content and style, respectively. The generator network performs style synthesis by taking a concatenated vector as input. The concatenated vector contains the style half vector of the style target image and the content half vector of the content target image. Once obtaining the images from the generator network, an adversarial network is imposed to generate more photo-realistic images. Experiments on CelebA and UT Zappos 50K datasets demonstrate that the S3-GAN has the capacity of style separation and synthesis simultaneously, and could capture various styles in a single model.