 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Aftermath of DrawEduMath: Vision Language Models Underperform with Struggling Students and Misdiagnose Errors
Mar 01, 2026Effective mathematics education requires identifying and responding to students' mistakes. For AI to support pedagogical applications, models must perform well across different levels of student proficiency. Our work provides an extensive, year-long snapshot of how 11 vision-language models (VLMs) perform on DrawEduMath, a QA benchmark involving real students' handwritten, hand-drawn responses to math problems. We find that models' weaknesses concentrate on a core component of math education: student error. All evaluated VLMs underperform when describing work from students who require more pedagogical help, and across all QA, they struggle the most on questions related to assessing student error. Thus, while VLMs may be optimized to be math problem solving experts, our results suggest that they require alternative development incentives to adequately support educational use cases.
Tell, Don't Show: Leveraging Language Models' Abstractive Retellings to Model Literary Themes
May 29, 2025Conventional bag-of-words approaches for topic modeling, like latent Dirichlet allocation (LDA), struggle with literary text. Literature challenges lexical methods because narrative language focuses on immersive sensory details instead of abstractive description or exposition: writers are advised to "show, don't tell." We propose Retell, a simple, accessible topic modeling approach for literature. Here, we prompt resource-efficient, generative language models (LMs) to tell what passages show, thereby translating narratives' surface forms into higher-level concepts and themes. By running LDA on LMs' retellings of passages, we can obtain more precise and informative topics than by running LDA alone or by directly asking LMs to list topics. To investigate the potential of our method for cultural analytics, we compare our method's outputs to expert-guided annotations in a case study on racial/cultural identity in high school English language arts books.
DrawEduMath: Evaluating Vision Language Models with Expert-Annotated Students' Hand-Drawn Math Images
Jan 24, 2025



In real-world settings, vision language models (VLMs) should robustly handle naturalistic, noisy visual content as well as domain-specific language and concepts. For example, K-12 educators using digital learning platforms may need to examine and provide feedback across many images of students' math work. To assess the potential of VLMs to support educators in settings like this one, we introduce DrawEduMath, an English-language dataset of 2,030 images of students' handwritten responses to K-12 math problems. Teachers provided detailed annotations, including free-form descriptions of each image and 11,661 question-answer (QA) pairs. These annotations capture a wealth of pedagogical insights, ranging from students' problem-solving strategies to the composition of their drawings, diagrams, and writing. We evaluate VLMs on teachers' QA pairs, as well as 44,362 synthetic QA pairs derived from teachers' descriptions using language models (LMs). We show that even state-of-the-art VLMs leave much room for improvement on DrawEduMath questions. We also find that synthetic QAs, though imperfect, can yield similar model rankings as teacher-written QAs. We release DrawEduMath to support the evaluation of VLMs' abilities to reason mathematically over images gathered with educational contexts in mind.
On Classification with Large Language Models in Cultural Analytics
Oct 15, 2024



In this work, we survey the way in which classification is used as a sensemaking practice in cultural analytics, and assess where large language models can fit into this landscape. We identify ten tasks supported by publicly available datasets on which we empirically assess the performance of LLMs compared to traditional supervised methods, and explore the ways in which LLMs can be employed for sensemaking goals beyond mere accuracy. We find that prompt-based LLMs are competitive with traditional supervised models for established tasks, but perform less well on de novo tasks. In addition, LLMs can assist sensemaking by acting as an intermediary input to formal theory testing.
Evaluating Language Model Math Reasoning via Grounding in Educational Curricula
Aug 08, 2024



Our work presents a novel angle for evaluating language models' (LMs) mathematical abilities, by investigating whether they can discern skills and concepts enabled by math content. We contribute two datasets: one consisting of 385 fine-grained descriptions of K-12 math skills and concepts, or standards, from Achieve the Core (ATC), and another of 9.9K problems labeled with these standards (MathFish). Working with experienced teachers, we find that LMs struggle to tag and verify standards linked to problems, and instead predict labels that are close to ground truth, but differ in subtle ways. We also show that LMs often generate problems that do not fully align with standards described in prompts. Finally, we categorize problems in GSM8k using math standards, allowing us to better understand why some problems are more difficult to solve for models than others.
Dolma: an Open Corpus of Three Trillion Tokens for Language Model Pretraining Research
Jan 31, 2024



Language models have become a critical technology to tackling a wide range of natural language processing tasks, yet many details about how the best-performing language models were developed are not reported. In particular, information about their pretraining corpora is seldom discussed: commercial language models rarely provide any information about their data; even open models rarely release datasets they are trained on, or an exact recipe to reproduce them. As a result, it is challenging to conduct certain threads of language modeling research, such as understanding how training data impacts model capabilities and shapes their limitations. To facilitate open research on language model pretraining, we release Dolma, a three trillion tokens English corpus, built from a diverse mixture of web content, scientific papers, code, public-domain books, social media, and encyclopedic materials. In addition, we open source our data curation toolkit to enable further experimentation and reproduction of our work. In this report, we document Dolma, including its design principles, details about its construction, and a summary of its contents. We interleave this report with analyses and experimental results from training language models on intermediate states of Dolma to share what we have learned about important data curation practices, including the role of content or quality filters, deduplication, and multi-source mixing. Dolma has been used to train OLMo, a state-of-the-art, open language model and framework designed to build and study the science of language modeling.
AboutMe: Using Self-Descriptions in Webpages to Document the Effects of English Pretraining Data Filters
Jan 16, 2024Large language models' (LLMs) abilities are drawn from their pretraining data, and model development begins with data curation. However, decisions around what data is retained or removed during this initial stage is under-scrutinized. In our work, we ground web text, which is a popular pretraining data source, to its social and geographic contexts. We create a new dataset of 10.3 million self-descriptions of website creators, and extract information about who they are and where they are from: their topical interests, social roles, and geographic affiliations. Then, we conduct the first study investigating how ten "quality" and English language identification (langID) filters affect webpages that vary along these social dimensions. Our experiments illuminate a range of implicit preferences in data curation: we show that some quality classifiers act like topical domain filters, and langID can overlook English content from some regions of the world. Overall, we hope that our work will encourage a new line of research on pretraining data curation practices and its social implications.
"One-size-fits-all"? Observations and Expectations of NLG Systems Across Identity-Related Language Features
Oct 23, 2023



Fairness-related assumptions about what constitutes appropriate NLG system behaviors range from invariance, where systems are expected to respond identically to social groups, to adaptation, where responses should instead vary across them. We design and conduct five case studies, in which we perturb different types of identity-related language features (names, roles, locations, dialect, and style) in NLG system inputs to illuminate tensions around invariance and adaptation. We outline people's expectations of system behaviors, and surface potential caveats of these two contrasting yet commonly-held assumptions. We find that motivations for adaptation include social norms, cultural differences, feature-specific information, and accommodation; motivations for invariance include perspectives that favor prescriptivism, view adaptation as unnecessary or too difficult for NLG systems to do appropriately, and are wary of false assumptions. Our findings highlight open challenges around defining what constitutes fair NLG system behavior.
Words as Gatekeepers: Measuring Discipline-specific Terms and Meanings in Scholarly Publications
Dec 19, 2022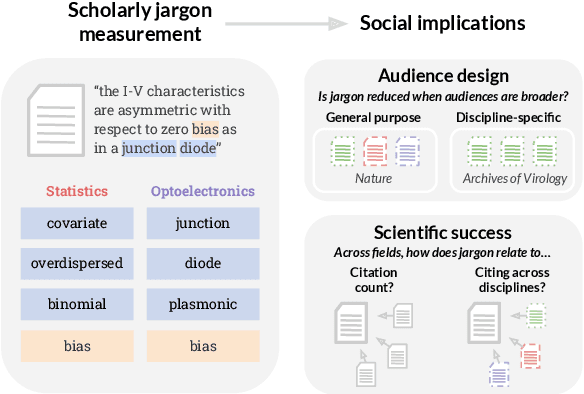
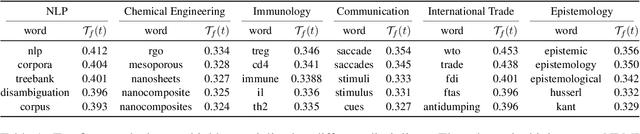


Scholarly text is often laden with jargon, or specialized language that divides disciplines. We extend past work that characterizes science at the level of word types, by using BERT-based word sense induction to find additional words that are widespread but overloaded with different uses across fields. We define scholarly jargon as discipline-specific word types and senses, and estimate its prevalence across hundreds of fields using interpretable, information-theoretic metrics. We demonstrate the utility of our approach for science of science and computational sociolinguistics by highlighting two key social implications. First, we measure audience design, and find that most fields reduce jargon when publishing in general-purpose journals, but some do so more than others. Second, though jargon has varying correlation with articles' citation rates within fields, it nearly always impedes interdisciplinary impact. Broadly, our measurements can inform ways in which language could be revised to serve as a bridge rather than a barrier in science.
Characterizing English Variation across Social Media Communities with BERT
Feb 12, 2021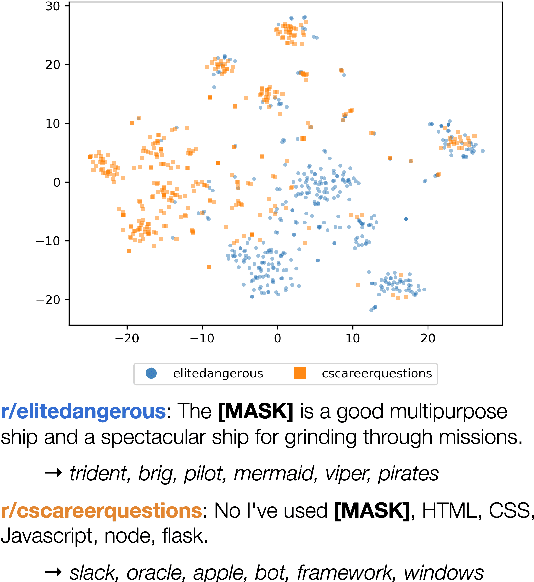
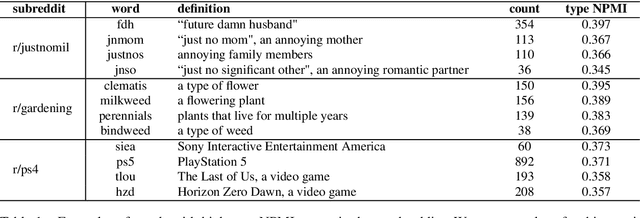
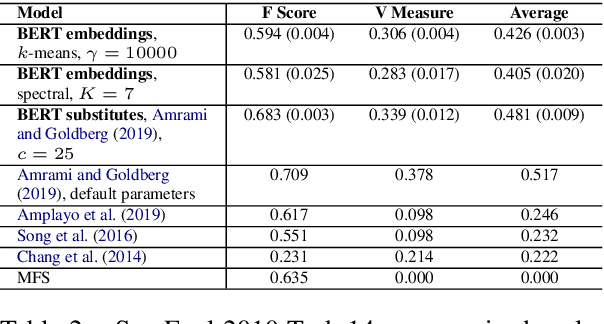
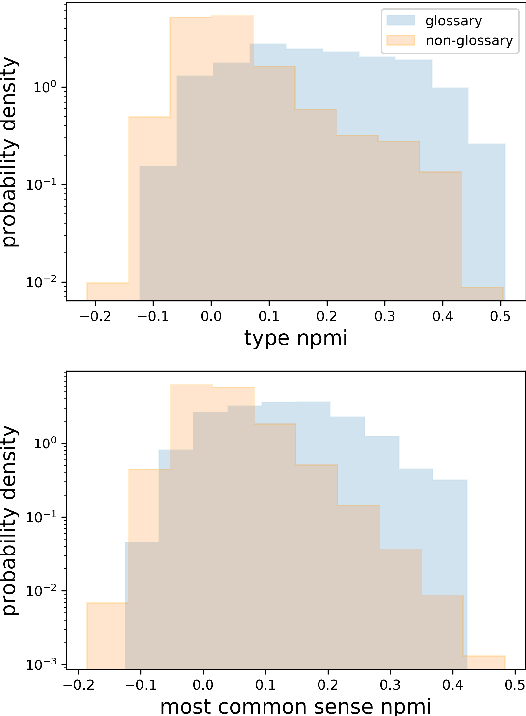
Much previous work characterizing language variation across Internet social groups has focused on the types of words used by these groups. We extend this type of study by employing BERT to characterize variation in the senses of words as well, analyzing two months of English comments in 474 Reddit communities. The specificity of different sense clusters to a community, combined with the specificity of a community's unique word types, is used to identify cases where a social group's language deviates from the norm. We validate our metrics using user-created glossaries and draw on sociolinguistic theories to connect language variation with trends in community behavior. We find that communities with highly distinctive language are medium-sized, and their loyal and highly engaged users interact in dense networks.