 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTell, Don't Show: Leveraging Language Models' Abstractive Retellings to Model Literary Themes
May 29, 2025Conventional bag-of-words approaches for topic modeling, like latent Dirichlet allocation (LDA), struggle with literary text. Literature challenges lexical methods because narrative language focuses on immersive sensory details instead of abstractive description or exposition: writers are advised to "show, don't tell." We propose Retell, a simple, accessible topic modeling approach for literature. Here, we prompt resource-efficient, generative language models (LMs) to tell what passages show, thereby translating narratives' surface forms into higher-level concepts and themes. By running LDA on LMs' retellings of passages, we can obtain more precise and informative topics than by running LDA alone or by directly asking LMs to list topics. To investigate the potential of our method for cultural analytics, we compare our method's outputs to expert-guided annotations in a case study on racial/cultural identity in high school English language arts books.
ER-REASON: A Benchmark Dataset for LLM-Based Clinical Reasoning in the Emergency Room
May 28, 2025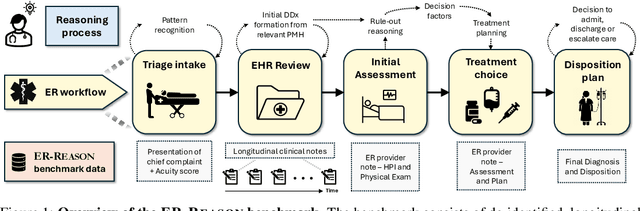



Large language models (LLMs) have been extensively evaluated on medical question answering tasks based on licensing exams. However, real-world evaluations often depend on costly human annotators, and existing benchmarks tend to focus on isolated tasks that rarely capture the clinical reasoning or full workflow underlying medical decisions. In this paper, we introduce ER-Reason, a benchmark designed to evaluate LLM-based clinical reasoning and decision-making in the emergency room (ER)--a high-stakes setting where clinicians make rapid, consequential decisions across diverse patient presentations and medical specialties under time pressure. ER-Reason includes data from 3,984 patients, encompassing 25,174 de-identified longitudinal clinical notes spanning discharge summaries, progress notes, history and physical exams, consults, echocardiography reports, imaging notes, and ER provider documentation. The benchmark includes evaluation tasks that span key stages of the ER workflow: triage intake, initial assessment, treatment selection, disposition planning, and final diagnosis--each structured to reflect core clinical reasoning processes such as differential diagnosis via rule-out reasoning. We also collected 72 full physician-authored rationales explaining reasoning processes that mimic the teaching process used in residency training, and are typically absent from ER documentation. Evaluations of state-of-the-art LLMs on ER-Reason reveal a gap between LLM-generated and clinician-authored clinical reasoning for ER decisions, highlighting the need for future research to bridge this divide.
Multimodal Conversation Structure Understanding
May 23, 2025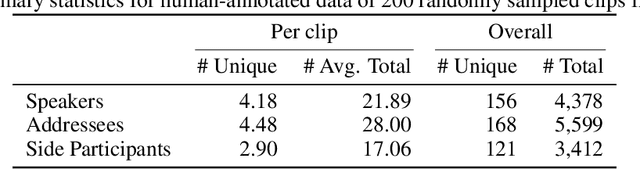
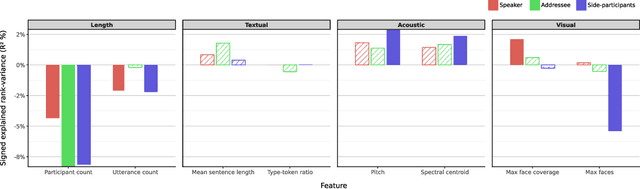
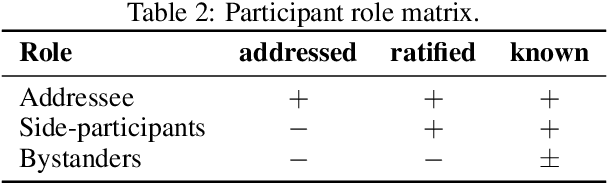
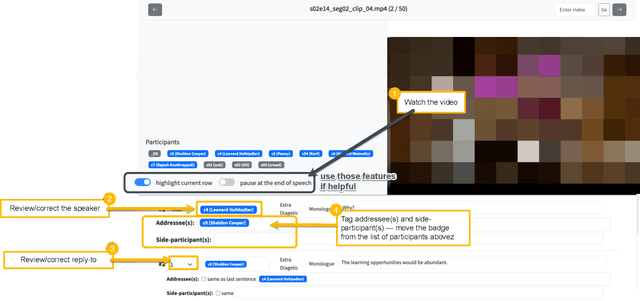
Conversations are usually structured by roles -- who is speaking, who's being addressed, and who's listening -- and unfold in threads that break with changes in speaker floor or topical focus. While large language models (LLMs) have shown incredible capabilities in dialogue and reasoning, their ability to understand fine-grained conversational structure, especially in multi-modal, multi-party settings, remains underexplored. To address this gap, we introduce a suite of tasks focused on conversational role attribution (speaker, addressees, side-participants) and conversation threading (utterance linking and clustering), drawing on conversation analysis and sociolinguistics. To support those tasks, we present a human annotated dataset of 4,398 annotations for speakers and reply-to relationship, 5,755 addressees, and 3,142 side-participants. We evaluate popular audio-visual LLMs and vision-language models on our dataset, and our experimental results suggest that multimodal conversational structure understanding remains challenging. The most performant audio-visual LLM outperforms all vision-language models across all metrics, especially in speaker and addressee recognition. However, its performance drops significantly when conversation participants are anonymized. The number of conversation participants in a clip is the strongest negative predictor of role-attribution performance, while acoustic clarity (measured by pitch and spectral centroid) and detected face coverage yield positive associations. We hope this work lays the groundwork for future evaluation and development of multimodal LLMs that can reason more effectively about conversation structure.
Culture is Not Trivia: Sociocultural Theory for Cultural NLP
Feb 17, 2025The field of cultural NLP has recently experienced rapid growth, driven by a pressing need to ensure that language technologies are effective and safe across a pluralistic user base. This work has largely progressed without a shared conception of culture, instead choosing to rely on a wide array of cultural proxies. However, this leads to a number of recurring limitations: coarse national boundaries fail to capture nuanced differences that lay within them, limited coverage restricts datasets to only a subset of usually highly-represented cultures, and a lack of dynamicity results in static cultural benchmarks that do not change as culture evolves. In this position paper, we argue that these methodological limitations are symptomatic of a theoretical gap. We draw on a well-developed theory of culture from sociocultural linguistics to fill this gap by 1) demonstrating in a case study how it can clarify methodological constraints and affordances, 2) offering theoretically-motivated paths forward to achieving cultural competence, and 3) arguing that localization is a more useful framing for the goals of much current work in cultural NLP.
BioAgents: Democratizing Bioinformatics Analysis with Multi-Agent Systems
Jan 10, 2025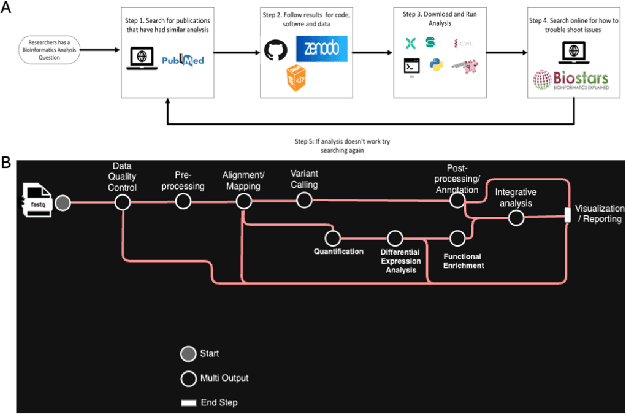
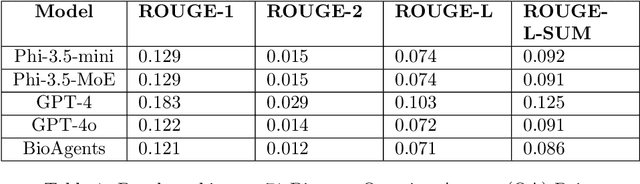
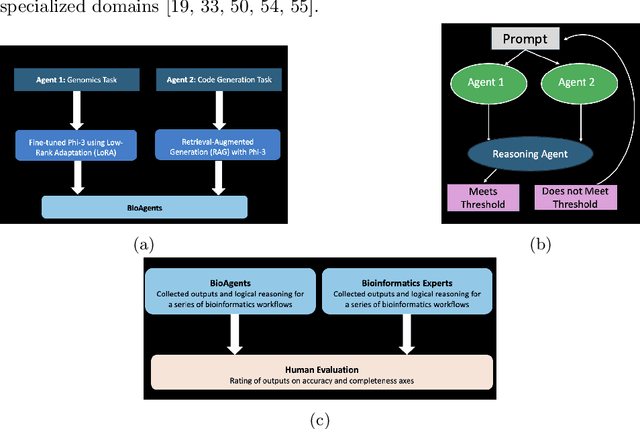
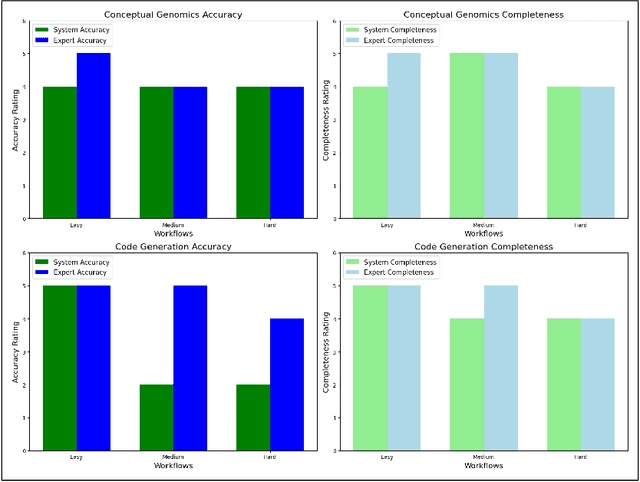
Creating end-to-end bioinformatics workflows requires diverse domain expertise, which poses challenges for both junior and senior researchers as it demands a deep understanding of both genomics concepts and computational techniques. While large language models (LLMs) provide some assistance, they often fall short in providing the nuanced guidance needed to execute complex bioinformatics tasks, and require expensive computing resources to achieve high performance. We thus propose a multi-agent system built on small language models, fine-tuned on bioinformatics data, and enhanced with retrieval augmented generation (RAG). Our system, BioAgents, enables local operation and personalization using proprietary data. We observe performance comparable to human experts on conceptual genomics tasks, and suggest next steps to enhance code generation capabilities.
Once More, With Feeling: Measuring Emotion of Acting Performances in Contemporary American Film
Nov 15, 2024



Narrative film is a composition of writing, cinematography, editing, and performance. While much computational work has focused on the writing or visual style in film, we conduct in this paper a computational exploration of acting performance. Applying speech emotion recognition models and a variationist sociolinguistic analytical framework to a corpus of popular, contemporary American film, we find narrative structure, diachronic shifts, and genre- and dialogue-based constraints located in spoken performances.
Subversive Characters and Stereotyping Readers: Characterizing Queer Relationalities with Dialogue-Based Relation Extraction
Oct 19, 2024



Television is often seen as a site for subcultural identification and subversive fantasy, including in queer cultures. How might we measure subversion, or the degree to which the depiction of social relationship between a dyad (e.g. two characters who are colleagues) deviates from its typical representation on TV? To explore this question, we introduce the task of stereotypic relationship extraction. Built on cognitive stylistics, linguistic anthropology, and dialogue relation extraction, in this paper, we attempt to model the cognitive process of stereotyping TV characters in dialogic interactions. Given a dyad, we want to predict: what social relationship do the speakers exhibit through their words? Subversion is then characterized by the discrepancy between the distribution of the model's predictions and the ground truth labels. To demonstrate the usefulness of this task and gesture at a methodological intervention, we enclose four case studies to characterize the representation of queer relationalities in the Big Bang Theory, Frasier, and Gilmore Girls, as we explore the suspicious and reparative modes of reading with our computational methods.
On Classification with Large Language Models in Cultural Analytics
Oct 15, 2024



In this work, we survey the way in which classification is used as a sensemaking practice in cultural analytics, and assess where large language models can fit into this landscape. We identify ten tasks supported by publicly available datasets on which we empirically assess the performance of LLMs compared to traditional supervised methods, and explore the ways in which LLMs can be employed for sensemaking goals beyond mere accuracy. We find that prompt-based LLMs are competitive with traditional supervised models for established tasks, but perform less well on de novo tasks. In addition, LLMs can assist sensemaking by acting as an intermediary input to formal theory testing.
AboutMe: Using Self-Descriptions in Webpages to Document the Effects of English Pretraining Data Filters
Jan 16, 2024Large language models' (LLMs) abilities are drawn from their pretraining data, and model development begins with data curation. However, decisions around what data is retained or removed during this initial stage is under-scrutinized. In our work, we ground web text, which is a popular pretraining data source, to its social and geographic contexts. We create a new dataset of 10.3 million self-descriptions of website creators, and extract information about who they are and where they are from: their topical interests, social roles, and geographic affiliations. Then, we conduct the first study investigating how ten "quality" and English language identification (langID) filters affect webpages that vary along these social dimensions. Our experiments illuminate a range of implicit preferences in data curation: we show that some quality classifiers act like topical domain filters, and langID can overlook English content from some regions of the world. Overall, we hope that our work will encourage a new line of research on pretraining data curation practices and its social implications.
Social Meme-ing: Measuring Linguistic Variation in Memes
Nov 15, 2023Much work in the space of NLP has used computational methods to explore sociolinguistic variation in text. In this paper, we argue that memes, as multimodal forms of language comprised of visual templates and text, also exhibit meaningful social variation. We construct a computational pipeline to cluster individual instances of memes into templates and semantic variables, taking advantage of their multimodal structure in doing so. We apply this method to a large collection of meme images from Reddit and make available the resulting \textsc{SemanticMemes} dataset of 3.8M images clustered by their semantic function. We use these clusters to analyze linguistic variation in memes, discovering not only that socially meaningful variation in meme usage exists between subreddits, but that patterns of meme innovation and acculturation within these communities align with previous findings on written language.