 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRankLLM: A Python Package for Reranking with LLMs
May 25, 2025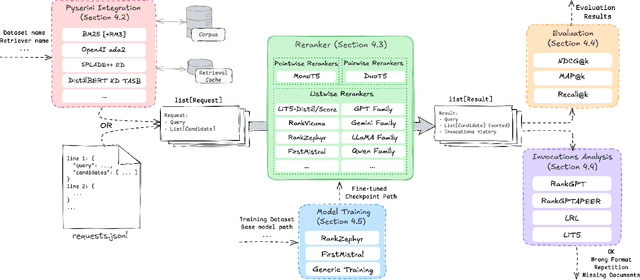
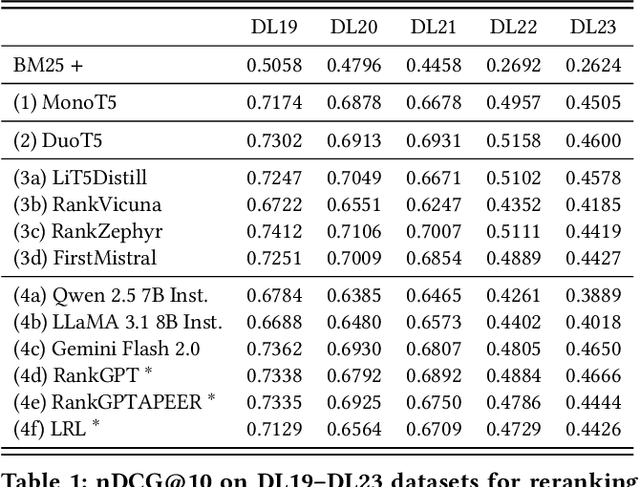
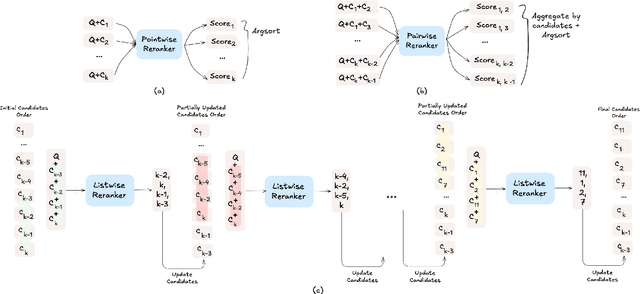
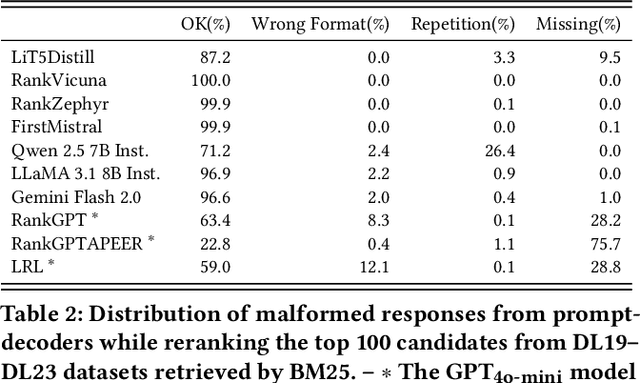
The adoption of large language models (LLMs) as rerankers in multi-stage retrieval systems has gained significant traction in academia and industry. These models refine a candidate list of retrieved documents, often through carefully designed prompts, and are typically used in applications built on retrieval-augmented generation (RAG). This paper introduces RankLLM, an open-source Python package for reranking that is modular, highly configurable, and supports both proprietary and open-source LLMs in customized reranking workflows. To improve usability, RankLLM features optional integration with Pyserini for retrieval and provides integrated evaluation for multi-stage pipelines. Additionally, RankLLM includes a module for detailed analysis of input prompts and LLM responses, addressing reliability concerns with LLM APIs and non-deterministic behavior in Mixture-of-Experts (MoE) models. This paper presents the architecture of RankLLM, along with a detailed step-by-step guide and sample code. We reproduce results from RankGPT, LRL, RankVicuna, RankZephyr, and other recent models. RankLLM integrates with common inference frameworks and a wide range of LLMs. This compatibility allows for quick reproduction of reported results, helping to speed up both research and real-world applications. The complete repository is available at rankllm.ai, and the package can be installed via PyPI.
Prompts as Auto-Optimized Training Hyperparameters: Training Best-in-Class IR Models from Scratch with 10 Gold Labels
Jun 17, 2024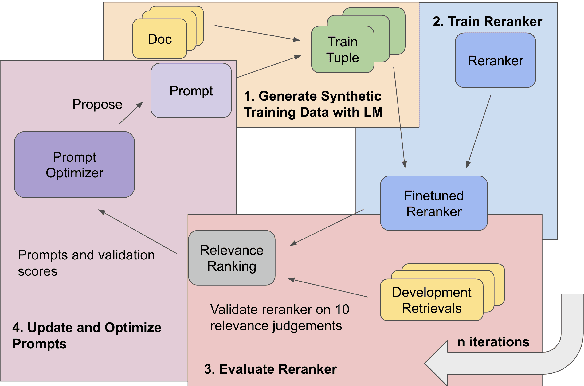
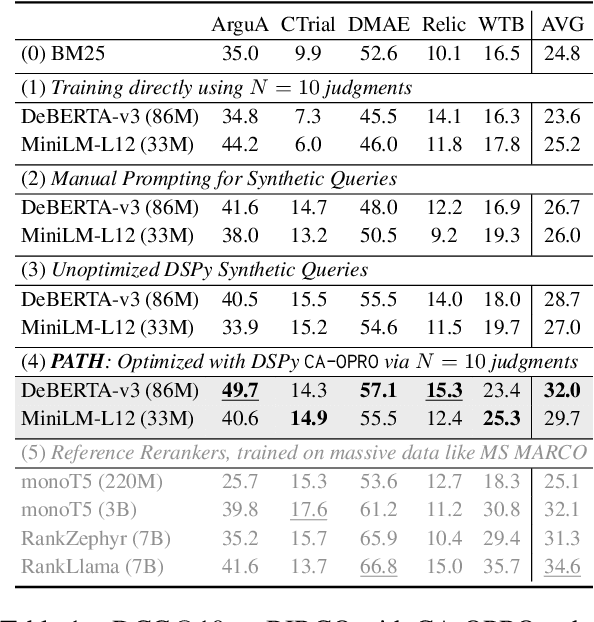
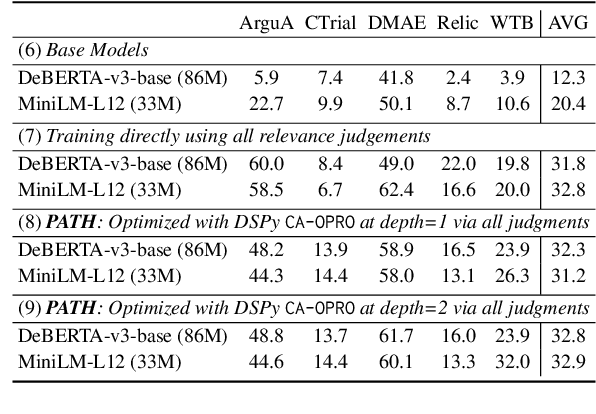

We develop a method for training small-scale (under 100M parameter) neural information retrieval models with as few as 10 gold relevance labels. The method depends on generating synthetic queries for documents using a language model (LM), and the key step is that we automatically optimize the LM prompt that is used to generate these queries based on training quality. In experiments with the BIRCO benchmark, we find that models trained with our method outperform RankZephyr and are competitive with RankLLama, both of which are 7B parameter models trained on over 100K labels. These findings point to the power of automatic prompt optimization for synthetic dataset generation.
Can't Hide Behind the API: Stealing Black-Box Commercial Embedding Models
Jun 13, 2024
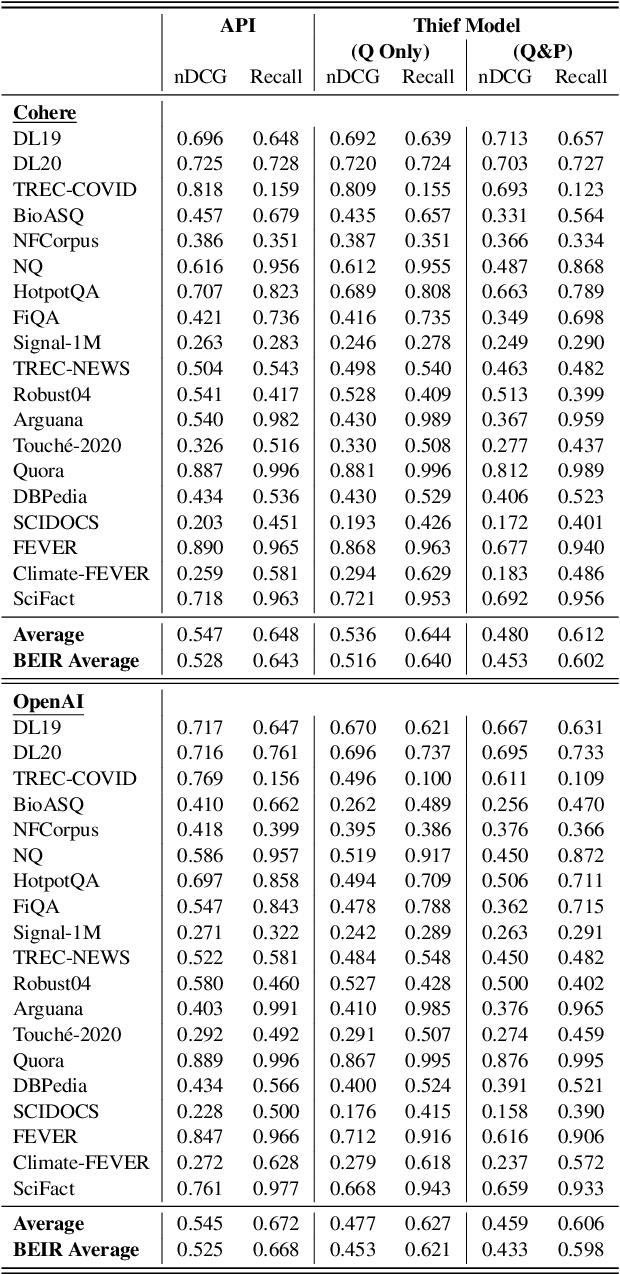
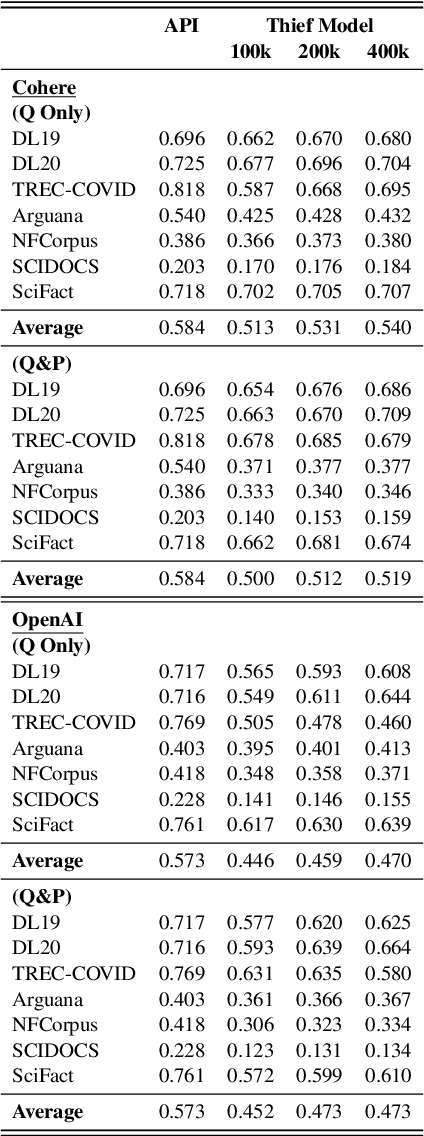
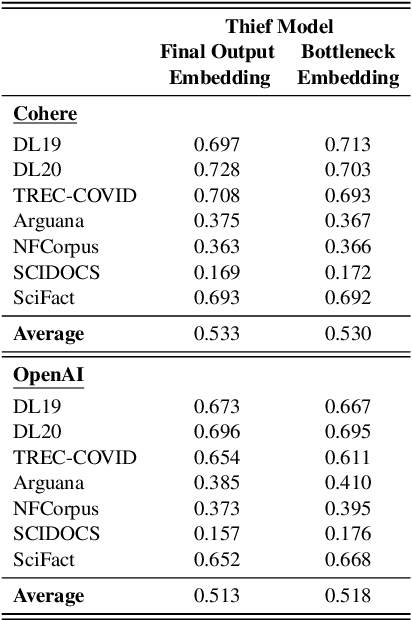
Embedding models that generate representation vectors from natural language text are widely used, reflect substantial investments, and carry significant commercial value. Companies such as OpenAI and Cohere have developed competing embedding models accessed through APIs that require users to pay for usage. In this architecture, the models are "hidden" behind APIs, but this does not mean that they are "well guarded". We present, to our knowledge, the first effort to "steal" these models for retrieval by training local models on text-embedding pairs obtained from the commercial APIs. Our experiments show using standard benchmarks that it is possible to efficiently replicate the retrieval effectiveness of the commercial embedding models using an attack that costs only around $200 to train (presumably) smaller models with fewer dimensions. Our findings raise important considerations for deploying commercial embedding models and suggest measures to mitigate the risk of model theft.
Vector Search with OpenAI Embeddings: Lucene Is All You Need
Aug 29, 2023We provide a reproducible, end-to-end demonstration of vector search with OpenAI embeddings using Lucene on the popular MS MARCO passage ranking test collection. The main goal of our work is to challenge the prevailing narrative that a dedicated vector store is necessary to take advantage of recent advances in deep neural networks as applied to search. Quite the contrary, we show that hierarchical navigable small-world network (HNSW) indexes in Lucene are adequate to provide vector search capabilities in a standard bi-encoder architecture. This suggests that, from a simple cost-benefit analysis, there does not appear to be a compelling reason to introduce a dedicated vector store into a modern "AI stack" for search, since such applications have already received substantial investments in existing, widely deployed infrastructure.