 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecursive Language Models
Dec 31, 2025We study allowing large language models (LLMs) to process arbitrarily long prompts through the lens of inference-time scaling. We propose Recursive Language Models (RLMs), a general inference strategy that treats long prompts as part of an external environment and allows the LLM to programmatically examine, decompose, and recursively call itself over snippets of the prompt. We find that RLMs successfully handle inputs up to two orders of magnitude beyond model context windows and, even for shorter prompts, dramatically outperform the quality of base LLMs and common long-context scaffolds across four diverse long-context tasks, while having comparable (or cheaper) cost per query.
Reasoning-Intensive Regression
Aug 29, 2025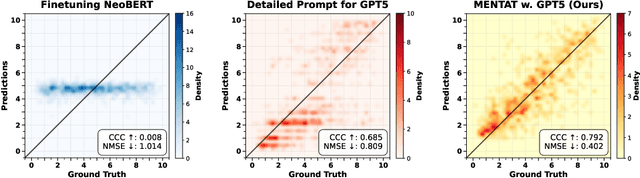
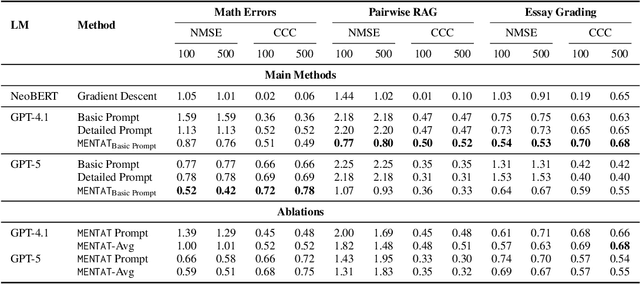


AI researchers and practitioners increasingly apply large language models (LLMs) to what we call reasoning-intensive regression (RiR), i.e. deducing subtle numerical properties from text. Unlike standard language regression tasks, e.g. for sentiment or similarity, RiR often appears instead in ad-hoc problems like rubric-based scoring or domain-specific retrieval, where much deeper analysis of text is required while only limited task-specific training data and computation are available. We cast three realistic problems as RiR tasks to establish an initial benchmark, and use that to test our hypothesis that prompting frozen LLMs and finetuning Transformer encoders via gradient descent will both often struggle in RiR. We then propose MENTAT, a simple and lightweight method that combines batch-reflective prompt optimization with neural ensemble learning. MENTAT achieves up to 65% improvement over both baselines, though substantial room remains for future advances in RiR.
Multi-module GRPO: Composing Policy Gradients and Prompt Optimization for Language Model Programs
Aug 06, 2025Group Relative Policy Optimization (GRPO) has proven to be an effective tool for post-training language models (LMs). However, AI systems are increasingly expressed as modular programs that mix together multiple LM calls with distinct prompt templates and other tools, and it is not clear how best to leverage GRPO to improve these systems. We begin to address this challenge by defining mmGRPO, a simple multi-module generalization of GRPO that groups LM calls by module across rollouts and handles variable-length and interrupted trajectories. We find that mmGRPO, composed with automatic prompt optimization, improves accuracy by 11% on average across classification, many-hop search, and privacy-preserving delegation tasks against the post-trained LM, and by 5% against prompt optimization on its own. We open-source mmGRPO in DSPy as the dspy.GRPO optimizer.
ColBERT-serve: Efficient Multi-Stage Memory-Mapped Scoring
Apr 21, 2025We study serving retrieval models, specifically late interaction models like ColBERT, to many concurrent users at once and under a small budget, in which the index may not fit in memory. We present ColBERT-serve, a novel serving system that applies a memory-mapping strategy to the ColBERT index, reducing RAM usage by 90% and permitting its deployment on cheap servers, and incorporates a multi-stage architecture with hybrid scoring, reducing ColBERT's query latency and supporting many concurrent queries in parallel.
FreshStack: Building Realistic Benchmarks for Evaluating Retrieval on Technical Documents
Apr 17, 2025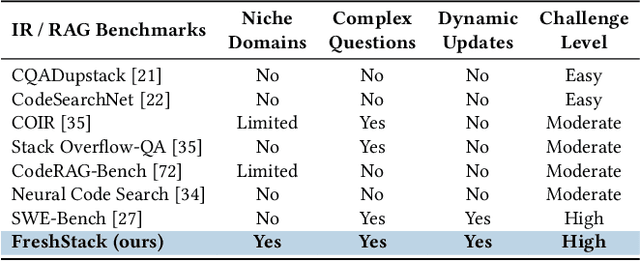
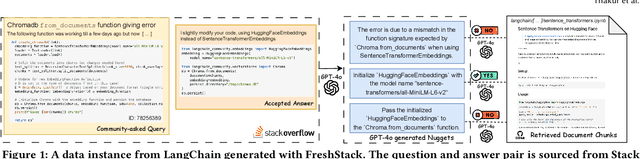
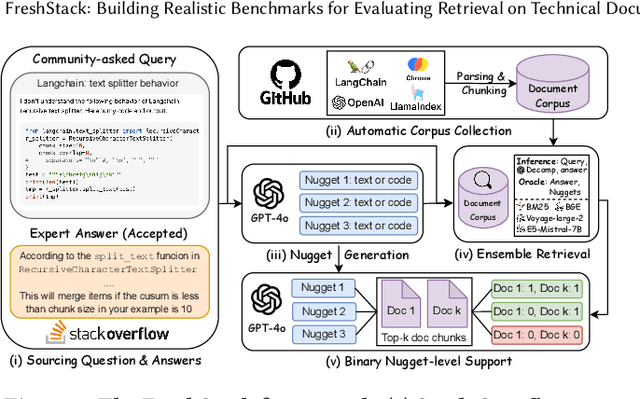

We introduce FreshStack, a reusable framework for automatically building information retrieval (IR) evaluation benchmarks from community-asked questions and answers. FreshStack conducts the following steps: (1) automatic corpus collection from code and technical documentation, (2) nugget generation from community-asked questions and answers, and (3) nugget-level support, retrieving documents using a fusion of retrieval techniques and hybrid architectures. We use FreshStack to build five datasets on fast-growing, recent, and niche topics to ensure the tasks are sufficiently challenging. On FreshStack, existing retrieval models, when applied out-of-the-box, significantly underperform oracle approaches on all five topics, denoting plenty of headroom to improve IR quality. In addition, we identify cases where rerankers do not clearly improve first-stage retrieval accuracy (two out of five topics). We hope that FreshStack will facilitate future work toward constructing realistic, scalable, and uncontaminated IR and RAG evaluation benchmarks. FreshStack datasets are available at: https://fresh-stack.github.io.
LangProBe: a Language Programs Benchmark
Feb 27, 2025
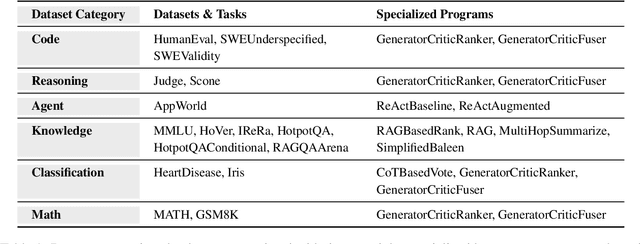
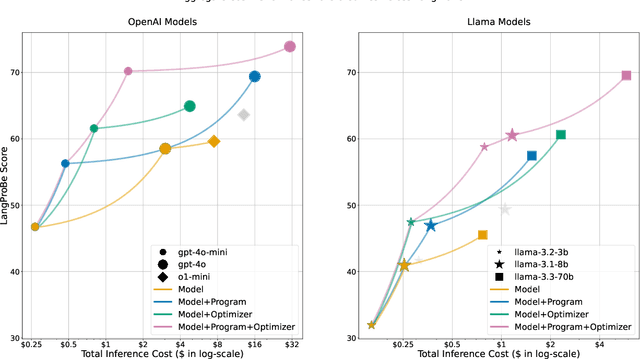
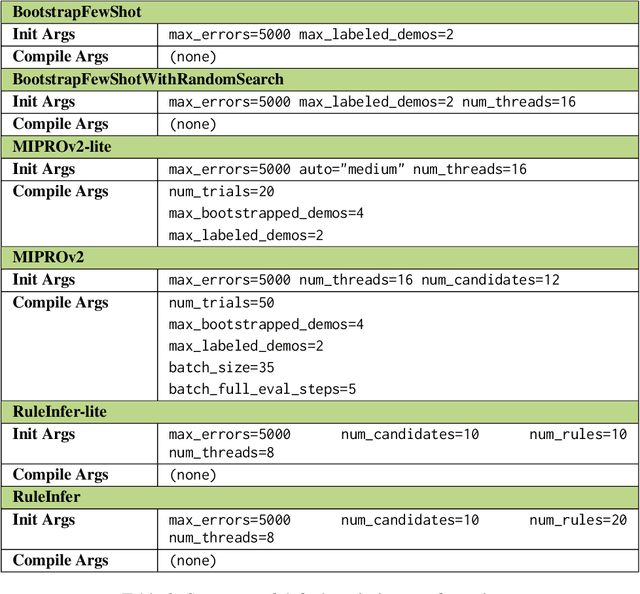
Composing language models (LMs) into multi-step language programs and automatically optimizing their modular prompts is now a mainstream paradigm for building AI systems, but the tradeoffs in this space have only scarcely been studied before. We introduce LangProBe, the first large-scale benchmark for evaluating the architectures and optimization strategies for language programs, with over 2000 combinations of tasks, architectures, optimizers, and choices of LMs. Using LangProBe, we are the first to study the impact of program architectures and optimizers (and their compositions together and with different models) on tradeoffs of quality and cost. We find that optimized language programs offer strong cost--quality Pareto improvement over raw calls to models, but simultaneously demonstrate that human judgment (or empirical decisions) about which compositions to pursue is still necessary for best performance. We will open source the code and evaluation data for LangProBe.
WARP: An Efficient Engine for Multi-Vector Retrieval
Jan 29, 2025



We study the efficiency of multi-vector retrieval methods like ColBERT and its recent variant XTR. We introduce WARP, a retrieval engine that drastically improves the efficiency of XTR-based ColBERT retrievers through three key innovations: (1) WARP$_\text{SELECT}$ for dynamic similarity imputation, (2) implicit decompression to bypass costly vector reconstruction, and (3) a two-stage reduction process for efficient scoring. Combined with optimized C++ kernels and specialized inference runtimes, WARP reduces end-to-end latency by 41x compared to XTR's reference implementation and thereby achieves a 3x speedup over PLAID from the the official ColBERT implementation. We study the efficiency of multi-vector retrieval methods like ColBERT and its recent variant XTR. We introduce WARP, a retrieval engine that drastically improves the efficiency of XTR-based ColBERT retrievers through three key innovations: (1) WARP$_\text{SELECT}$ for dynamic similarity imputation, (2) implicit decompression during retrieval, and (3) a two-stage reduction process for efficient scoring. Thanks also to highly-optimized C++ kernels and to the adoption of specialized inference runtimes, WARP can reduce end-to-end query latency relative to XTR's reference implementation by 41x. And it thereby achieves a 3x speedup over the official ColBERTv2 PLAID engine, while preserving retrieval quality.
Drowning in Documents: Consequences of Scaling Reranker Inference
Nov 18, 2024



Rerankers, typically cross-encoders, are often used to re-score the documents retrieved by cheaper initial IR systems. This is because, though expensive, rerankers are assumed to be more effective. We challenge this assumption by measuring reranker performance for full retrieval, not just re-scoring first-stage retrieval. Our experiments reveal a surprising trend: the best existing rerankers provide diminishing returns when scoring progressively more documents and actually degrade quality beyond a certain limit. In fact, in this setting, rerankers can frequently assign high scores to documents with no lexical or semantic overlap with the query. We hope that our findings will spur future research to improve reranking.
Problem-Oriented Segmentation and Retrieval: Case Study on Tutoring Conversations
Nov 12, 2024



Many open-ended conversations (e.g., tutoring lessons or business meetings) revolve around pre-defined reference materials, like worksheets or meeting bullets. To provide a framework for studying such conversation structure, we introduce Problem-Oriented Segmentation & Retrieval (POSR), the task of jointly breaking down conversations into segments and linking each segment to the relevant reference item. As a case study, we apply POSR to education where effectively structuring lessons around problems is critical yet difficult. We present LessonLink, the first dataset of real-world tutoring lessons, featuring 3,500 segments, spanning 24,300 minutes of instruction and linked to 116 SAT math problems. We define and evaluate several joint and independent approaches for POSR, including segmentation (e.g., TextTiling), retrieval (e.g., ColBERT), and large language models (LLMs) methods. Our results highlight that modeling POSR as one joint task is essential: POSR methods outperform independent segmentation and retrieval pipelines by up to +76% on joint metrics and surpass traditional segmentation methods by up to +78% on segmentation metrics. We demonstrate POSR's practical impact on downstream education applications, deriving new insights on the language and time use in real-world lesson structures.
Grounding by Trying: LLMs with Reinforcement Learning-Enhanced Retrieval
Oct 31, 2024The hallucinations of large language models (LLMs) are increasingly mitigated by allowing LLMs to search for information and to ground their answers in real sources. Unfortunately, LLMs often struggle with posing the right search queries, especially when dealing with complex or otherwise indirect topics. Observing that LLMs can learn to search for relevant facts by $\textit{trying}$ different queries and learning to up-weight queries that successfully produce relevant results, we introduce $\underline{Le}$arning to $\underline{Re}$trieve by $\underline{T}$rying (LeReT), a reinforcement learning framework that explores search queries and uses preference-based optimization to improve their quality. LeReT can improve the absolute retrieval accuracy by up to 29% and the downstream generator evaluations by 17%. The simplicity and flexibility of LeReT allows it to be applied to arbitrary off-the-shelf retrievers and makes it a promising technique for improving general LLM pipelines. Project website: http://sherylhsu.com/LeReT/.