 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmulating Clinician Cognition via Self-Evolving Deep Clinical Research
Mar 11, 2026Clinical diagnosis is a complex cognitive process, grounded in dynamic cue acquisition and continuous expertise accumulation. Yet most current artificial intelligence (AI) systems are misaligned with this reality, treating diagnosis as single-pass retrospective prediction while lacking auditable mechanisms for governed improvement. We developed DxEvolve, a self-evolving diagnostic agent that bridges these gaps through an interactive deep clinical research workflow. The framework autonomously requisitions examinations and continually externalizes clinical experience from increasing encounter exposure as diagnostic cognition primitives. On the MIMIC-CDM benchmark, DxEvolve improved diagnostic accuracy by 11.2% on average over backbone models and reached 90.4% on a reader-study subset, comparable to the clinician reference (88.8%). DxEvolve improved accuracy on an independent external cohort by 10.2% (categories covered by the source cohort) and 17.1% (uncovered categories) compared to the competitive method. By transforming experience into a governable learning asset, DxEvolve supports an accountable pathway for the continual evolution of clinical AI.
SSKG Hub: An Expert-Guided Platform for LLM-Empowered Sustainability Standards Knowledge Graphs
Feb 28, 2026Sustainability disclosure standards (e.g., GRI, SASB, TCFD, IFRS S2) are comprehensive yet lengthy, terminology-dense, and highly cross-referential, hindering structured analysis and downstream use. We present SSKG Hub (Sustainability Standards Knowledge Graph Hub), a research prototype and interactive web platform that transforms standards into auditable knowledge graphs (KGs) through an LLM-centered, expert-guided pipeline. The system integrates automatic standard identification, configurable chunking, standard-specific prompting, robust triple parsing, and provenance-aware Neo4j storage with fine-grained audit metadata. LLM extraction produces a provenance-linked Draft KG, which is reviewed, curated, and formally promoted to a Certified KG through meta-expert adjudication. A role-based governance framework covering read-only guest access, expert review and CRUD operations, meta-expert certification, and administrative oversight ensures traceability and accountability across draft and certified states. Beyond graph exploration and triple-level evidence tracing, SSKG Hub supports cross-KG fusion, KG-driven tasks, and dedicated modules for insights and curated resources. We validate the platform through a comprehensive expert-led KG review case study that demonstrates end-to-end curation and quality assurance. The web application is publicly available at www.sskg-hub.com.
SP^2DPO: An LLM-assisted Semantic Per-Pair DPO Generalization
Jan 29, 2026Direct Preference Optimization (DPO) controls the trade-off between fitting preference labels and staying close to a reference model using a single global temperature beta, implicitly treating all preference pairs as equally informative. Real-world preference corpora are heterogeneous: they mix high-signal, objective failures (for example, safety, factuality, instruction violations) with low-signal or subjective distinctions (for example, style), and also include label noise. We introduce our method, SP2DPO (Semantic Per-Pair DPO), a generalization that replaces the global temperature with an instance-specific schedule beta_i pre-decided offline from structured semantic-gap annotations (category, magnitude, confidence) produced by teacher language models. We instantiate this procedure on the UltraFeedback preference corpus (59,960 pairs), enabling large-scale construction of an auditable beta_i artifact, and incur zero training-time overhead: the inner-loop optimizer remains standard DPO with beta set per pair. We focus our empirical study on AlpacaEval 2.0, reporting both raw win rate and length-controlled win rate. Across four open-weight, instruction-tuned student backbones (4B-8B), SP2DPO is competitive with a tuned global-beta DPO baseline and improves AlpacaEval 2.0 length-controlled win rate on two of four backbones, while avoiding per-model beta sweeps. All code, annotations, and artifacts will be released.
Beyond Traditional Diagnostics: Transforming Patient-Side Information into Predictive Insights with Knowledge Graphs and Prototypes
Dec 09, 2025Predicting diseases solely from patient-side information, such as demographics and self-reported symptoms, has attracted significant research attention due to its potential to enhance patient awareness, facilitate early healthcare engagement, and improve healthcare system efficiency. However, existing approaches encounter critical challenges, including imbalanced disease distributions and a lack of interpretability, resulting in biased or unreliable predictions. To address these issues, we propose the Knowledge graph-enhanced, Prototype-aware, and Interpretable (KPI) framework. KPI systematically integrates structured and trusted medical knowledge into a unified disease knowledge graph, constructs clinically meaningful disease prototypes, and employs contrastive learning to enhance predictive accuracy, which is particularly important for long-tailed diseases. Additionally, KPI utilizes large language models (LLMs) to generate patient-specific, medically relevant explanations, thereby improving interpretability and reliability. Extensive experiments on real-world datasets demonstrate that KPI outperforms state-of-the-art methods in predictive accuracy and provides clinically valid explanations that closely align with patient narratives, highlighting its practical value for patient-centered healthcare delivery.
Adapt in the Wild: Test-Time Entropy Minimization with Sharpness and Feature Regularization
Sep 05, 2025Test-time adaptation (TTA) may fail to improve or even harm the model performance when test data have: 1) mixed distribution shifts, 2) small batch sizes, 3) online imbalanced label distribution shifts. This is often a key obstacle preventing existing TTA methods from being deployed in the real world. In this paper, we investigate the unstable reasons and find that the batch norm layer is a crucial factor hindering TTA stability. Conversely, TTA can perform more stably with batch-agnostic norm layers, i.e., group or layer norm. However, we observe that TTA with group and layer norms does not always succeed and still suffers many failure cases, i.e., the model collapses into trivial solutions by assigning the same class label for all samples. By digging into this, we find that, during the collapse process: 1) the model gradients often undergo an initial explosion followed by rapid degradation, suggesting that certain noisy test samples with large gradients may disrupt adaptation; and 2) the model representations tend to exhibit high correlations and classification bias. To address this, we first propose a sharpness-aware and reliable entropy minimization method, called SAR, for stabilizing TTA from two aspects: 1) remove partial noisy samples with large gradients, 2) encourage model weights to go to a flat minimum so that the model is robust to the remaining noisy samples. Based on SAR, we further introduce SAR^2 to prevent representation collapse with two regularizers: 1) a redundancy regularizer to reduce inter-dimensional correlations among centroid-invariant features; and 2) an inequity regularizer to maximize the prediction entropy of a prototype centroid, thereby penalizing biased representations toward any specific class. Promising results demonstrate that our methods perform more stably over prior methods and are computationally efficient under the above wild test scenarios.
Context Pooling: Query-specific Graph Pooling for Generic Inductive Link Prediction in Knowledge Graphs
Jul 10, 2025Recent investigations on the effectiveness of Graph Neural Network (GNN)-based models for link prediction in Knowledge Graphs (KGs) show that vanilla aggregation does not significantly impact the model performance. In this paper, we introduce a novel method, named Context Pooling, to enhance GNN-based models' efficacy for link predictions in KGs. To our best of knowledge, Context Pooling is the first methodology that applies graph pooling in KGs. Additionally, Context Pooling is first-of-its-kind to enable the generation of query-specific graphs for inductive settings, where testing entities are unseen during training. Specifically, we devise two metrics, namely neighborhood precision and neighborhood recall, to assess the neighbors' logical relevance regarding the given queries, thereby enabling the subsequent comprehensive identification of only the logically relevant neighbors for link prediction. Our method is generic and assessed by being applied to two state-of-the-art (SOTA) models on three public transductive and inductive datasets, achieving SOTA performance in 42 out of 48 settings.
FreRA: A Frequency-Refined Augmentation for Contrastive Learning on Time Series Classification
May 29, 2025Contrastive learning has emerged as a competent approach for unsupervised representation learning. However, the design of an optimal augmentation strategy, although crucial for contrastive learning, is less explored for time series classification tasks. Existing predefined time-domain augmentation methods are primarily adopted from vision and are not specific to time series data. Consequently, this cross-modality incompatibility may distort the semantically relevant information of time series by introducing mismatched patterns into the data. To address this limitation, we present a novel perspective from the frequency domain and identify three advantages for downstream classification: global, independent, and compact. To fully utilize the three properties, we propose the lightweight yet effective Frequency Refined Augmentation (FreRA) tailored for time series contrastive learning on classification tasks, which can be seamlessly integrated with contrastive learning frameworks in a plug-and-play manner. Specifically, FreRA automatically separates critical and unimportant frequency components. Accordingly, we propose semantic-aware Identity Modification and semantic-agnostic Self-adaptive Modification to protect semantically relevant information in the critical frequency components and infuse variance into the unimportant ones respectively. Theoretically, we prove that FreRA generates semantic-preserving views. Empirically, we conduct extensive experiments on two benchmark datasets, including UCR and UEA archives, as well as five large-scale datasets on diverse applications. FreRA consistently outperforms ten leading baselines on time series classification, anomaly detection, and transfer learning tasks, demonstrating superior capabilities in contrastive representation learning and generalization in transfer learning scenarios across diverse datasets.
Efficient Heuristics Generation for Solving Combinatorial Optimization Problems Using Large Language Models
May 19, 2025


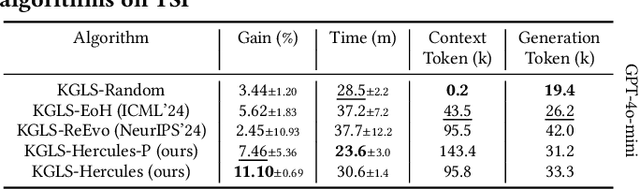
Recent studies exploited Large Language Models (LLMs) to autonomously generate heuristics for solving Combinatorial Optimization Problems (COPs), by prompting LLMs to first provide search directions and then derive heuristics accordingly. However, the absence of task-specific knowledge in prompts often leads LLMs to provide unspecific search directions, obstructing the derivation of well-performing heuristics. Moreover, evaluating the derived heuristics remains resource-intensive, especially for those semantically equivalent ones, often requiring omissible resource expenditure. To enable LLMs to provide specific search directions, we propose the Hercules algorithm, which leverages our designed Core Abstraction Prompting (CAP) method to abstract the core components from elite heuristics and incorporate them as prior knowledge in prompts. We theoretically prove the effectiveness of CAP in reducing unspecificity and provide empirical results in this work. To reduce computing resources required for evaluating the derived heuristics, we propose few-shot Performance Prediction Prompting (PPP), a first-of-its-kind method for the Heuristic Generation (HG) task. PPP leverages LLMs to predict the fitness values of newly derived heuristics by analyzing their semantic similarity to previously evaluated ones. We further develop two tailored mechanisms for PPP to enhance predictive accuracy and determine unreliable predictions, respectively. The use of PPP makes Hercules more resource-efficient and we name this variant Hercules-P. Extensive experiments across four HG tasks, five COPs, and eight LLMs demonstrate that Hercules outperforms the state-of-the-art LLM-based HG algorithms, while Hercules-P excels at minimizing required computing resources. In addition, we illustrate the effectiveness of CAP, PPP, and the other proposed mechanisms by conducting relevant ablation studies.
SoftCoT++: Test-Time Scaling with Soft Chain-of-Thought Reasoning
May 16, 2025



Test-Time Scaling (TTS) refers to approaches that improve reasoning performance by allocating extra computation during inference, without altering the model's parameters. While existing TTS methods operate in a discrete token space by generating more intermediate steps, recent studies in Coconut and SoftCoT have demonstrated that thinking in the continuous latent space can further enhance the reasoning performance. Such latent thoughts encode informative thinking without the information loss associated with autoregressive token generation, sparking increased interest in continuous-space reasoning. Unlike discrete decoding, where repeated sampling enables exploring diverse reasoning paths, latent representations in continuous space are fixed for a given input, which limits diverse exploration, as all decoded paths originate from the same latent thought. To overcome this limitation, we introduce SoftCoT++ to extend SoftCoT to the Test-Time Scaling paradigm by enabling diverse exploration of thinking paths. Specifically, we perturb latent thoughts via multiple specialized initial tokens and apply contrastive learning to promote diversity among soft thought representations. Experiments across five reasoning benchmarks and two distinct LLM architectures demonstrate that SoftCoT++ significantly boosts SoftCoT and also outperforms SoftCoT with self-consistency scaling. Moreover, it shows strong compatibility with conventional scaling techniques such as self-consistency. Source code is available at https://github.com/xuyige/SoftCoT.
A Continual Learning-driven Model for Accurate and Generalizable Segmentation of Clinically Comprehensive and Fine-grained Whole-body Anatomies in CT
Mar 16, 2025Precision medicine in the quantitative management of chronic diseases and oncology would be greatly improved if the Computed Tomography (CT) scan of any patient could be segmented, parsed and analyzed in a precise and detailed way. However, there is no such fully annotated CT dataset with all anatomies delineated for training because of the exceptionally high manual cost, the need for specialized clinical expertise, and the time required to finish the task. To this end, we proposed a novel continual learning-driven CT model that can segment complete anatomies presented using dozens of previously partially labeled datasets, dynamically expanding its capacity to segment new ones without compromising previously learned organ knowledge. Existing multi-dataset approaches are not able to dynamically segment new anatomies without catastrophic forgetting and would encounter optimization difficulty or infeasibility when segmenting hundreds of anatomies across the whole range of body regions. Our single unified CT segmentation model, CL-Net, can highly accurately segment a clinically comprehensive set of 235 fine-grained whole-body anatomies. Composed of a universal encoder, multiple optimized and pruned decoders, CL-Net is developed using 13,952 CT scans from 20 public and 16 private high-quality partially labeled CT datasets of various vendors, different contrast phases, and pathologies. Extensive evaluation demonstrates that CL-Net consistently outperforms the upper limit of an ensemble of 36 specialist nnUNets trained per dataset with the complexity of 5% model size and significantly surpasses the segmentation accuracy of recent leading Segment Anything-style medical image foundation models by large margins. Our continual learning-driven CL-Net model would lay a solid foundation to facilitate many downstream tasks of oncology and chronic diseases using the most widely adopted CT imaging.