 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D Gaussian Adaptive Reconstruction for Fourier Light-Field Microscopy
May 19, 2025Compared to light-field microscopy (LFM), which enables high-speed volumetric imaging but suffers from non-uniform spatial sampling, Fourier light-field microscopy (FLFM) introduces sub-aperture division at the pupil plane, thereby ensuring spatially invariant sampling and enhancing spatial resolution. Conventional FLFM reconstruction methods, such as Richardson-Lucy (RL) deconvolution, exhibit poor axial resolution and signal degradation due to the ill-posed nature of the inverse problem. While data-driven approaches enhance spatial resolution by leveraging high-quality paired datasets or imposing structural priors, Neural Radiance Fields (NeRF)-based methods employ physics-informed self-supervised learning to overcome these limitations, yet they are hindered by substantial computational costs and memory demands. Therefore, we propose 3D Gaussian Adaptive Tomography (3DGAT) for FLFM, a 3D gaussian splatting based self-supervised learning framework that significantly improves the volumetric reconstruction quality of FLFM while maintaining computational efficiency. Experimental results indicate that our approach achieves higher resolution and improved reconstruction accuracy, highlighting its potential to advance FLFM imaging and broaden its applications in 3D optical microscopy.
Benchmarking LLM Faithfulness in RAG with Evolving Leaderboards
May 07, 2025


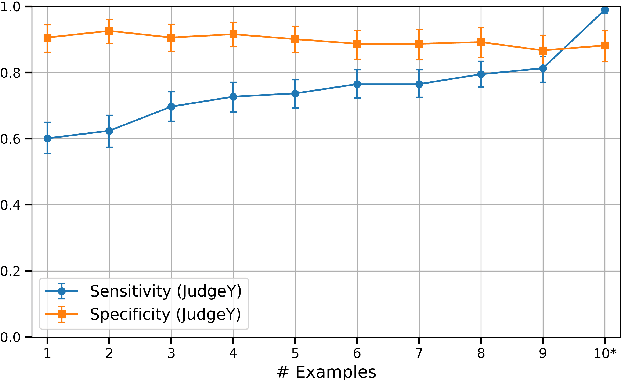
Hallucinations remain a persistent challenge for LLMs. RAG aims to reduce hallucinations by grounding responses in contexts. However, even when provided context, LLMs still frequently introduce unsupported information or contradictions. This paper presents our efforts to measure LLM hallucinations with a focus on summarization tasks, assessing how often various LLMs introduce hallucinations when summarizing documents. We discuss Vectara's existing LLM hallucination leaderboard, based on the Hughes Hallucination Evaluation Model (HHEM). While HHEM and Vectara's Hallucination Leaderboard have garnered great research interest, we examine challenges faced by HHEM and current hallucination detection methods by analyzing the effectiveness of these methods on existing hallucination datasets. To address these limitations, we propose FaithJudge, an LLM-as-a-judge approach guided by few-shot human hallucination annotations, which substantially improves automated LLM hallucination evaluation over current methods. We introduce an enhanced hallucination leaderboard centered on FaithJudge, alongside our current hallucination leaderboard, enabling more reliable benchmarking of LLMs for hallucinations in RAG.
FaithBench: A Diverse Hallucination Benchmark for Summarization by Modern LLMs
Oct 17, 2024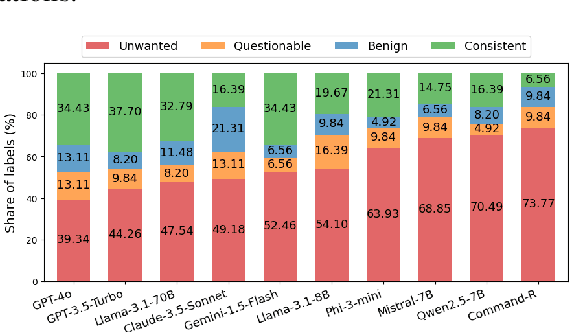
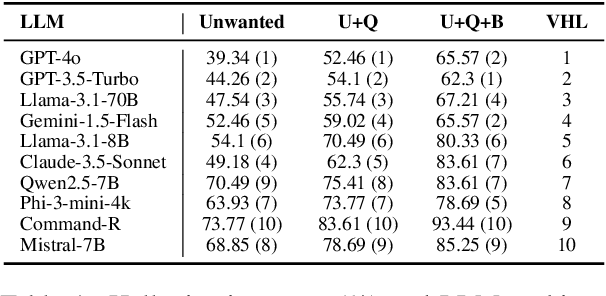
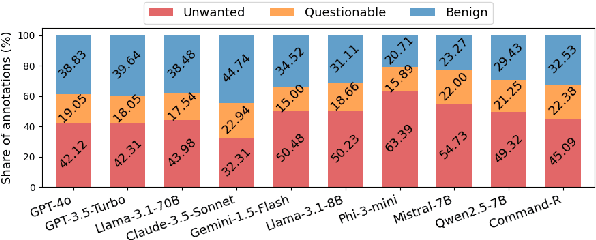
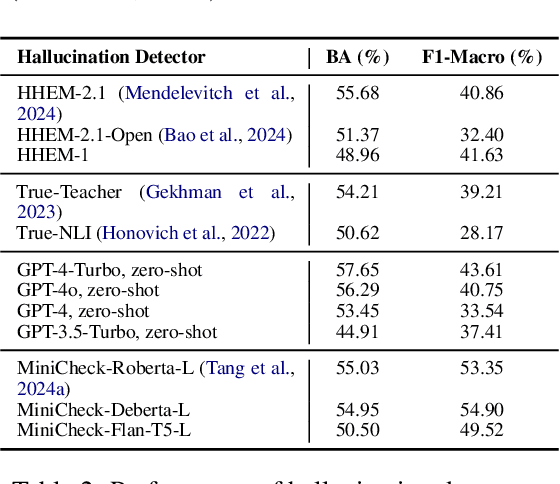
Summarization is one of the most common tasks performed by large language models (LLMs), especially in applications like Retrieval-Augmented Generation (RAG). However, existing evaluations of hallucinations in LLM-generated summaries, and evaluations of hallucination detection models both suffer from a lack of diversity and recency in the LLM and LLM families considered. This paper introduces FaithBench, a summarization hallucination benchmark comprising challenging hallucinations made by 10 modern LLMs from 8 different families, with ground truth annotations by human experts. ``Challenging'' here means summaries on which popular, state-of-the-art hallucination detection models, including GPT-4o-as-a-judge, disagreed on. Our results show GPT-4o and GPT-3.5-Turbo produce the least hallucinations. However, even the best hallucination detection models have near 50\% accuracies on FaithBench, indicating lots of room for future improvement. The repo is https://github.com/vectara/FaithBench
MMLN: Leveraging Domain Knowledge for Multimodal Diagnosis
Feb 09, 2022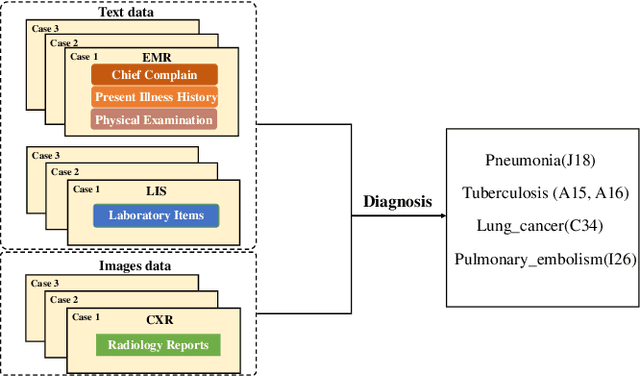
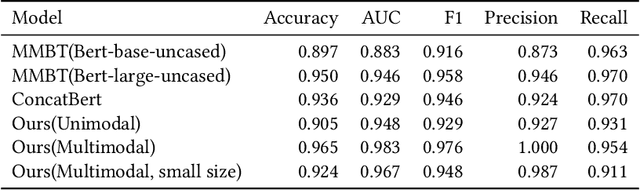
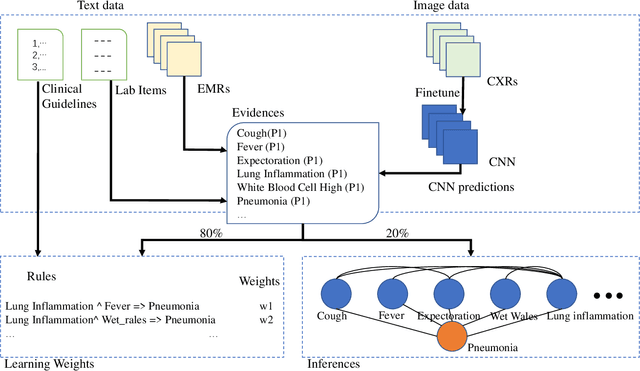

Recent studies show that deep learning models achieve good performance on medical imaging tasks such as diagnosis prediction. Among the models, multimodality has been an emerging trend, integrating different forms of data such as chest X-ray (CXR) images and electronic medical records (EMRs). However, most existing methods incorporate them in a model-free manner, which lacks theoretical support and ignores the intrinsic relations between different data sources. To address this problem, we propose a knowledge-driven and data-driven framework for lung disease diagnosis. By incorporating domain knowledge, machine learning models can reduce the dependence on labeled data and improve interpretability. We formulate diagnosis rules according to authoritative clinical medicine guidelines and learn the weights of rules from text data. Finally, a multimodal fusion consisting of text and image data is designed to infer the marginal probability of lung disease. We conduct experiments on a real-world dataset collected from a hospital. The results show that the proposed method outperforms the state-of-the-art multimodal baselines in terms of accuracy and interpretability.