 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNext-Scale Autoregressive Models for Text-to-Motion Generation
Apr 04, 2026Autoregressive (AR) models offer stable and efficient training, but standard next-token prediction is not well aligned with the temporal structure required for text-conditioned motion generation. We introduce MoScale, a next-scale AR framework that generates motion hierarchically from coarse to fine temporal resolutions. By providing global semantics at the coarsest scale and refining them progressively, MoScale establishes a causal hierarchy better suited for long-range motion structure. To improve robustness under limited text-motion data, we further incorporate cross-scale hierarchical refinement for improving per-scale initial predictions and in-scale temporal refinement for selective bidirectional re-prediction. MoScale achieves SOTA text-to-motion performance with high training efficiency, scales effectively with model size, and generalizes zero-shot to diverse motion generation and editing tasks.
TwinPurify: Purifying gene expression data to reveal tumor-intrinsic transcriptional programs via self-supervised learning
Jan 27, 2026Advances in single-cell and spatial transcriptomic technologies have transformed tumor ecosystem profiling at cellular resolution. However, large scale studies on patient cohorts continue to rely on bulk transcriptomic data, where variation in tumor purity obscures tumor-intrinsic transcriptional signals and constrains downstream discovery. Many deconvolution methods report strong performance on synthetic bulk mixtures but fail to generalize to real patient cohorts because of unmodeled biological and technical variation. Here, we introduce TwinPurify, a representation learning framework that adapts the Barlow Twins self-supervised objective, representing a fundamental departure from the deconvolution paradigm. Rather than resolving the bulk mixture into discrete cell-type fractions, TwinPurify instead learns continuous, high-dimensional tumor embeddings by leveraging adjacent-normal profiles within the same cohort as "background" guidance, enabling the disentanglement of tumor-specific signals without relying on any external reference. Benchmarked against multiple large cancer cohorts across RNA-seq and microarray platforms, TwinPurify outperforms conventional representation learning baselines like auto-encoders in recovering tumor-intrinsic and immune signals. The purified embeddings improve molecular subtype and grade classification, enhance survival model concordance, and uncover biologically meaningful pathway activities compared to raw bulk profiles. By providing a transferable framework for decontaminating bulk transcriptomics, TwinPurify extends the utility of existing clinical datasets for molecular discovery.
LaCoGSEA: Unsupervised deep learning for pathway analysis via latent correlation
Jan 27, 2026Motivation: Pathway enrichment analysis is widely used to interpret gene expression data. Standard approaches, such as GSEA, rely on predefined phenotypic labels and pairwise comparisons, which limits their applicability in unsupervised settings. Existing unsupervised extensions, including single-sample methods, provide pathway-level summaries but primarily capture linear relationships and do not explicitly model gene-pathway associations. More recently, deep learning models have been explored to capture non-linear transcriptomic structure. However, their interpretation has typically relied on generic explainable AI (XAI) techniques designed for feature-level attribution. As these methods are not designed for pathway-level interpretation in unsupervised transcriptomic analyses, their effectiveness in this setting remains limited. Results: To bridge this gap, we introduce LaCoGSEA (Latent Correlation GSEA), an unsupervised framework that integrates deep representation learning with robust pathway statistics. LaCoGSEA employs an autoencoder to capture non-linear manifolds and proposes a global gene-latent correlation metric as a proxy for differential expression, generating dense gene rankings without prior labels. We demonstrate that LaCoGSEA offers three key advantages: (i) it achieves improved clustering performance in distinguishing cancer subtypes compared to existing unsupervised baselines; (ii) it recovers a broader range of biologically meaningful pathways at higher ranks compared with linear dimensionality reduction and gradient-based XAI methods; and (iii) it maintains high robustness and consistency across varying experimental protocols and dataset sizes. Overall, LaCoGSEA provides state-of-the-art performance in unsupervised pathway enrichment analysis. Availability and implementation: https://github.com/willyzzz/LaCoGSEA
On the Performance Analysis of Momentum Method: A Frequency Domain Perspective
Nov 29, 2024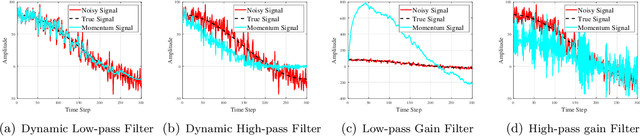

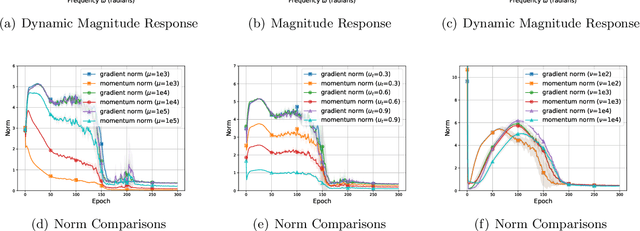

Momentum-based optimizers are widely adopted for training neural networks. However, the optimal selection of momentum coefficients remains elusive. This uncertainty impedes a clear understanding of the role of momentum in stochastic gradient methods. In this paper, we present a frequency domain analysis framework that interprets the momentum method as a time-variant filter for gradients, where adjustments to momentum coefficients modify the filter characteristics. Our experiments support this perspective and provide a deeper understanding of the mechanism involved. Moreover, our analysis reveals the following significant findings: high-frequency gradient components are undesired in the late stages of training; preserving the original gradient in the early stages, and gradually amplifying low-frequency gradient components during training both enhance generalization performance. Based on these insights, we propose Frequency Stochastic Gradient Descent with Momentum (FSGDM), a heuristic optimizer that dynamically adjusts the momentum filtering characteristic with an empirically effective dynamic magnitude response. Experimental results demonstrate the superiority of FSGDM over conventional momentum optimizers.
Acoustic Volume Rendering for Neural Impulse Response Fields
Nov 09, 2024



Realistic audio synthesis that captures accurate acoustic phenomena is essential for creating immersive experiences in virtual and augmented reality. Synthesizing the sound received at any position relies on the estimation of impulse response (IR), which characterizes how sound propagates in one scene along different paths before arriving at the listener's position. In this paper, we present Acoustic Volume Rendering (AVR), a novel approach that adapts volume rendering techniques to model acoustic impulse responses. While volume rendering has been successful in modeling radiance fields for images and neural scene representations, IRs present unique challenges as time-series signals. To address these challenges, we introduce frequency-domain volume rendering and use spherical integration to fit the IR measurements. Our method constructs an impulse response field that inherently encodes wave propagation principles and achieves state-of-the-art performance in synthesizing impulse responses for novel poses. Experiments show that AVR surpasses current leading methods by a substantial margin. Additionally, we develop an acoustic simulation platform, AcoustiX, which provides more accurate and realistic IR simulations than existing simulators. Code for AVR and AcoustiX are available at https://zitonglan.github.io/avr.
A comparative study of zero-shot inference with large language models and supervised modeling in breast cancer pathology classification
Jan 25, 2024Although supervised machine learning is popular for information extraction from clinical notes, creating large annotated datasets requires extensive domain expertise and is time-consuming. Meanwhile, large language models (LLMs) have demonstrated promising transfer learning capability. In this study, we explored whether recent LLMs can reduce the need for large-scale data annotations. We curated a manually-labeled dataset of 769 breast cancer pathology reports, labeled with 13 categories, to compare zero-shot classification capability of the GPT-4 model and the GPT-3.5 model with supervised classification performance of three model architectures: random forests classifier, long short-term memory networks with attention (LSTM-Att), and the UCSF-BERT model. Across all 13 tasks, the GPT-4 model performed either significantly better than or as well as the best supervised model, the LSTM-Att model (average macro F1 score of 0.83 vs. 0.75). On tasks with high imbalance between labels, the differences were more prominent. Frequent sources of GPT-4 errors included inferences from multiple samples and complex task design. On complex tasks where large annotated datasets cannot be easily collected, LLMs can reduce the burden of large-scale data labeling. However, if the use of LLMs is prohibitive, the use of simpler supervised models with large annotated datasets can provide comparable results. LLMs demonstrated the potential to speed up the execution of clinical NLP studies by reducing the need for curating large annotated datasets. This may result in an increase in the utilization of NLP-based variables and outcomes in observational clinical studies.
Fedward: Flexible Federated Backdoor Defense Framework with Non-IID Data
Jul 01, 2023
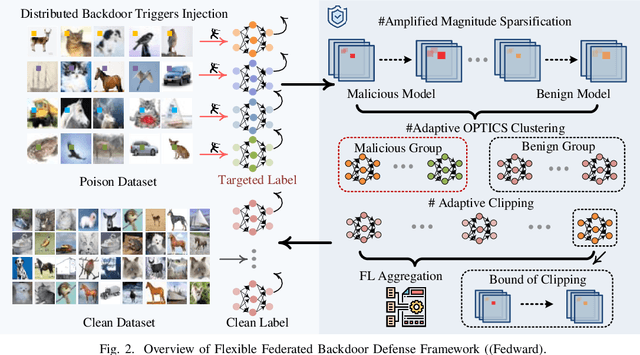


Federated learning (FL) enables multiple clients to collaboratively train deep learning models while considering sensitive local datasets' privacy. However, adversaries can manipulate datasets and upload models by injecting triggers for federated backdoor attacks (FBA). Existing defense strategies against FBA consider specific and limited attacker models, and a sufficient amount of noise to be injected only mitigates rather than eliminates FBA. To address these deficiencies, we introduce a Flexible Federated Backdoor Defense Framework (Fedward) to ensure the elimination of adversarial backdoors. We decompose FBA into various attacks, and design amplified magnitude sparsification (AmGrad) and adaptive OPTICS clustering (AutoOPTICS) to address each attack. Meanwhile, Fedward uses the adaptive clipping method by regarding the number of samples in the benign group as constraints on the boundary. This ensures that Fedward can maintain the performance for the Non-IID scenario. We conduct experimental evaluations over three benchmark datasets and thoroughly compare them to state-of-the-art studies. The results demonstrate the promising defense performance from Fedward, moderately improved by 33% $\sim$ 75 in clustering defense methods, and 96.98%, 90.74%, and 89.8% for Non-IID to the utmost extent for the average FBA success rate over MNIST, FMNIST, and CIFAR10, respectively.