 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEducator Attention: How computational tools can systematically identify the distribution of a key resource for students
Feb 27, 2025
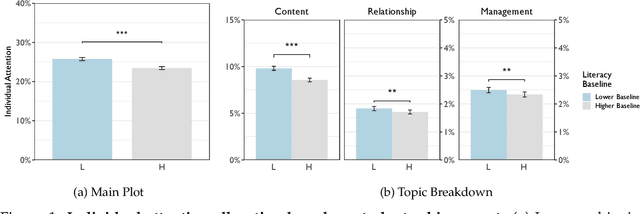
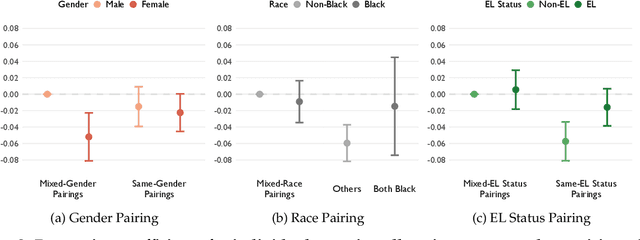
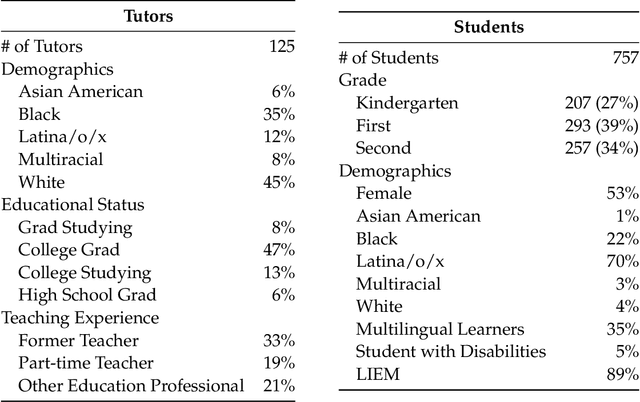
Educator attention is critical for student success, yet how educators distribute their attention across students remains poorly understood due to data and methodological constraints. This study presents the first large-scale computational analysis of educator attention patterns, leveraging over 1 million educator utterances from virtual group tutoring sessions linked to detailed student demographic and academic achievement data. Using natural language processing techniques, we systematically examine the recipient and nature of educator attention. Our findings reveal that educators often provide more attention to lower-achieving students. However, disparities emerge across demographic lines, particularly by gender. Girls tend to receive less attention when paired with boys, even when they are the lower achieving student in the group. Lower-achieving female students in mixed-gender pairs receive significantly less attention than their higher-achieving male peers, while lower-achieving male students receive significantly and substantially more attention than their higher-achieving female peers. We also find some differences by race and English learner (EL) status, with low-achieving Black students receiving additional attention only when paired with another Black student but not when paired with a non-Black peer. In contrast, higher-achieving EL students receive disproportionately more attention than their lower-achieving EL peers. This work highlights how large-scale interaction data and computational methods can uncover subtle but meaningful disparities in teaching practices, providing empirical insights to inform more equitable and effective educational strategies.
Problem-Oriented Segmentation and Retrieval: Case Study on Tutoring Conversations
Nov 12, 2024



Many open-ended conversations (e.g., tutoring lessons or business meetings) revolve around pre-defined reference materials, like worksheets or meeting bullets. To provide a framework for studying such conversation structure, we introduce Problem-Oriented Segmentation & Retrieval (POSR), the task of jointly breaking down conversations into segments and linking each segment to the relevant reference item. As a case study, we apply POSR to education where effectively structuring lessons around problems is critical yet difficult. We present LessonLink, the first dataset of real-world tutoring lessons, featuring 3,500 segments, spanning 24,300 minutes of instruction and linked to 116 SAT math problems. We define and evaluate several joint and independent approaches for POSR, including segmentation (e.g., TextTiling), retrieval (e.g., ColBERT), and large language models (LLMs) methods. Our results highlight that modeling POSR as one joint task is essential: POSR methods outperform independent segmentation and retrieval pipelines by up to +76% on joint metrics and surpass traditional segmentation methods by up to +78% on segmentation metrics. We demonstrate POSR's practical impact on downstream education applications, deriving new insights on the language and time use in real-world lesson structures.
Tutor CoPilot: A Human-AI Approach for Scaling Real-Time Expertise
Oct 03, 2024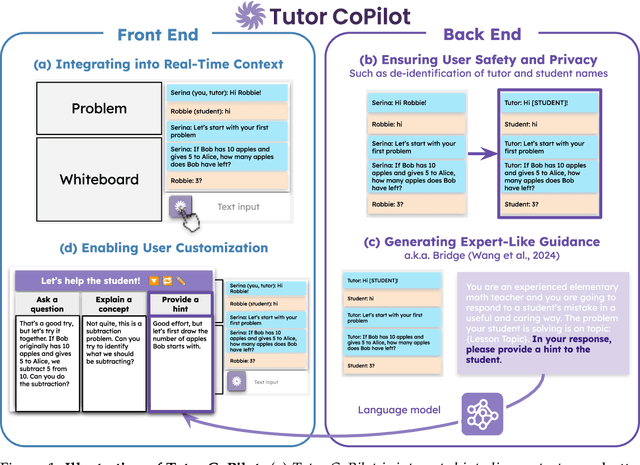
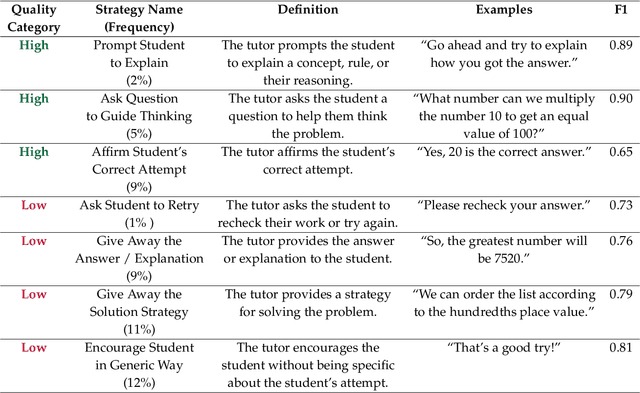
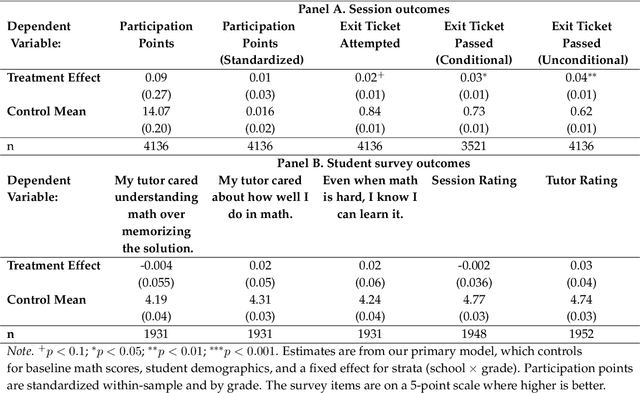
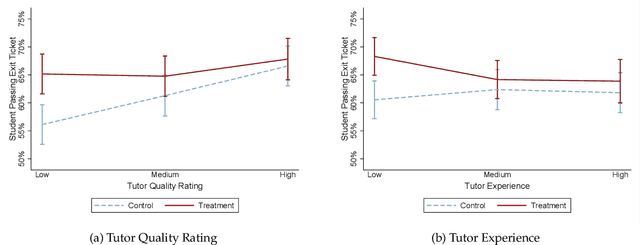
Generative AI, particularly Language Models (LMs), has the potential to transform real-world domains with societal impact, particularly where access to experts is limited. For example, in education, training novice educators with expert guidance is important for effectiveness but expensive, creating significant barriers to improving education quality at scale. This challenge disproportionately harms students from under-served communities, who stand to gain the most from high-quality education. We introduce Tutor CoPilot, a novel Human-AI approach that leverages a model of expert thinking to provide expert-like guidance to tutors as they tutor. This study is the first randomized controlled trial of a Human-AI system in live tutoring, involving 900 tutors and 1,800 K-12 students from historically under-served communities. Following a preregistered analysis plan, we find that students working with tutors that have access to Tutor CoPilot are 4 percentage points (p.p.) more likely to master topics (p<0.01). Notably, students of lower-rated tutors experienced the greatest benefit, improving mastery by 9 p.p. We find that Tutor CoPilot costs only $20 per-tutor annually. We analyze 550,000+ messages using classifiers to identify pedagogical strategies, and find that tutors with access to Tutor CoPilot are more likely to use high-quality strategies to foster student understanding (e.g., asking guiding questions) and less likely to give away the answer to the student. Tutor interviews highlight how Tutor CoPilot's guidance helps tutors to respond to student needs, though they flag issues in Tutor CoPilot, such as generating suggestions that are not grade-level appropriate. Altogether, our study of Tutor CoPilot demonstrates how Human-AI systems can scale expertise in real-world domains, bridge gaps in skills and create a future where high-quality education is accessible to all students.
Evaluating Language Model Math Reasoning via Grounding in Educational Curricula
Aug 08, 2024



Our work presents a novel angle for evaluating language models' (LMs) mathematical abilities, by investigating whether they can discern skills and concepts enabled by math content. We contribute two datasets: one consisting of 385 fine-grained descriptions of K-12 math skills and concepts, or standards, from Achieve the Core (ATC), and another of 9.9K problems labeled with these standards (MathFish). Working with experienced teachers, we find that LMs struggle to tag and verify standards linked to problems, and instead predict labels that are close to ground truth, but differ in subtle ways. We also show that LMs often generate problems that do not fully align with standards described in prompts. Finally, we categorize problems in GSM8k using math standards, allowing us to better understand why some problems are more difficult to solve for models than others.
Backtracing: Retrieving the Cause of the Query
Mar 06, 2024



Many online content portals allow users to ask questions to supplement their understanding (e.g., of lectures). While information retrieval (IR) systems may provide answers for such user queries, they do not directly assist content creators -- such as lecturers who want to improve their content -- identify segments that _caused_ a user to ask those questions. We introduce the task of backtracing, in which systems retrieve the text segment that most likely caused a user query. We formalize three real-world domains for which backtracing is important in improving content delivery and communication: understanding the cause of (a) student confusion in the Lecture domain, (b) reader curiosity in the News Article domain, and (c) user emotion in the Conversation domain. We evaluate the zero-shot performance of popular information retrieval methods and language modeling methods, including bi-encoder, re-ranking and likelihood-based methods and ChatGPT. While traditional IR systems retrieve semantically relevant information (e.g., details on "projection matrices" for a query "does projecting multiple times still lead to the same point?"), they often miss the causally relevant context (e.g., the lecturer states "projecting twice gets me the same answer as one projection"). Our results show that there is room for improvement on backtracing and it requires new retrieval approaches. We hope our benchmark serves to improve future retrieval systems for backtracing, spawning systems that refine content generation and identify linguistic triggers influencing user queries. Our code and data are open-sourced: https://github.com/rosewang2008/backtracing.
Edu-ConvoKit: An Open-Source Library for Education Conversation Data
Feb 07, 2024We introduce Edu-ConvoKit, an open-source library designed to handle pre-processing, annotation and analysis of conversation data in education. Resources for analyzing education conversation data are scarce, making the research challenging to perform and therefore hard to access. We address these challenges with Edu-ConvoKit. Edu-ConvoKit is open-source (https://github.com/stanfordnlp/edu-convokit ), pip-installable (https://pypi.org/project/edu-convokit/ ), with comprehensive documentation (https://edu-convokit.readthedocs.io/en/latest/ ). Our demo video is available at: https://youtu.be/zdcI839vAko?si=h9qlnl76ucSuXb8- . We include additional resources, such as Colab applications of Edu-ConvoKit to three diverse education datasets and a repository of Edu-ConvoKit related papers, that can be found in our GitHub repository.
Step-by-Step Remediation of Students' Mathematical Mistakes
Oct 16, 2023



Scaling high-quality tutoring is a major challenge in education. Because of the growing demand, many platforms employ novice tutors who, unlike professional educators, struggle to effectively address student mistakes and thus fail to seize prime learning opportunities for students. In this paper, we explore the potential for large language models (LLMs) to assist math tutors in remediating student mistakes. We present ReMath, a benchmark co-developed with experienced math teachers that deconstructs their thought process for remediation. The benchmark consists of three step-by-step tasks: (1) infer the type of student error, (2) determine the strategy to address the error, and (3) generate a response that incorporates that information. We evaluate the performance of state-of-the-art instruct-tuned and dialog models on ReMath. Our findings suggest that although models consistently improve upon original tutor responses, we cannot rely on models alone to remediate mistakes. Providing models with the error type (e.g., the student is guessing) and strategy (e.g., simplify the problem) leads to a 75% improvement in the response quality over models without that information. Nonetheless, despite the improvement, the quality of the best model's responses still falls short of experienced math teachers. Our work sheds light on the potential and limitations of using current LLMs to provide high-quality learning experiences for both tutors and students at scale. Our work is open-sourced at this link: \url{https://github.com/rosewang2008/remath}.
SIGHT: A Large Annotated Dataset on Student Insights Gathered from Higher Education Transcripts
Jun 15, 2023



Lectures are a learning experience for both students and teachers. Students learn from teachers about the subject material, while teachers learn from students about how to refine their instruction. However, online student feedback is unstructured and abundant, making it challenging for teachers to learn and improve. We take a step towards tackling this challenge. First, we contribute a dataset for studying this problem: SIGHT is a large dataset of 288 math lecture transcripts and 15,784 comments collected from the Massachusetts Institute of Technology OpenCourseWare (MIT OCW) YouTube channel. Second, we develop a rubric for categorizing feedback types using qualitative analysis. Qualitative analysis methods are powerful in uncovering domain-specific insights, however they are costly to apply to large data sources. To overcome this challenge, we propose a set of best practices for using large language models (LLMs) to cheaply classify the comments at scale. We observe a striking correlation between the model's and humans' annotation: Categories with consistent human annotations (>$0.9$ inter-rater reliability, IRR) also display higher human-model agreement (>$0.7$), while categories with less consistent human annotations ($0.7$-$0.8$ IRR) correspondingly demonstrate lower human-model agreement ($0.3$-$0.5$). These techniques uncover useful student feedback from thousands of comments, costing around $\$0.002$ per comment. We conclude by discussing exciting future directions on using online student feedback and improving automated annotation techniques for qualitative research.
Is ChatGPT a Good Teacher Coach? Measuring Zero-Shot Performance For Scoring and Providing Actionable Insights on Classroom Instruction
Jun 05, 2023Coaching, which involves classroom observation and expert feedback, is a widespread and fundamental part of teacher training. However, the majority of teachers do not have access to consistent, high quality coaching due to limited resources and access to expertise. We explore whether generative AI could become a cost-effective complement to expert feedback by serving as an automated teacher coach. In doing so, we propose three teacher coaching tasks for generative AI: (A) scoring transcript segments based on classroom observation instruments, (B) identifying highlights and missed opportunities for good instructional strategies, and (C) providing actionable suggestions for eliciting more student reasoning. We recruit expert math teachers to evaluate the zero-shot performance of ChatGPT on each of these tasks for elementary math classroom transcripts. Our results reveal that ChatGPT generates responses that are relevant to improving instruction, but they are often not novel or insightful. For example, 82% of the model's suggestions point to places in the transcript where the teacher is already implementing that suggestion. Our work highlights the challenges of producing insightful, novel and truthful feedback for teachers while paving the way for future research to address these obstacles and improve the capacity of generative AI to coach teachers.
Solving Math Word Problems by Combining Language Models With Symbolic Solvers
Apr 16, 2023



Automatically generating high-quality step-by-step solutions to math word problems has many applications in education. Recently, combining large language models (LLMs) with external tools to perform complex reasoning and calculation has emerged as a promising direction for solving math word problems, but prior approaches such as Program-Aided Language model (PAL) are biased towards simple procedural problems and less effective for problems that require declarative reasoning. We propose an approach that combines an LLM that can incrementally formalize word problems as a set of variables and equations with an external symbolic solver that can solve the equations. Our approach achieves comparable accuracy to the original PAL on the GSM8K benchmark of math word problems and outperforms PAL by an absolute 20% on ALGEBRA, a new dataset of more challenging word problems extracted from Algebra textbooks. Our work highlights the benefits of using declarative and incremental representations when interfacing with an external tool for solving complex math word problems. Our data and prompts are publicly available at https://github.com/joyheyueya/declarative-math-word-problem.