 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual Latent Memory for Visual Multi-agent System
Jan 31, 2026While Visual Multi-Agent Systems (VMAS) promise to enhance comprehensive abilities through inter-agent collaboration, empirical evidence reveals a counter-intuitive "scaling wall": increasing agent turns often degrades performance while exponentially inflating token costs. We attribute this failure to the information bottleneck inherent in text-centric communication, where converting perceptual and thinking trajectories into discrete natural language inevitably induces semantic loss. To this end, we propose L$^{2}$-VMAS, a novel model-agnostic framework that enables inter-agent collaboration with dual latent memories. Furthermore, we decouple the perception and thinking while dynamically synthesizing dual latent memories. Additionally, we introduce an entropy-driven proactive triggering that replaces passive information transmission with efficient, on-demand memory access. Extensive experiments among backbones, sizes, and multi-agent structures demonstrate that our method effectively breaks the "scaling wall" with superb scalability, improving average accuracy by 2.7-5.4% while reducing token usage by 21.3-44.8%. Codes: https://github.com/YU-deep/L2-VMAS.
M3CoTBench: Benchmark Chain-of-Thought of MLLMs in Medical Image Understanding
Jan 13, 2026Chain-of-Thought (CoT) reasoning has proven effective in enhancing large language models by encouraging step-by-step intermediate reasoning, and recent advances have extended this paradigm to Multimodal Large Language Models (MLLMs). In the medical domain, where diagnostic decisions depend on nuanced visual cues and sequential reasoning, CoT aligns naturally with clinical thinking processes. However, Current benchmarks for medical image understanding generally focus on the final answer while ignoring the reasoning path. An opaque process lacks reliable bases for judgment, making it difficult to assist doctors in diagnosis. To address this gap, we introduce a new M3CoTBench benchmark specifically designed to evaluate the correctness, efficiency, impact, and consistency of CoT reasoning in medical image understanding. M3CoTBench features 1) a diverse, multi-level difficulty dataset covering 24 examination types, 2) 13 varying-difficulty tasks, 3) a suite of CoT-specific evaluation metrics (correctness, efficiency, impact, and consistency) tailored to clinical reasoning, and 4) a performance analysis of multiple MLLMs. M3CoTBench systematically evaluates CoT reasoning across diverse medical imaging tasks, revealing current limitations of MLLMs in generating reliable and clinically interpretable reasoning, and aims to foster the development of transparent, trustworthy, and diagnostically accurate AI systems for healthcare. Project page at https://juntaojianggavin.github.io/projects/M3CoTBench/.
EvoRoute: Experience-Driven Self-Routing LLM Agent Systems
Jan 06, 2026Complex agentic AI systems, powered by a coordinated ensemble of Large Language Models (LLMs), tool and memory modules, have demonstrated remarkable capabilities on intricate, multi-turn tasks. However, this success is shadowed by prohibitive economic costs and severe latency, exposing a critical, yet underexplored, trade-off. We formalize this challenge as the \textbf{Agent System Trilemma}: the inherent tension among achieving state-of-the-art performance, minimizing monetary cost, and ensuring rapid task completion. To dismantle this trilemma, we introduce EvoRoute, a self-evolving model routing paradigm that transcends static, pre-defined model assignments. Leveraging an ever-expanding knowledge base of prior experience, EvoRoute dynamically selects Pareto-optimal LLM backbones at each step, balancing accuracy, efficiency, and resource use, while continually refining its own selection policy through environment feedback. Experiments on challenging agentic benchmarks such as GAIA and BrowseComp+ demonstrate that EvoRoute, when integrated into off-the-shelf agentic systems, not only sustains or enhances system performance but also reduces execution cost by up to $80\%$ and latency by over $70\%$.
JavisGPT: A Unified Multi-modal LLM for Sounding-Video Comprehension and Generation
Dec 28, 2025This paper presents JavisGPT, the first unified multimodal large language model (MLLM) for Joint Audio-Video (JAV) comprehension and generation. JavisGPT adopts a concise encoder-LLM-decoder architecture, featuring a SyncFusion module for spatio-temporal audio-video fusion and synchrony-aware learnable queries to bridge a pretrained JAV-DiT generator. This design enables temporally coherent video-audio understanding and generation from multimodal instructions. We design an effective three-stage training pipeline consisting of multimodal pretraining, audio-video fine-tuning, and large-scale instruction-tuning, to progressively build multimodal comprehension and generation from existing vision-language models. To support this, we further construct JavisInst-Omni, a high-quality instruction dataset with over 200K GPT-4o-curated audio-video-text dialogues that span diverse and multi-level comprehension and generation scenarios. Extensive experiments on JAV comprehension and generation benchmarks show that JavisGPT outperforms existing MLLMs, particularly in complex and temporally synchronized settings.
MemEvolve: Meta-Evolution of Agent Memory Systems
Dec 21, 2025Self-evolving memory systems are unprecedentedly reshaping the evolutionary paradigm of large language model (LLM)-based agents. Prior work has predominantly relied on manually engineered memory architectures to store trajectories, distill experience, and synthesize reusable tools, enabling agents to evolve on the fly within environment interactions. However, this paradigm is fundamentally constrained by the staticity of the memory system itself: while memory facilitates agent-level evolving, the underlying memory architecture cannot be meta-adapted to diverse task contexts. To address this gap, we propose MemEvolve, a meta-evolutionary framework that jointly evolves agents' experiential knowledge and their memory architecture, allowing agent systems not only to accumulate experience but also to progressively refine how they learn from it. To ground MemEvolve in prior research and foster openness in future self-evolving systems, we introduce EvolveLab, a unified self-evolving memory codebase that distills twelve representative memory systems into a modular design space (encode, store, retrieve, manage), providing both a standardized implementation substrate and a fair experimental arena. Extensive evaluations on four challenging agentic benchmarks demonstrate that MemEvolve achieves (I) substantial performance gains, improving frameworks such as SmolAgent and Flash-Searcher by up to $17.06\%$; and (II) strong cross-task and cross-LLM generalization, designing memory architectures that transfer effectively across diverse benchmarks and backbone models.
Memory in the Age of AI Agents
Dec 15, 2025Memory has emerged, and will continue to remain, a core capability of foundation model-based agents. As research on agent memory rapidly expands and attracts unprecedented attention, the field has also become increasingly fragmented. Existing works that fall under the umbrella of agent memory often differ substantially in their motivations, implementations, and evaluation protocols, while the proliferation of loosely defined memory terminologies has further obscured conceptual clarity. Traditional taxonomies such as long/short-term memory have proven insufficient to capture the diversity of contemporary agent memory systems. This work aims to provide an up-to-date landscape of current agent memory research. We begin by clearly delineating the scope of agent memory and distinguishing it from related concepts such as LLM memory, retrieval augmented generation (RAG), and context engineering. We then examine agent memory through the unified lenses of forms, functions, and dynamics. From the perspective of forms, we identify three dominant realizations of agent memory, namely token-level, parametric, and latent memory. From the perspective of functions, we propose a finer-grained taxonomy that distinguishes factual, experiential, and working memory. From the perspective of dynamics, we analyze how memory is formed, evolved, and retrieved over time. To support practical development, we compile a comprehensive summary of memory benchmarks and open-source frameworks. Beyond consolidation, we articulate a forward-looking perspective on emerging research frontiers, including memory automation, reinforcement learning integration, multimodal memory, multi-agent memory, and trustworthiness issues. We hope this survey serves not only as a reference for existing work, but also as a conceptual foundation for rethinking memory as a first-class primitive in the design of future agentic intelligence.
VisMem: Latent Vision Memory Unlocks Potential of Vision-Language Models
Nov 14, 2025Despite the remarkable success of Vision-Language Models (VLMs), their performance on a range of complex visual tasks is often hindered by a "visual processing bottleneck": a propensity to lose grounding in visual evidence and exhibit a deficit in contextualized visual experience during prolonged generation. Drawing inspiration from human cognitive memory theory, which distinguishes short-term visually-dominant memory and long-term semantically-dominant memory, we propose VisMem, a cognitively-aligned framework that equips VLMs with dynamic latent vision memories, a short-term module for fine-grained perceptual retention and a long-term module for abstract semantic consolidation. These memories are seamlessly invoked during inference, allowing VLMs to maintain both perceptual fidelity and semantic consistency across thinking and generation. Extensive experiments across diverse visual benchmarks for understanding, reasoning, and generation reveal that VisMem delivers a significant average performance boost of 11.8% relative to the vanilla model and outperforms all counterparts, establishing a new paradigm for latent-space memory enhancement. The code will be available: https://github.com/YU-deep/VisMem.git.
Patch-as-Decodable-Token: Towards Unified Multi-Modal Vision Tasks in MLLMs
Oct 02, 2025
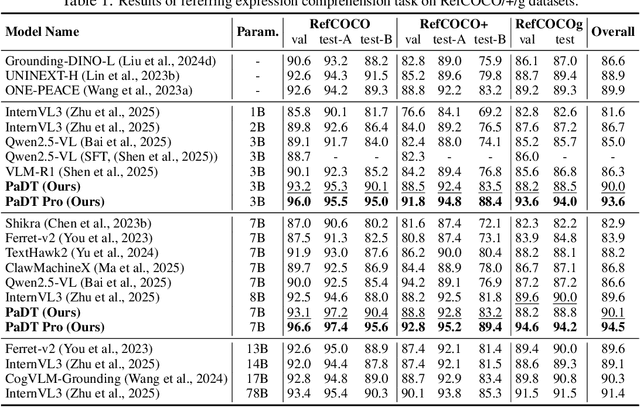

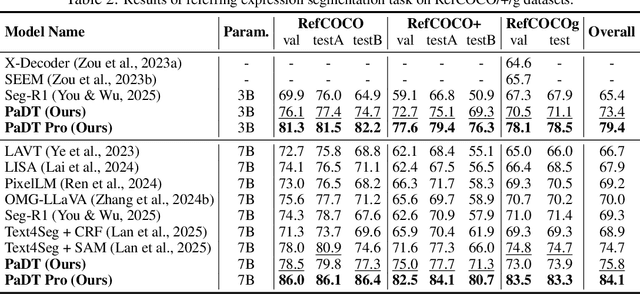
Multimodal large language models (MLLMs) have advanced rapidly in recent years. However, existing approaches for vision tasks often rely on indirect representations, such as generating coordinates as text for detection, which limits performance and prevents dense prediction tasks like segmentation. To overcome these challenges, we introduce Patch-as-Decodable Token (PaDT), a unified paradigm that enables MLLMs to directly generate both textual and diverse visual outputs. Central to PaDT are Visual Reference Tokens (VRTs), derived from visual patch embeddings of query images and interleaved seamlessly with LLM's output textual tokens. A lightweight decoder then transforms LLM's outputs into detection, segmentation, and grounding predictions. Unlike prior methods, PaDT processes VRTs independently at each forward pass and dynamically expands the embedding table, thus improving localization and differentiation among similar objects. We further tailor a training strategy for PaDT by randomly selecting VRTs for supervised fine-tuning and introducing a robust per-token cross-entropy loss. Our empirical studies across four visual perception and understanding tasks suggest PaDT consistently achieving state-of-the-art performance, even compared with significantly larger MLLM models. The code is available at https://github.com/Gorilla-Lab-SCUT/PaDT.
SAIL-VL2 Technical Report
Sep 18, 2025We introduce SAIL-VL2, an open-suite vision-language foundation model (LVM) for comprehensive multimodal understanding and reasoning. As the successor to SAIL-VL, SAIL-VL2 achieves state-of-the-art performance at the 2B and 8B parameter scales across diverse image and video benchmarks, demonstrating strong capabilities from fine-grained perception to complex reasoning. Its effectiveness is driven by three core innovations. First, a large-scale data curation pipeline with scoring and filtering strategies enhances both quality and distribution across captioning, OCR, QA, and video data, improving training efficiency. Second, a progressive training framework begins with a powerful pre-trained vision encoder (SAIL-ViT), advances through multimodal pre-training, and culminates in a thinking-fusion SFT-RL hybrid paradigm that systematically strengthens model capabilities. Third, architectural advances extend beyond dense LLMs to efficient sparse Mixture-of-Experts (MoE) designs. With these contributions, SAIL-VL2 demonstrates competitive performance across 106 datasets and achieves state-of-the-art results on challenging reasoning benchmarks such as MMMU and MathVista. Furthermore, on the OpenCompass leaderboard, SAIL-VL2-2B ranks first among officially released open-source models under the 4B parameter scale, while serving as an efficient and extensible foundation for the open-source multimodal community.
AgenTracer: Who Is Inducing Failure in the LLM Agentic Systems?
Sep 04, 2025Large Language Model (LLM)-based agentic systems, often comprising multiple models, complex tool invocations, and orchestration protocols, substantially outperform monolithic agents. Yet this very sophistication amplifies their fragility, making them more prone to system failure. Pinpointing the specific agent or step responsible for an error within long execution traces defines the task of agentic system failure attribution. Current state-of-the-art reasoning LLMs, however, remain strikingly inadequate for this challenge, with accuracy generally below 10%. To address this gap, we propose AgenTracer, the first automated framework for annotating failed multi-agent trajectories via counterfactual replay and programmed fault injection, producing the curated dataset TracerTraj. Leveraging this resource, we develop AgenTracer-8B, a lightweight failure tracer trained with multi-granular reinforcement learning, capable of efficiently diagnosing errors in verbose multi-agent interactions. On the Who&When benchmark, AgenTracer-8B outperforms giant proprietary LLMs like Gemini-2.5-Pro and Claude-4-Sonnet by up to 18.18%, setting a new standard in LLM agentic failure attribution. More importantly, AgenTracer-8B delivers actionable feedback to off-the-shelf multi-agent systems like MetaGPT and MaAS with 4.8-14.2% performance gains, empowering self-correcting and self-evolving agentic AI.