 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnifying Adversarial Robustness and Training Across Text Scoring Models
Jan 31, 2026Research on adversarial robustness in language models is currently fragmented across applications and attacks, obscuring shared vulnerabilities. In this work, we propose unifying the study of adversarial robustness in text scoring models spanning dense retrievers, rerankers, and reward models. This motivates adapting both attacks and adversarial training methods across model roles. Unlike open-ended generation, text scoring failures are directly testable: an attack succeeds when an irrelevant or rejected text outscores a relevant or chosen one. Using this principled lens of text scoring, we demonstrate that current adversarial training formulations for language models are often short-sighted, failing to effectively generalize across attacks. To address this, we introduce multiple adversarial training methods for text scoring models and show that combining complementary training methods can yield strong robustness while also improving task effectiveness. We also highlight the practical value of our approach for RLHF, showing that our adversarially trained reward models mitigate reward hacking and support the training of better-aligned LLMs. We provide our code and models for further study.
Conventional Contrastive Learning Often Falls Short: Improving Dense Retrieval with Cross-Encoder Listwise Distillation and Synthetic Data
May 25, 2025We investigate improving the retrieval effectiveness of embedding models through the lens of corpus-specific fine-tuning. Prior work has shown that fine-tuning with queries generated using a dataset's retrieval corpus can boost retrieval effectiveness for the dataset. However, we find that surprisingly, fine-tuning using the conventional InfoNCE contrastive loss often reduces effectiveness in state-of-the-art models. To overcome this, we revisit cross-encoder listwise distillation and demonstrate that, unlike using contrastive learning alone, listwise distillation can help more consistently improve retrieval effectiveness across multiple datasets. Additionally, we show that synthesizing more training data using diverse query types (such as claims, keywords, and questions) yields greater effectiveness than using any single query type alone, regardless of the query type used in evaluation. Our findings further indicate that synthetic queries offer comparable utility to human-written queries for training. We use our approach to train an embedding model that achieves state-of-the-art effectiveness among BERT embedding models. We release our model and both query generation and training code to facilitate further research.
Benchmarking LLM Faithfulness in RAG with Evolving Leaderboards
May 07, 2025


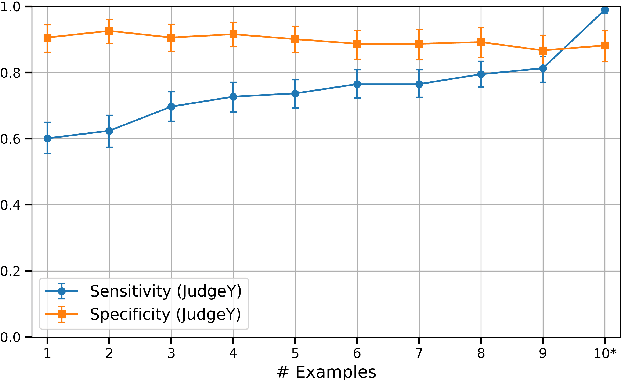
Hallucinations remain a persistent challenge for LLMs. RAG aims to reduce hallucinations by grounding responses in contexts. However, even when provided context, LLMs still frequently introduce unsupported information or contradictions. This paper presents our efforts to measure LLM hallucinations with a focus on summarization tasks, assessing how often various LLMs introduce hallucinations when summarizing documents. We discuss Vectara's existing LLM hallucination leaderboard, based on the Hughes Hallucination Evaluation Model (HHEM). While HHEM and Vectara's Hallucination Leaderboard have garnered great research interest, we examine challenges faced by HHEM and current hallucination detection methods by analyzing the effectiveness of these methods on existing hallucination datasets. To address these limitations, we propose FaithJudge, an LLM-as-a-judge approach guided by few-shot human hallucination annotations, which substantially improves automated LLM hallucination evaluation over current methods. We introduce an enhanced hallucination leaderboard centered on FaithJudge, alongside our current hallucination leaderboard, enabling more reliable benchmarking of LLMs for hallucinations in RAG.
Teaching Dense Retrieval Models to Specialize with Listwise Distillation and LLM Data Augmentation
Feb 27, 2025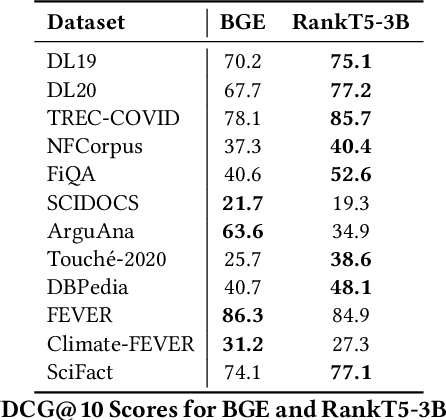
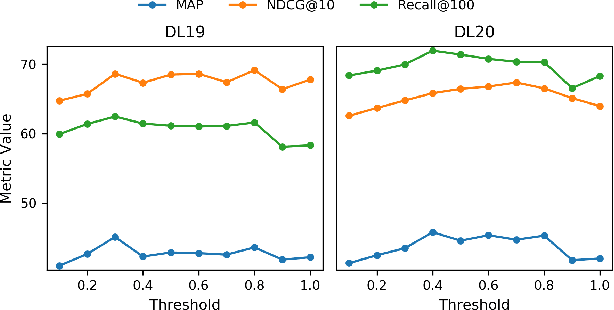

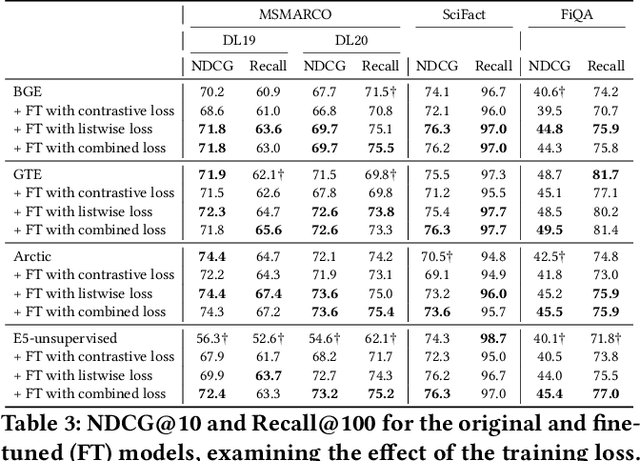
While the current state-of-the-art dense retrieval models exhibit strong out-of-domain generalization, they might fail to capture nuanced domain-specific knowledge. In principle, fine-tuning these models for specialized retrieval tasks should yield higher effectiveness than relying on a one-size-fits-all model, but in practice, results can disappoint. We show that standard fine-tuning methods using an InfoNCE loss can unexpectedly degrade effectiveness rather than improve it, even for domain-specific scenarios. This holds true even when applying widely adopted techniques such as hard-negative mining and negative de-noising. To address this, we explore a training strategy that uses listwise distillation from a teacher cross-encoder, leveraging rich relevance signals to fine-tune the retriever. We further explore synthetic query generation using large language models. Through listwise distillation and training with a diverse set of queries ranging from natural user searches and factual claims to keyword-based queries, we achieve consistent effectiveness gains across multiple datasets. Our results also reveal that synthetic queries can rival human-written queries in training utility. However, we also identify limitations, particularly in the effectiveness of cross-encoder teachers as a bottleneck. We release our code and scripts to encourage further research.
Illusions of Relevance: Using Content Injection Attacks to Deceive Retrievers, Rerankers, and LLM Judges
Jan 30, 2025



Consider a scenario in which a user searches for information, only to encounter texts flooded with misleading or non-relevant content. This scenario exemplifies a simple yet potent vulnerability in neural Information Retrieval (IR) pipelines: content injection attacks. We find that embedding models for retrieval, rerankers, and large language model (LLM) relevance judges are vulnerable to these attacks, in which adversaries insert misleading text into passages to manipulate model judgements. We identify two primary threats: (1) inserting unrelated or harmful content within passages that still appear deceptively "relevant", and (2) inserting entire queries or key query terms into passages to boost their perceived relevance. While the second tactic has been explored in prior research, we present, to our knowledge, the first empirical analysis of the first threat, demonstrating how state-of-the-art models can be easily misled. Our study systematically examines the factors that influence an attack's success, such as the placement of injected content and the balance between relevant and non-relevant material. Additionally, we explore various defense strategies, including adversarial passage classifiers, retriever fine-tuning to discount manipulated content, and prompting LLM judges to adopt a more cautious approach. However, we find that these countermeasures often involve trade-offs, sacrificing effectiveness for attack robustness and sometimes penalizing legitimate documents in the process. Our findings highlight the need for stronger defenses against these evolving adversarial strategies to maintain the trustworthiness of IR systems. We release our code and scripts to facilitate further research.
FaithBench: A Diverse Hallucination Benchmark for Summarization by Modern LLMs
Oct 17, 2024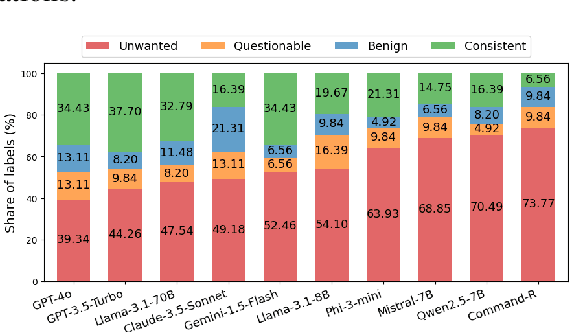
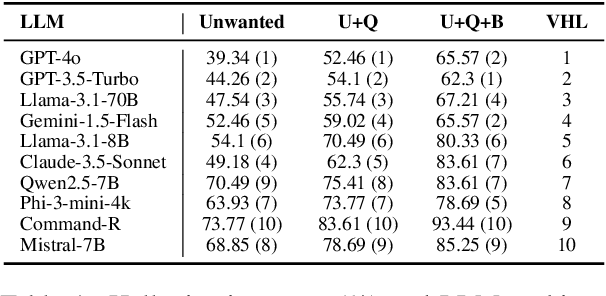
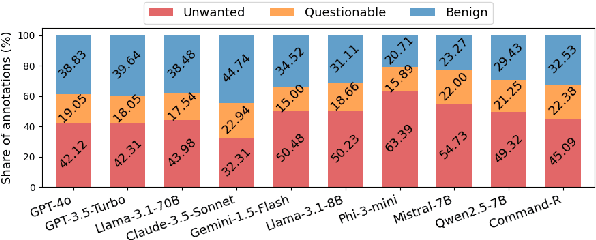
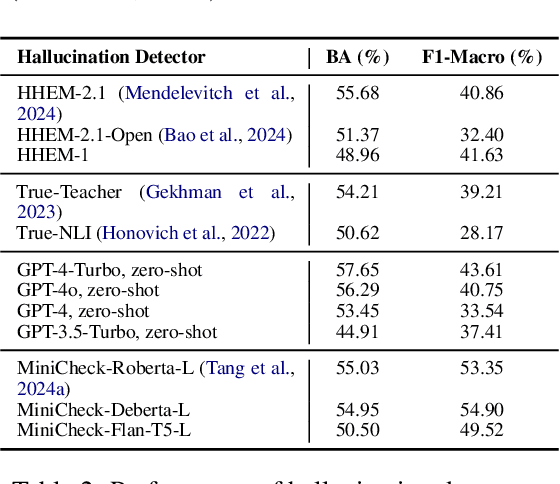
Summarization is one of the most common tasks performed by large language models (LLMs), especially in applications like Retrieval-Augmented Generation (RAG). However, existing evaluations of hallucinations in LLM-generated summaries, and evaluations of hallucination detection models both suffer from a lack of diversity and recency in the LLM and LLM families considered. This paper introduces FaithBench, a summarization hallucination benchmark comprising challenging hallucinations made by 10 modern LLMs from 8 different families, with ground truth annotations by human experts. ``Challenging'' here means summaries on which popular, state-of-the-art hallucination detection models, including GPT-4o-as-a-judge, disagreed on. Our results show GPT-4o and GPT-3.5-Turbo produce the least hallucinations. However, even the best hallucination detection models have near 50\% accuracies on FaithBench, indicating lots of room for future improvement. The repo is https://github.com/vectara/FaithBench
Can't Hide Behind the API: Stealing Black-Box Commercial Embedding Models
Jun 13, 2024
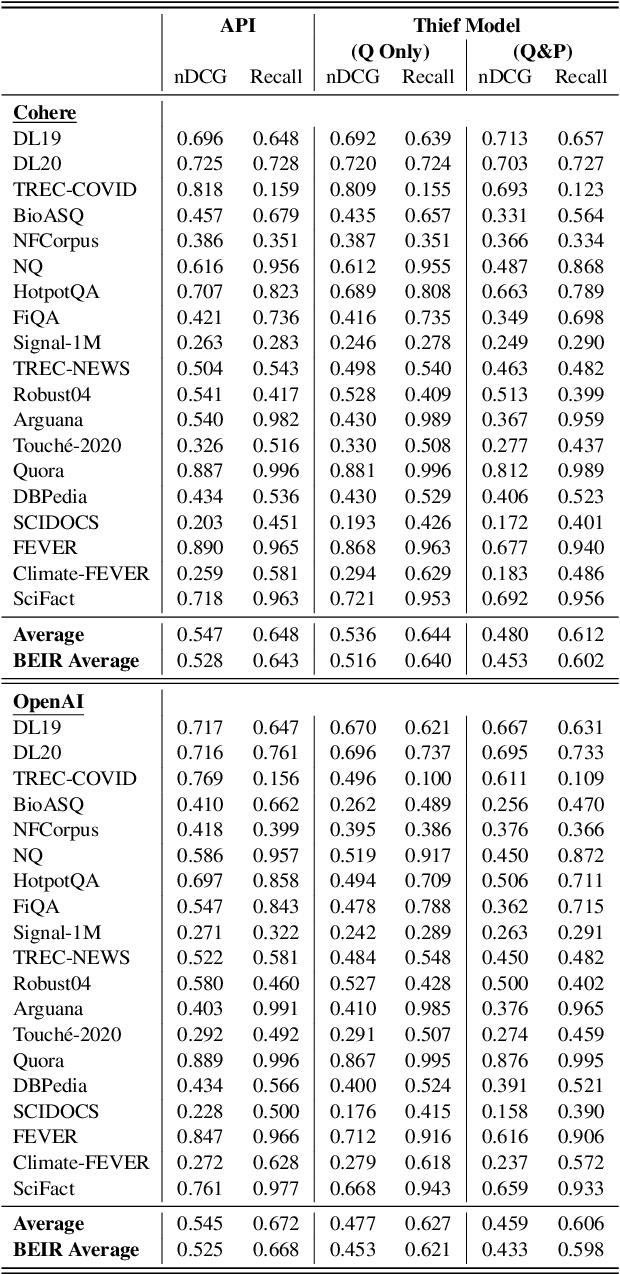
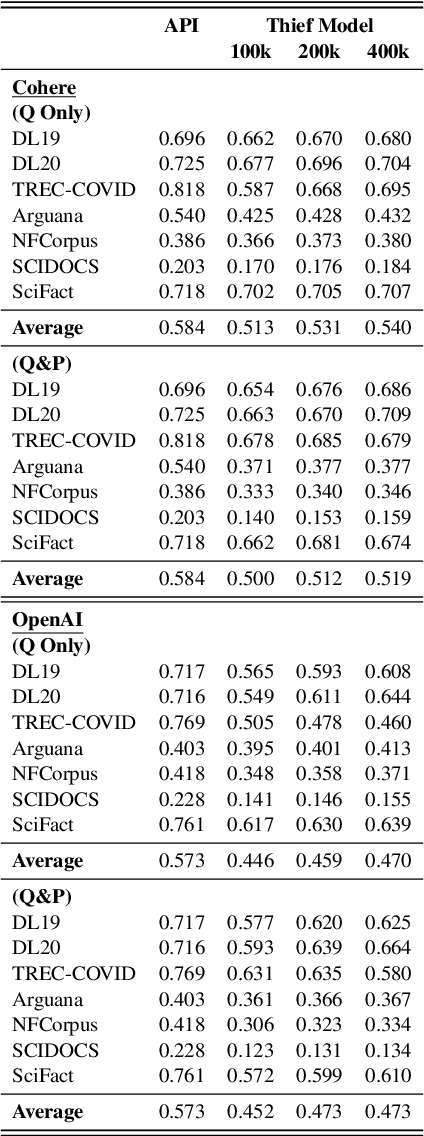
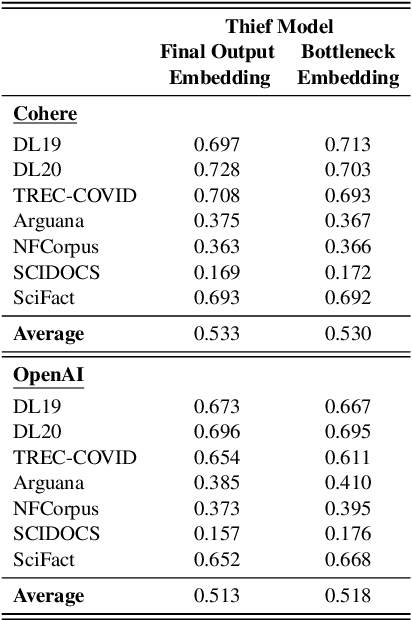
Embedding models that generate representation vectors from natural language text are widely used, reflect substantial investments, and carry significant commercial value. Companies such as OpenAI and Cohere have developed competing embedding models accessed through APIs that require users to pay for usage. In this architecture, the models are "hidden" behind APIs, but this does not mean that they are "well guarded". We present, to our knowledge, the first effort to "steal" these models for retrieval by training local models on text-embedding pairs obtained from the commercial APIs. Our experiments show using standard benchmarks that it is possible to efficiently replicate the retrieval effectiveness of the commercial embedding models using an attack that costs only around $200 to train (presumably) smaller models with fewer dimensions. Our findings raise important considerations for deploying commercial embedding models and suggest measures to mitigate the risk of model theft.
Scaling Down, LiTting Up: Efficient Zero-Shot Listwise Reranking with Seq2seq Encoder-Decoder Models
Dec 26, 2023Recent work in zero-shot listwise reranking using LLMs has achieved state-of-the-art results. However, these methods are not without drawbacks. The proposed methods rely on large LLMs with billions of parameters and limited context sizes. This paper introduces LiT5-Distill and LiT5-Score, two methods for efficient zero-shot listwise reranking, leveraging T5 sequence-to-sequence encoder-decoder models. Our approaches demonstrate competitive reranking effectiveness compared to recent state-of-the-art LLM rerankers with substantially smaller models. Through LiT5-Score, we also explore the use of cross-attention to calculate relevance scores to perform reranking, eliminating the reliance on external passage relevance labels for training. We present a range of models from 220M parameters to 3B parameters, all with strong reranking results, challenging the necessity of large-scale models for effective zero-shot reranking and opening avenues for more efficient listwise reranking solutions. We provide code and scripts to reproduce our results at https://github.com/castorini/LiT5.