 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIncorporating System-level Safety Requirements in Perception Models via Reinforcement Learning
Dec 04, 2024



Perception components in autonomous systems are often developed and optimized independently of downstream decision-making and control components, relying on established performance metrics like accuracy, precision, and recall. Traditional loss functions, such as cross-entropy loss and negative log-likelihood, focus on reducing misclassification errors but fail to consider their impact on system-level safety, overlooking the varying severities of system-level failures caused by these errors. To address this limitation, we propose a novel training paradigm that augments the perception component with an understanding of system-level safety objectives. Central to our approach is the translation of system-level safety requirements, formally specified using the rulebook formalism, into safety scores. These scores are then incorporated into the reward function of a reinforcement learning framework for fine-tuning perception models with system-level safety objectives. Simulation results demonstrate that models trained with this approach outperform baseline perception models in terms of system-level safety.
FaithBench: A Diverse Hallucination Benchmark for Summarization by Modern LLMs
Oct 17, 2024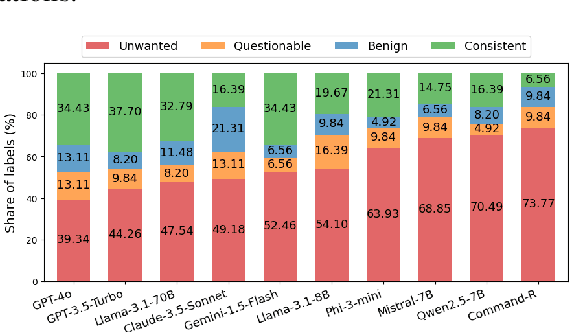
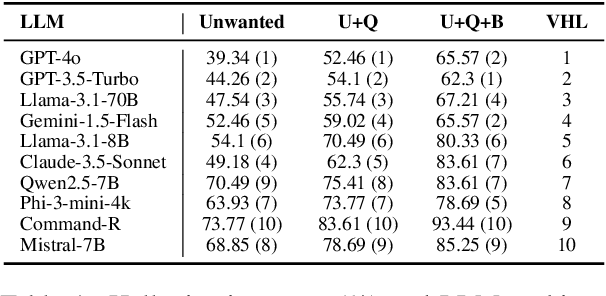
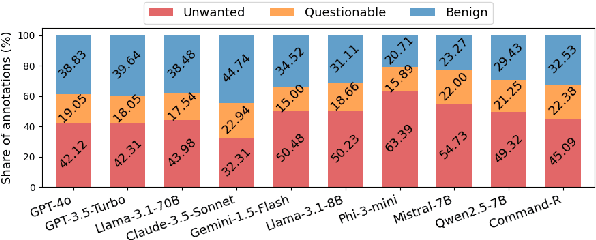
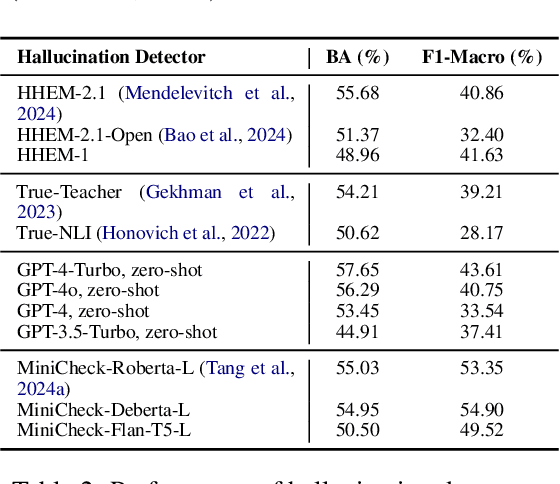
Summarization is one of the most common tasks performed by large language models (LLMs), especially in applications like Retrieval-Augmented Generation (RAG). However, existing evaluations of hallucinations in LLM-generated summaries, and evaluations of hallucination detection models both suffer from a lack of diversity and recency in the LLM and LLM families considered. This paper introduces FaithBench, a summarization hallucination benchmark comprising challenging hallucinations made by 10 modern LLMs from 8 different families, with ground truth annotations by human experts. ``Challenging'' here means summaries on which popular, state-of-the-art hallucination detection models, including GPT-4o-as-a-judge, disagreed on. Our results show GPT-4o and GPT-3.5-Turbo produce the least hallucinations. However, even the best hallucination detection models have near 50\% accuracies on FaithBench, indicating lots of room for future improvement. The repo is https://github.com/vectara/FaithBench