 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRHVI-FDD: A Hierarchical Decoupling Framework for Low-Light Image Enhancement
Apr 07, 2026Low-light images often suffer from severe noise, detail loss, and color distortion, which hinder downstream multimedia analysis and retrieval tasks. The degradation in low-light images is complex: luminance and chrominance are coupled, while within the chrominance, noise and details are deeply entangled, preventing existing methods from simultaneously correcting color distortion, suppressing noise, and preserving fine details. To tackle the above challenges, we propose a novel hierarchical decoupling framework (RHVI-FDD). At the macro level, we introduce the RHVI transform, which mitigates the estimation bias caused by input noise and enables robust luminance-chrominance decoupling. At the micro level, we design a Frequency-Domain Decoupling (FDD) module with three branches for further feature separation. Using the Discrete Cosine Transform, we decompose chrominance features into low, mid, and high-frequency bands that predominantly represent global tone, local details, and noise components, which are then processed by tailored expert networks in a divide-and-conquer manner and fused via an adaptive gating module for content-aware fusion. Extensive experiments on multiple low-light datasets demonstrate that our method consistently outperforms existing state-of-the-art approaches in both objective metrics and subjective visual quality.
Efficient Heuristics Generation for Solving Combinatorial Optimization Problems Using Large Language Models
May 19, 2025


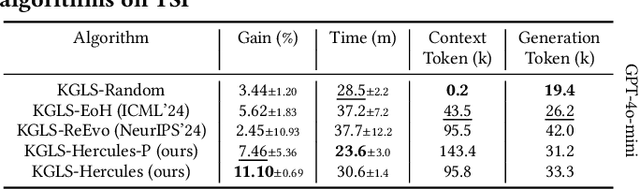
Recent studies exploited Large Language Models (LLMs) to autonomously generate heuristics for solving Combinatorial Optimization Problems (COPs), by prompting LLMs to first provide search directions and then derive heuristics accordingly. However, the absence of task-specific knowledge in prompts often leads LLMs to provide unspecific search directions, obstructing the derivation of well-performing heuristics. Moreover, evaluating the derived heuristics remains resource-intensive, especially for those semantically equivalent ones, often requiring omissible resource expenditure. To enable LLMs to provide specific search directions, we propose the Hercules algorithm, which leverages our designed Core Abstraction Prompting (CAP) method to abstract the core components from elite heuristics and incorporate them as prior knowledge in prompts. We theoretically prove the effectiveness of CAP in reducing unspecificity and provide empirical results in this work. To reduce computing resources required for evaluating the derived heuristics, we propose few-shot Performance Prediction Prompting (PPP), a first-of-its-kind method for the Heuristic Generation (HG) task. PPP leverages LLMs to predict the fitness values of newly derived heuristics by analyzing their semantic similarity to previously evaluated ones. We further develop two tailored mechanisms for PPP to enhance predictive accuracy and determine unreliable predictions, respectively. The use of PPP makes Hercules more resource-efficient and we name this variant Hercules-P. Extensive experiments across four HG tasks, five COPs, and eight LLMs demonstrate that Hercules outperforms the state-of-the-art LLM-based HG algorithms, while Hercules-P excels at minimizing required computing resources. In addition, we illustrate the effectiveness of CAP, PPP, and the other proposed mechanisms by conducting relevant ablation studies.
Neural Combinatorial Optimization Algorithms for Solving Vehicle Routing Problems: A Comprehensive Survey with Perspectives
Jun 01, 2024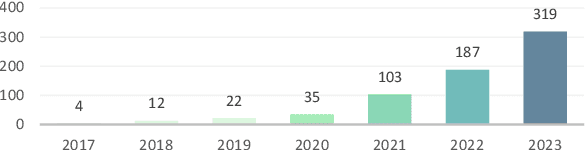
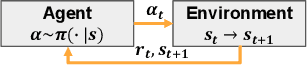
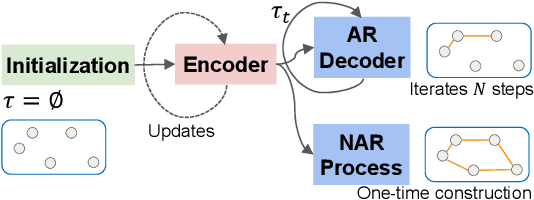
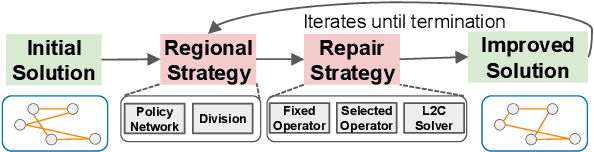
Although several surveys on Neural Combinatorial Optimization (NCO) solvers specifically designed to solve Vehicle Routing Problems (VRPs) have been conducted. These existing surveys did not cover the state-of-the-art (SOTA) NCO solvers emerged recently. More importantly, to provide a comprehensive taxonomy of NCO solvers with up-to-date coverage, based on our thorough review of relevant publications and preprints, we divide all NCO solvers into four distinct categories, namely Learning to Construct, Learning to Improve, Learning to Predict-Once, and Learning to Predict-Multiplicity solvers. Subsequently, we present the inadequacies of the SOTA solvers, including poor generalization, incapability to solve large-scale VRPs, inability to address most types of VRP variants simultaneously, and difficulty in comparing these NCO solvers with the conventional Operations Research algorithms. Simultaneously, we propose promising and viable directions to overcome these inadequacies. In addition, we compare the performance of representative NCO solvers from the Reinforcement, Supervised, and Unsupervised Learning paradigms across both small- and large-scale VRPs. Finally, following the proposed taxonomy, we provide an accompanying web page as a live repository for NCO solvers. Through this survey and the live repository, we hope to make the research community of NCO solvers for VRPs more thriving.
Troublemaker Learning for Low-Light Image Enhancement
Feb 07, 2024



Low-light image enhancement (LLIE) restores the color and brightness of underexposed images. Supervised methods suffer from high costs in collecting low/normal-light image pairs. Unsupervised methods invest substantial effort in crafting complex loss functions. We address these two challenges through the proposed TroubleMaker Learning (TML) strategy, which employs normal-light images as inputs for training. TML is simple: we first dim the input and then increase its brightness. TML is based on two core components. First, the troublemaker model (TM) constructs pseudo low-light images from normal images to relieve the cost of pairwise data. Second, the predicting model (PM) enhances the brightness of pseudo low-light images. Additionally, we incorporate an enhancing model (EM) to further improve the visual performance of PM outputs. Moreover, in LLIE tasks, characterizing global element correlations is important because more information on the same object can be captured. CNN cannot achieve this well, and self-attention has high time complexity. Accordingly, we propose Global Dynamic Convolution (GDC) with O(n) time complexity, which essentially imitates the partial calculation process of self-attention to formulate elementwise correlations. Based on the GDC module, we build the UGDC model. Extensive quantitative and qualitative experiments demonstrate that UGDC trained with TML can achieve competitive performance against state-of-the-art approaches on public datasets. The code is available at https://github.com/Rainbowman0/TML_LLIE.
Surprisingly Popular Algorithm-based Adaptive Euclidean Distance Topology Learning PSO
Aug 25, 2021



The surprisingly popular algorithm (SPA) is a powerful crowd decision model proposed in social science, which can identify the knowledge possessed in of the minority. We have modelled the SPA to select the exemplars in PSO scenarios and proposed the Surprisingly Popular Algorithm-based Comprehensive Adaptive Topology Learning Particle Swarm Optimization. Due to the significant influence of the communication topology on exemplar selection, we propose an adaptive euclidean distance dynamic topology maintenance. And then we propose the Surprisingly Popular Algorithm-based Adaptive Euclidean Distance Topology Learning Particle Swarm Optimization (SpadePSO), which use SPA to guide the direction of the exploitation sub-population. We analyze the influence of different topologies on the SPA. We evaluate the proposed SpadePSO on the full CEC2014 benchmark suite, the spread spectrum radar polyphase coding design and the ordinary differential equations models inference. The experimental results on the full CEC2014 benchmark suite show that the SpadePSO is competitive with PSO, OLPSO, HCLPSO, GL-PSO, TSLPSO and XPSO. The mean and standard deviation of SpadePSO are lower than the other PSO variants on the spread spectrum radar polyphase coding design. Finally, the ordinary differential equations models' inference results show that SpadePSO performs better than LatinPSO, specially designed for this problem. SpadePSO has lower requirements for population number than LatinPSO.
Neural Architecture Search based on Cartesian Genetic Programming Coding Method
Mar 12, 2021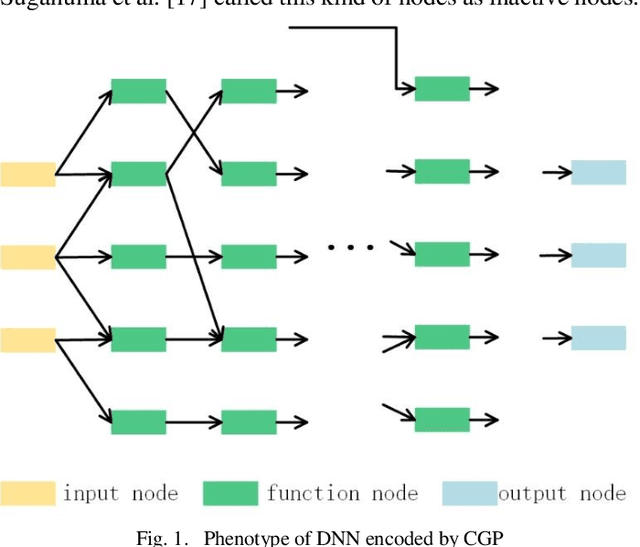
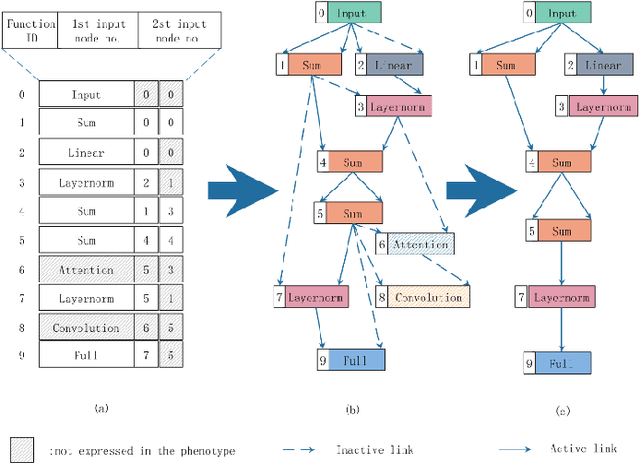
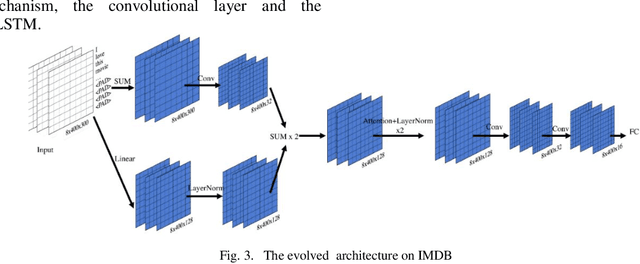
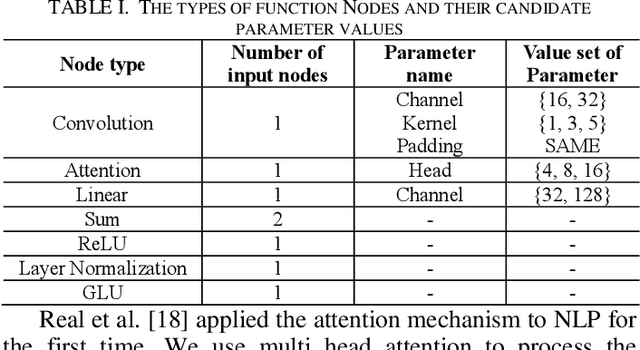
Neural architecture search (NAS) is a hot topic in the field of AutoML, and has begun to outperform human-designed architectures on many machine learning tasks. Motivated by the natural representation form of neural networks by the Cartesian genetic programming (CGP), we propose an evolutionary approach of NAS based on CGP, called CPGNAS, for CNN architectures solving sentence classification task. To evolve the CNN architectures under the framework of CGP, the existing key operations are identified as the types of function nodes of CGP and the evolutionary operations are designed based on evolutionary strategy (ES). The experimental results show that the searched architecture can reach the accuracy of human-designed architectures. The ablation tests identify the Attention function as the single key function node and the Convolution and Attention as the joint key function nodes. However, the linear transformations along could keep the accuracy of evolved architectures over 70%, which is worth of investigating in the future.
Maximal Margin Distribution Support Vector Regression with coupled Constraints-based Convex Optimization
May 05, 2019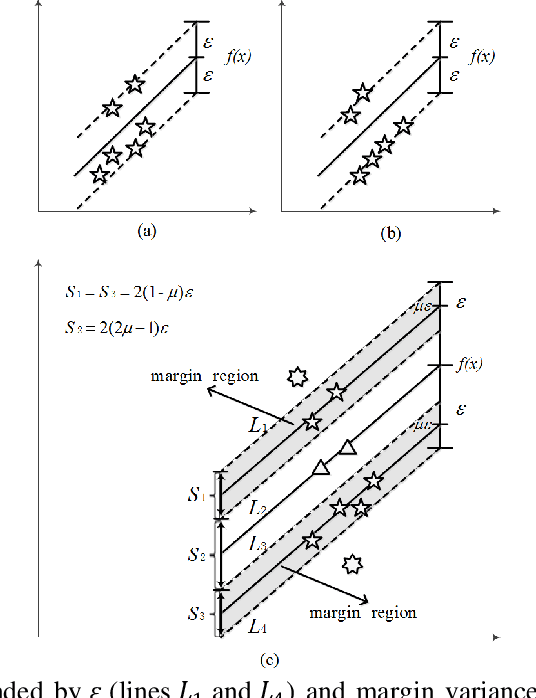
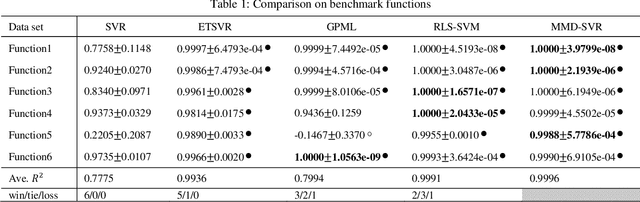
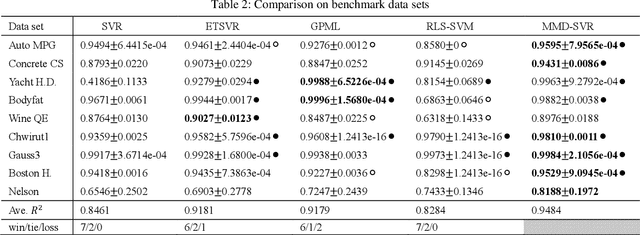
Support vector regression (SVR) is one of the most popular machine learning algorithms aiming to generate the optimal regression curve through maximizing the minimal margin of selected training samples, i.e., support vectors. Recent researchers reveal that maximizing the margin distribution of whole training dataset rather than the minimal margin of a few support vectors, is prone to achieve better generalization performance. However, the margin distribution support vector regression machines suffer difficulties resulted from solving a non-convex quadratic optimization, compared to the margin distribution strategy for support vector classification, This paper firstly proposes a maximal margin distribution model for SVR(MMD-SVR), then implementing coupled constrain factor to convert the non-convex quadratic optimization to a convex problem with linear constrains, which enhance the training feasibility and efficiency for SVR to derived from maximizing the margin distribution. The theoretical and empirical analysis illustrates the superiority of MMD-SVR. In addition, numerical experiments show that MMD-SVR could significantly improve the accuracy of prediction and generate more smooth regression curve with better generalization compared with the classic SVR.