 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThink and Answer ME: Benchmarking and Exploring Multi-Entity Reasoning Grounding in Remote Sensing
Mar 13, 2026Recent advances in reasoning language models and reinforcement learning with verifiable rewards have significantly enhanced multi-step reasoning capabilities. This progress motivates the extension of reasoning paradigms to remote sensing visual grounding task. However, existing remote sensing grounding methods remain largely confined to perception-level matching and single-entity formulations, limiting the role of explicit reasoning and inter-entity modeling. To address this challenge, we introduce a new benchmark dataset for Multi-Entity Reasoning Grounding in Remote Sensing (ME-RSRG). Based on ME-RSRG, we reformulate remote sensing grounding as a multi-entity reasoning task and propose an Entity-Aware Reasoning (EAR) framework built upon visual-linguistic foundation models. EAR generates structured reasoning traces and subject-object grounding outputs. It adopts supervised fine-tuning for cold-start initialization and is further optimized via entity-aware reward-driven Group Relative Policy Optimization (GRPO). Extensive experiments on ME-RSRG demonstrate the challenges of multi-entity reasoning and verify the effectiveness of our proposed EAR framework. Our dataset, code, and models will be available at https://github.com/CV-ShuchangLyu/ME-RSRG.
Learning Memory-Enhanced Improvement Heuristics for Flexible Job Shop Scheduling
Mar 03, 2026The rise of smart manufacturing under Industry 4.0 introduces mass customization and dynamic production, demanding more advanced and flexible scheduling techniques. The flexible job-shop scheduling problem (FJSP) has attracted significant attention due to its complex constraints and strong alignment with real-world production scenarios. Current deep reinforcement learning (DRL)-based approaches to FJSP predominantly employ constructive methods. While effective, they often fall short of reaching (near-)optimal solutions. In contrast, improvement-based methods iteratively explore the neighborhood of initial solutions and are more effective in approaching optimality. However, the flexible machine allocation in FJSP poses significant challenges to the application of this framework, including accurate state representation, effective policy learning, and efficient search strategies. To address these challenges, this paper proposes a Memory-enhanced Improvement Search framework with heterogeneous graph representation--MIStar. It employs a novel heterogeneous disjunctive graph that explicitly models the operation sequences on machines to accurately represent scheduling solutions. Moreover, a memoryenhanced heterogeneous graph neural network (MHGNN) is designed for feature extraction, leveraging historical trajectories to enhance the decision-making capability of the policy network. Finally, a parallel greedy search strategy is adopted to explore the solution space, enabling superior solutions with fewer iterations. Extensive experiments on synthetic data and public benchmarks demonstrate that MIStar significantly outperforms both traditional handcrafted improvement heuristics and state-of-the-art DRL-based constructive methods.
Trajectory Generation with Endpoint Regulation and Momentum-Aware Dynamics for Visually Impaired Scenarios
Feb 25, 2026Trajectory generation for visually impaired scenarios requires smooth and temporally consistent state in structured, low-speed dynamic environments. However, traditional jerk-based heuristic trajectory sampling with independent segment generation and conventional smoothness penalties often lead to unstable terminal behavior and state discontinuities under frequent regenerating. This paper proposes a trajectory generation approach that integrates endpoint regulation to stabilize terminal states within each segment and momentum-aware dynamics to regularize the evolution of velocity and acceleration for segment consistency. Endpoint regulation is incorporated into trajectory sampling to stabilize terminal behavior, while a momentum-aware dynamics enforces consistent velocity and acceleration evolution across consecutive trajectory segments. Experimental results demonstrate reduced acceleration peaks and lower jerk levels with decreased dispersion, smoother velocity and acceleration profiles, more stable endpoint distributions, and fewer infeasible trajectory candidates compared with a baseline planner.
Towards Interactive Intelligence for Digital Humans
Dec 15, 2025We introduce Interactive Intelligence, a novel paradigm of digital human that is capable of personality-aligned expression, adaptive interaction, and self-evolution. To realize this, we present Mio (Multimodal Interactive Omni-Avatar), an end-to-end framework composed of five specialized modules: Thinker, Talker, Face Animator, Body Animator, and Renderer. This unified architecture integrates cognitive reasoning with real-time multimodal embodiment to enable fluid, consistent interaction. Furthermore, we establish a new benchmark to rigorously evaluate the capabilities of interactive intelligence. Extensive experiments demonstrate that our framework achieves superior performance compared to state-of-the-art methods across all evaluated dimensions. Together, these contributions move digital humans beyond superficial imitation toward intelligent interaction.
TCIP: Threshold-Controlled Iterative Pyramid Network for Deformable Medical Image Registration
Oct 09, 2025Although pyramid networks have demonstrated superior performance in deformable medical image registration, their decoder architectures are inherently prone to propagating and accumulating anatomical structure misalignments. Moreover, most existing models do not adaptively determine the number of iterations for optimization under varying deformation requirements across images, resulting in either premature termination or excessive iterations that degrades registration accuracy. To effectively mitigate the accumulation of anatomical misalignments, we propose the Feature-Enhanced Residual Module (FERM) as the core component of each decoding layer in the pyramid network. FERM comprises three sequential blocks that extract anatomical semantic features, learn to suppress irrelevant features, and estimate the final deformation field, respectively. To adaptively determine the number of iterations for varying images, we propose the dual-stage Threshold-Controlled Iterative (TCI) strategy. In the first stage, TCI assesses registration stability and with asserted stability, it continues with the second stage to evaluate convergence. We coin the model that integrates FERM and TCI as Threshold-Controlled Iterative Pyramid (TCIP). Extensive experiments on three public brain MRI datasets and one abdomen CT dataset demonstrate that TCIP outperforms the state-of-the-art (SOTA) registration networks in terms of accuracy, while maintaining comparable inference speed and a compact model parameter size. Finally, we assess the generalizability of FERM and TCI by integrating them with existing registration networks and further conduct ablation studies to validate the effectiveness of these two proposed methods.
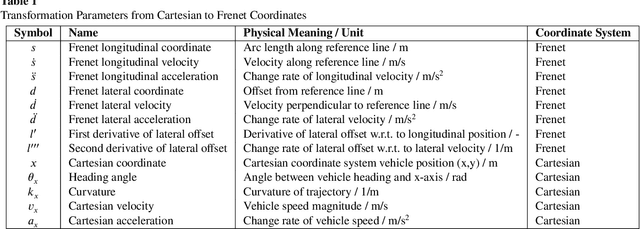
Momentum-constrained Hybrid Heuristic Trajectory Optimization Framework with Residual-enhanced DRL for Visually Impaired Scenarios
Sep 19, 2025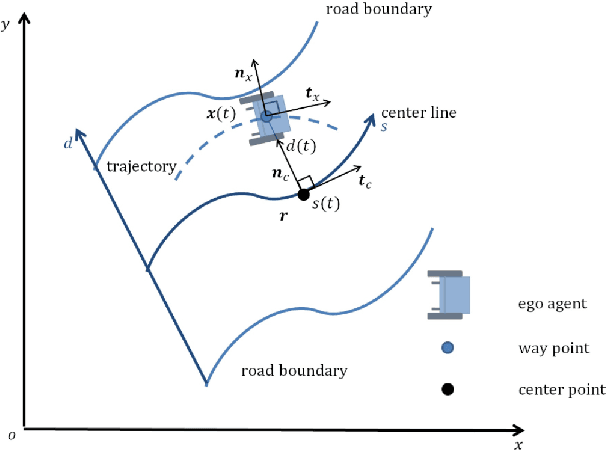
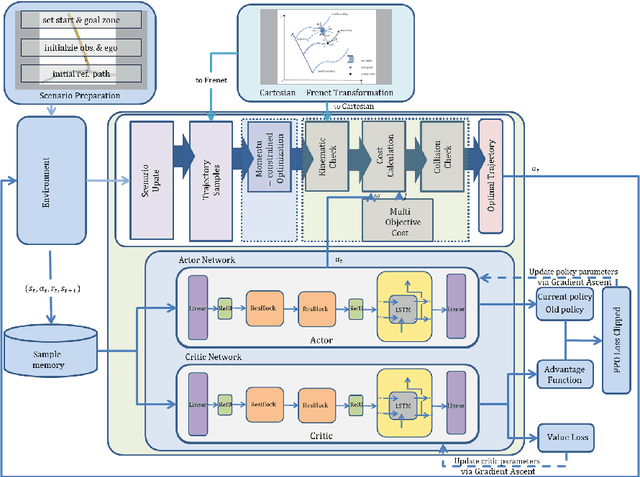

This paper proposes a momentum-constrained hybrid heuristic trajectory optimization framework (MHHTOF) tailored for assistive navigation in visually impaired scenarios, integrating trajectory sampling generation, optimization and evaluation with residual-enhanced deep reinforcement learning (DRL). In the first stage, heuristic trajectory sampling cluster (HTSC) is generated in the Frenet coordinate system using third-order interpolation with fifth-order polynomials and momentum-constrained trajectory optimization (MTO) constraints to ensure smoothness and feasibility. After first stage cost evaluation, the second stage leverages a residual-enhanced actor-critic network with LSTM-based temporal feature modeling to adaptively refine trajectory selection in the Cartesian coordinate system. A dual-stage cost modeling mechanism (DCMM) with weight transfer aligns semantic priorities across stages, supporting human-centered optimization. Experimental results demonstrate that the proposed LSTM-ResB-PPO achieves significantly faster convergence, attaining stable policy performance in approximately half the training iterations required by the PPO baseline, while simultaneously enhancing both reward outcomes and training stability. Compared to baseline method, the selected model reduces average cost and cost variance by 30.3% and 53.3%, and lowers ego and obstacle risks by over 77%. These findings validate the framework's effectiveness in enhancing robustness, safety, and real-time feasibility in complex assistive planning tasks.
GELD: A Unified Neural Model for Efficiently Solving Traveling Salesman Problems Across Different Scales
Jun 07, 2025The Traveling Salesman Problem (TSP) is a well-known combinatorial optimization problem with broad real-world applications. Recent advancements in neural network-based TSP solvers have shown promising results. Nonetheless, these models often struggle to efficiently solve both small- and large-scale TSPs using the same set of pre-trained model parameters, limiting their practical utility. To address this issue, we introduce a novel neural TSP solver named GELD, built upon our proposed broad global assessment and refined local selection framework. Specifically, GELD integrates a lightweight Global-view Encoder (GE) with a heavyweight Local-view Decoder (LD) to enrich embedding representation while accelerating the decision-making process. Moreover, GE incorporates a novel low-complexity attention mechanism, allowing GELD to achieve low inference latency and scalability to larger-scale TSPs. Additionally, we propose a two-stage training strategy that utilizes training instances of different sizes to bolster GELD's generalization ability. Extensive experiments conducted on both synthetic and real-world datasets demonstrate that GELD outperforms seven state-of-the-art models considering both solution quality and inference speed. Furthermore, GELD can be employed as a post-processing method to significantly elevate the quality of the solutions derived by existing neural TSP solvers via spending affordable additional computing time. Notably, GELD is shown as capable of solving TSPs with up to 744,710 nodes, first-of-its-kind to solve this large size TSP without relying on divide-and-conquer strategies to the best of our knowledge.
UniPTMs: The First Unified Multi-type PTM Site Prediction Model via Master-Slave Architecture-Based Multi-Stage Fusion Strategy and Hierarchical Contrastive Loss
Jun 05, 2025As a core mechanism of epigenetic regulation in eukaryotes, protein post-translational modifications (PTMs) require precise prediction to decipher dynamic life activity networks. To address the limitations of existing deep learning models in cross-modal feature fusion, domain generalization, and architectural optimization, this study proposes UniPTMs: the first unified framework for multi-type PTM prediction. The framework innovatively establishes a "Master-Slave" dual-path collaborative architecture: The master path dynamically integrates high-dimensional representations of protein sequences, structures, and evolutionary information through a Bidirectional Gated Cross-Attention (BGCA) module, while the slave path optimizes feature discrepancies and recalibration between structural and traditional features using a Low-Dimensional Fusion Network (LDFN). Complemented by a Multi-scale Adaptive convolutional Pyramid (MACP) for capturing local feature patterns and a Bidirectional Hierarchical Gated Fusion Network (BHGFN) enabling multi-level feature integration across paths, the framework employs a Hierarchical Dynamic Weighting Fusion (HDWF) mechanism to intelligently aggregate multimodal features. Enhanced by a novel Hierarchical Contrastive loss function for feature consistency optimization, UniPTMs demonstrates significant performance improvements (3.2%-11.4% MCC and 4.2%-14.3% AP increases) over state-of-the-art models across five modification types and transcends the Single-Type Prediction Paradigm. To strike a balance between model complexity and performance, we have also developed a lightweight variant named UniPTMs-mini.
Efficient Heuristics Generation for Solving Combinatorial Optimization Problems Using Large Language Models
May 19, 2025


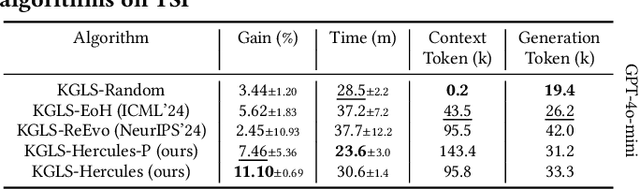
Recent studies exploited Large Language Models (LLMs) to autonomously generate heuristics for solving Combinatorial Optimization Problems (COPs), by prompting LLMs to first provide search directions and then derive heuristics accordingly. However, the absence of task-specific knowledge in prompts often leads LLMs to provide unspecific search directions, obstructing the derivation of well-performing heuristics. Moreover, evaluating the derived heuristics remains resource-intensive, especially for those semantically equivalent ones, often requiring omissible resource expenditure. To enable LLMs to provide specific search directions, we propose the Hercules algorithm, which leverages our designed Core Abstraction Prompting (CAP) method to abstract the core components from elite heuristics and incorporate them as prior knowledge in prompts. We theoretically prove the effectiveness of CAP in reducing unspecificity and provide empirical results in this work. To reduce computing resources required for evaluating the derived heuristics, we propose few-shot Performance Prediction Prompting (PPP), a first-of-its-kind method for the Heuristic Generation (HG) task. PPP leverages LLMs to predict the fitness values of newly derived heuristics by analyzing their semantic similarity to previously evaluated ones. We further develop two tailored mechanisms for PPP to enhance predictive accuracy and determine unreliable predictions, respectively. The use of PPP makes Hercules more resource-efficient and we name this variant Hercules-P. Extensive experiments across four HG tasks, five COPs, and eight LLMs demonstrate that Hercules outperforms the state-of-the-art LLM-based HG algorithms, while Hercules-P excels at minimizing required computing resources. In addition, we illustrate the effectiveness of CAP, PPP, and the other proposed mechanisms by conducting relevant ablation studies.
3D Gaussian Adaptive Reconstruction for Fourier Light-Field Microscopy
May 19, 2025Compared to light-field microscopy (LFM), which enables high-speed volumetric imaging but suffers from non-uniform spatial sampling, Fourier light-field microscopy (FLFM) introduces sub-aperture division at the pupil plane, thereby ensuring spatially invariant sampling and enhancing spatial resolution. Conventional FLFM reconstruction methods, such as Richardson-Lucy (RL) deconvolution, exhibit poor axial resolution and signal degradation due to the ill-posed nature of the inverse problem. While data-driven approaches enhance spatial resolution by leveraging high-quality paired datasets or imposing structural priors, Neural Radiance Fields (NeRF)-based methods employ physics-informed self-supervised learning to overcome these limitations, yet they are hindered by substantial computational costs and memory demands. Therefore, we propose 3D Gaussian Adaptive Tomography (3DGAT) for FLFM, a 3D gaussian splatting based self-supervised learning framework that significantly improves the volumetric reconstruction quality of FLFM while maintaining computational efficiency. Experimental results indicate that our approach achieves higher resolution and improved reconstruction accuracy, highlighting its potential to advance FLFM imaging and broaden its applications in 3D optical microscopy.