 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan't Hide Behind the API: Stealing Black-Box Commercial Embedding Models
Paper and Code
Jun 13, 2024
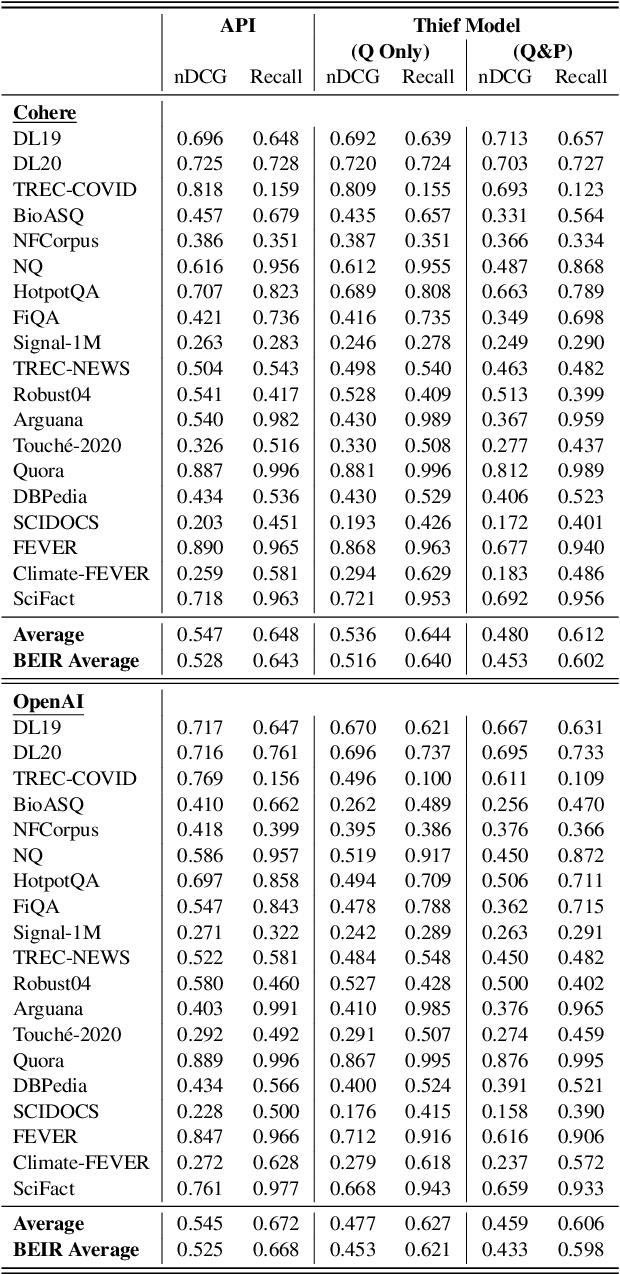
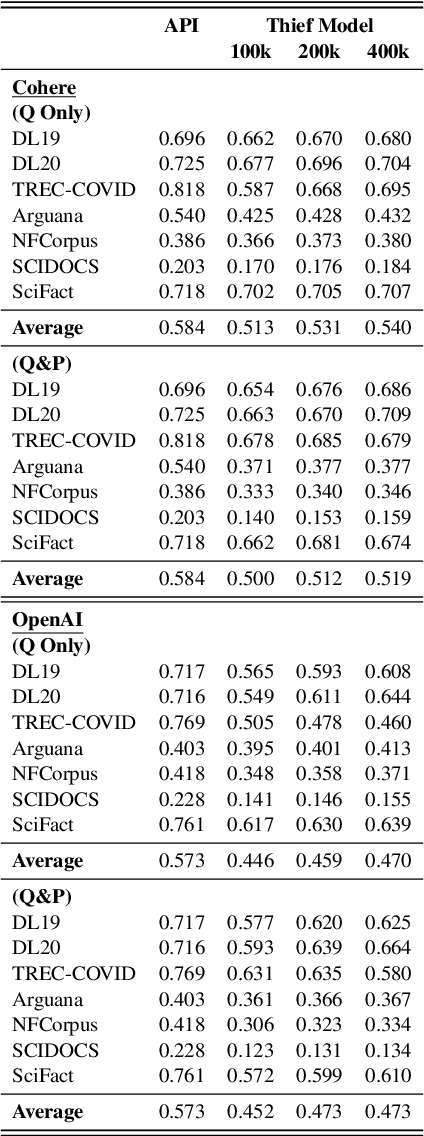
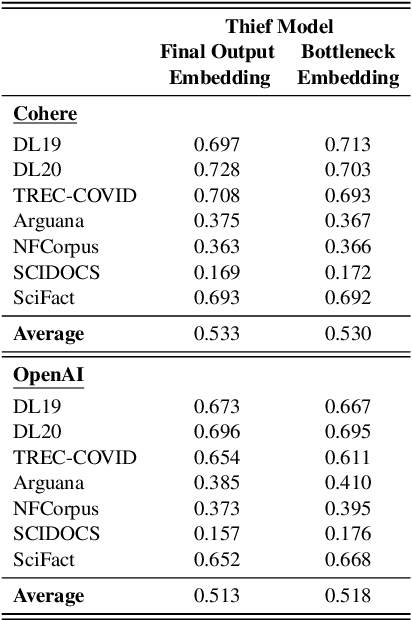
Embedding models that generate representation vectors from natural language text are widely used, reflect substantial investments, and carry significant commercial value. Companies such as OpenAI and Cohere have developed competing embedding models accessed through APIs that require users to pay for usage. In this architecture, the models are "hidden" behind APIs, but this does not mean that they are "well guarded". We present, to our knowledge, the first effort to "steal" these models for retrieval by training local models on text-embedding pairs obtained from the commercial APIs. Our experiments show using standard benchmarks that it is possible to efficiently replicate the retrieval effectiveness of the commercial embedding models using an attack that costs only around $200 to train (presumably) smaller models with fewer dimensions. Our findings raise important considerations for deploying commercial embedding models and suggest measures to mitigate the risk of model theft.