 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeER-REASON: A Benchmark Dataset for LLM-Based Clinical Reasoning in the Emergency Room
May 28, 2025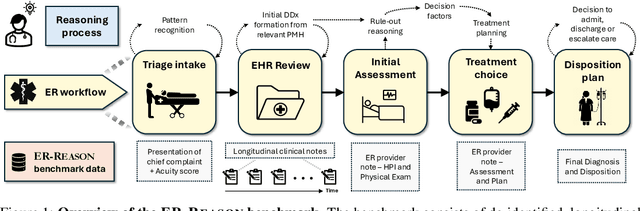



Large language models (LLMs) have been extensively evaluated on medical question answering tasks based on licensing exams. However, real-world evaluations often depend on costly human annotators, and existing benchmarks tend to focus on isolated tasks that rarely capture the clinical reasoning or full workflow underlying medical decisions. In this paper, we introduce ER-Reason, a benchmark designed to evaluate LLM-based clinical reasoning and decision-making in the emergency room (ER)--a high-stakes setting where clinicians make rapid, consequential decisions across diverse patient presentations and medical specialties under time pressure. ER-Reason includes data from 3,984 patients, encompassing 25,174 de-identified longitudinal clinical notes spanning discharge summaries, progress notes, history and physical exams, consults, echocardiography reports, imaging notes, and ER provider documentation. The benchmark includes evaluation tasks that span key stages of the ER workflow: triage intake, initial assessment, treatment selection, disposition planning, and final diagnosis--each structured to reflect core clinical reasoning processes such as differential diagnosis via rule-out reasoning. We also collected 72 full physician-authored rationales explaining reasoning processes that mimic the teaching process used in residency training, and are typically absent from ER documentation. Evaluations of state-of-the-art LLMs on ER-Reason reveal a gap between LLM-generated and clinician-authored clinical reasoning for ER decisions, highlighting the need for future research to bridge this divide.
Expertise Is What We Want
Feb 27, 2025



Clinical decision-making depends on expert reasoning, which is guided by standardized, evidence-based guidelines. However, translating these guidelines into automated clinical decision support systems risks inaccuracy and importantly, loss of nuance. We share an application architecture, the Large Language Expert (LLE), that combines the flexibility and power of Large Language Models (LLMs) with the interpretability, explainability, and reliability of Expert Systems. LLMs help address key challenges of Expert Systems, such as integrating and codifying knowledge, and data normalization. Conversely, an Expert System-like approach helps overcome challenges with LLMs, including hallucinations, atomic and inexpensive updates, and testability. To highlight the power of the Large Language Expert (LLE) system, we built an LLE to assist with the workup of patients newly diagnosed with cancer. Timely initiation of cancer treatment is critical for optimal patient outcomes. However, increasing complexity in diagnostic recommendations has made it difficult for primary care physicians to ensure their patients have completed the necessary workup before their first visit with an oncologist. As with many real-world clinical tasks, these workups require the analysis of unstructured health records and the application of nuanced clinical decision logic. In this study, we describe the design & evaluation of an LLE system built to rapidly identify and suggest the correct diagnostic workup. The system demonstrated a high degree of clinical-level accuracy (>95%) and effectively addressed gaps identified in real-world data from breast and colon cancer patients at a large academic center.
Updating the Minimum Information about CLinical Artificial Intelligence (MI-CLAIM) checklist for generative modeling research
Mar 05, 2024Recent advances in generative models, including large language models (LLMs), vision language models (VLMs), and diffusion models, have accelerated the field of natural language and image processing in medicine and marked a significant paradigm shift in how biomedical models can be developed and deployed. While these models are highly adaptable to new tasks, scaling and evaluating their usage presents new challenges not addressed in previous frameworks. In particular, the ability of these models to produce useful outputs with little to no specialized training data ("zero-" or "few-shot" approaches), as well as the open-ended nature of their outputs, necessitate the development of updated guidelines in using and evaluating these models. In response to gaps in standards and best practices for the development of clinical AI tools identified by US Executive Order 141103 and several emerging national networks for clinical AI evaluation, we begin to formalize some of these guidelines by building on the "Minimum information about clinical artificial intelligence modeling" (MI-CLAIM) checklist. The MI-CLAIM checklist, originally developed in 2020, provided a set of six steps with guidelines on the minimum information necessary to encourage transparent, reproducible research for artificial intelligence (AI) in medicine. Here, we propose modifications to the original checklist that highlight differences in training, evaluation, interpretability, and reproducibility of generative models compared to traditional AI models for clinical research. This updated checklist also seeks to clarify cohort selection reporting and adds additional items on alignment with ethical standards.
Identifying Reasons for Contraceptive Switching from Real-World Data Using Large Language Models
Feb 06, 2024Prescription contraceptives play a critical role in supporting women's reproductive health. With nearly 50 million women in the United States using contraceptives, understanding the factors that drive contraceptives selection and switching is of significant interest. However, many factors related to medication switching are often only captured in unstructured clinical notes and can be difficult to extract. Here, we evaluate the zero-shot abilities of a recently developed large language model, GPT-4 (via HIPAA-compliant Microsoft Azure API), to identify reasons for switching between classes of contraceptives from the UCSF Information Commons clinical notes dataset. We demonstrate that GPT-4 can accurately extract reasons for contraceptive switching, outperforming baseline BERT-based models with microF1 scores of 0.849 and 0.881 for contraceptive start and stop extraction, respectively. Human evaluation of GPT-4-extracted reasons for switching showed 91.4% accuracy, with minimal hallucinations. Using extracted reasons, we identified patient preference, adverse events, and insurance as key reasons for switching using unsupervised topic modeling approaches. Notably, we also showed using our approach that "weight gain/mood change" and "insurance coverage" are disproportionately found as reasons for contraceptive switching in specific demographic populations. Our code and supplemental data are available at https://github.com/BMiao10/contraceptive-switching.
A comparative study of zero-shot inference with large language models and supervised modeling in breast cancer pathology classification
Jan 25, 2024Although supervised machine learning is popular for information extraction from clinical notes, creating large annotated datasets requires extensive domain expertise and is time-consuming. Meanwhile, large language models (LLMs) have demonstrated promising transfer learning capability. In this study, we explored whether recent LLMs can reduce the need for large-scale data annotations. We curated a manually-labeled dataset of 769 breast cancer pathology reports, labeled with 13 categories, to compare zero-shot classification capability of the GPT-4 model and the GPT-3.5 model with supervised classification performance of three model architectures: random forests classifier, long short-term memory networks with attention (LSTM-Att), and the UCSF-BERT model. Across all 13 tasks, the GPT-4 model performed either significantly better than or as well as the best supervised model, the LSTM-Att model (average macro F1 score of 0.83 vs. 0.75). On tasks with high imbalance between labels, the differences were more prominent. Frequent sources of GPT-4 errors included inferences from multiple samples and complex task design. On complex tasks where large annotated datasets cannot be easily collected, LLMs can reduce the burden of large-scale data labeling. However, if the use of LLMs is prohibitive, the use of simpler supervised models with large annotated datasets can provide comparable results. LLMs demonstrated the potential to speed up the execution of clinical NLP studies by reducing the need for curating large annotated datasets. This may result in an increase in the utilization of NLP-based variables and outcomes in observational clinical studies.
Extracting detailed oncologic history and treatment plan from medical oncology notes with large language models
Aug 07, 2023



Both medical care and observational studies in oncology require a thorough understanding of a patient's disease progression and treatment history, often elaborately documented in clinical notes. Despite their vital role, no current oncology information representation and annotation schema fully encapsulates the diversity of information recorded within these notes. Although large language models (LLMs) have recently exhibited impressive performance on various medical natural language processing tasks, due to the current lack of comprehensively annotated oncology datasets, an extensive evaluation of LLMs in extracting and reasoning with the complex rhetoric in oncology notes remains understudied. We developed a detailed schema for annotating textual oncology information, encompassing patient characteristics, tumor characteristics, tests, treatments, and temporality. Using a corpus of 10 de-identified breast cancer progress notes at University of California, San Francisco, we applied this schema to assess the abilities of three recently-released LLMs (GPT-4, GPT-3.5-turbo, and FLAN-UL2) to perform zero-shot extraction of detailed oncological history from two narrative sections of clinical progress notes. Our team annotated 2750 entities, 2874 modifiers, and 1623 relationships. The GPT-4 model exhibited overall best performance, with an average BLEU score of 0.69, an average ROUGE score of 0.72, and an average accuracy of 67% on complex tasks (expert manual evaluation). Notably, it was proficient in tumor characteristic and medication extraction, and demonstrated superior performance in inferring symptoms due to cancer and considerations of future medications. The analysis demonstrates that GPT-4 is potentially already usable to extract important facts from cancer progress notes needed for clinical research, complex population management, and documenting quality patient care.
Revealing the impact of social circumstances on the selection of cancer therapy through natural language processing of social work notes
Jun 16, 2023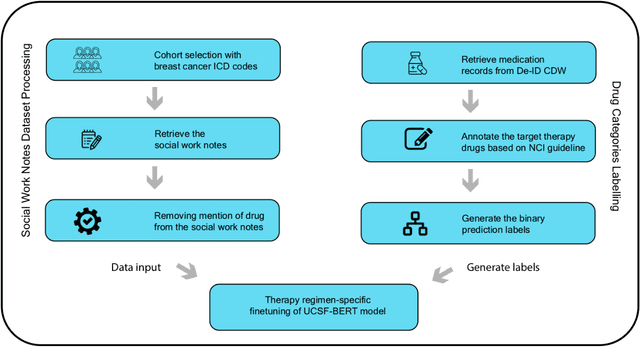
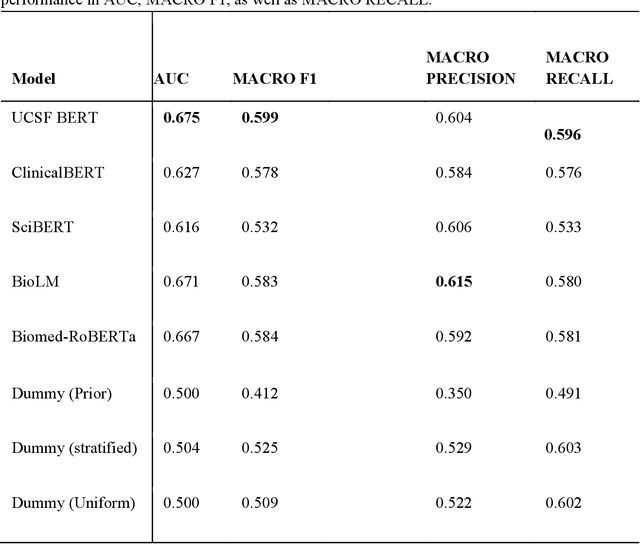
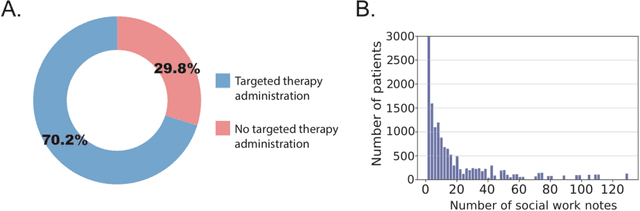
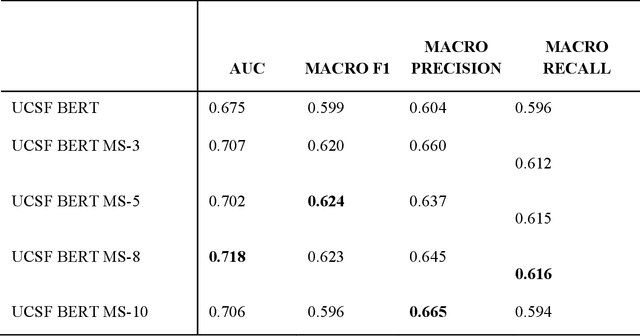
We aimed to investigate the impact of social circumstances on cancer therapy selection using natural language processing to derive insights from social worker documentation. We developed and employed a Bidirectional Encoder Representations from Transformers (BERT) based approach, using a hierarchical multi-step BERT model (BERT-MS) to predict the prescription of targeted cancer therapy to patients based solely on documentation by clinical social workers. Our corpus included free-text clinical social work notes, combined with medication prescription information, for all patients treated for breast cancer. We conducted a feature importance analysis to pinpoint the specific social circumstances that impact cancer therapy selection. Using only social work notes, we consistently predicted the administration of targeted therapies, suggesting systematic differences in treatment selection exist due to non-clinical factors. The UCSF-BERT model, pretrained on clinical text at UCSF, outperformed other publicly available language models with an AUROC of 0.675 and a Macro F1 score of 0.599. The UCSF BERT-MS model, capable of leveraging multiple pieces of notes, surpassed the UCSF-BERT model in both AUROC and Macro-F1. Our feature importance analysis identified several clinically intuitive social determinants of health (SDOH) that potentially contribute to disparities in treatment. Our findings indicate that significant disparities exist among breast cancer patients receiving different types of therapies based on social determinants of health. Social work reports play a crucial role in understanding these disparities in clinical decision-making.
Topic Modeling on Clinical Social Work Notes for Exploring Social Determinants of Health Factors
Dec 02, 2022Most research studying social determinants of health (SDoH) has focused on physician notes or structured elements of the electronic medical record (EMR). We hypothesize that clinical notes from social workers, whose role is to ameliorate social and economic factors, might provide a richer source of data on SDoH. We sought to perform topic modeling to identify robust topics of discussion within a large cohort of social work notes. We retrieved a diverse, deidentified corpus of 0.95 million clinical social work notes from 181,644 patients at the University of California, San Francisco. We used word frequency analysis and Latent Dirichlet Allocation (LDA) topic modeling analysis to characterize this corpus and identify potential topics of discussion. Word frequency analysis identified both medical and non-medical terms associated with specific ICD10 chapters. The LDA topic modeling analysis extracted 11 topics related to social determinants of health risk factors including financial status, abuse history, social support, risk of death, and mental health. In addition, the topic modeling approach captured the variation between different types of social work notes and across patients with different types of diseases or conditions. We demonstrated that social work notes contain rich, unique, and otherwise unobtainable information on an individual's SDoH.