 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocal Differential Privacy is Not Enough: A Sample Reconstruction Attack against Federated Learning with Local Differential Privacy
Feb 12, 2025
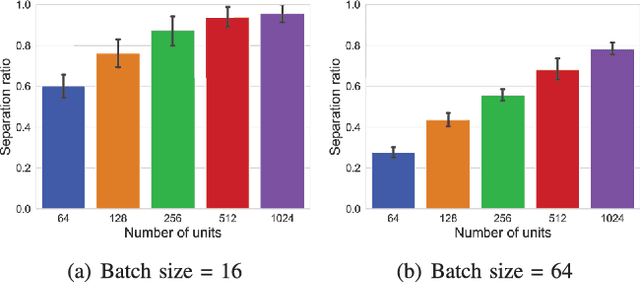
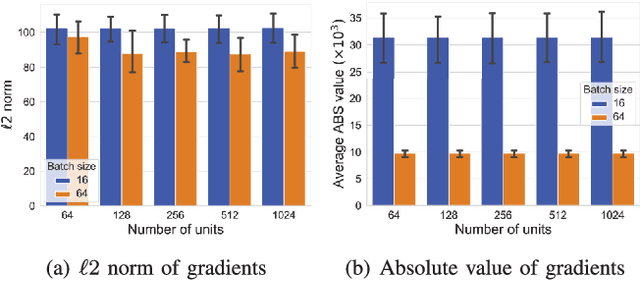
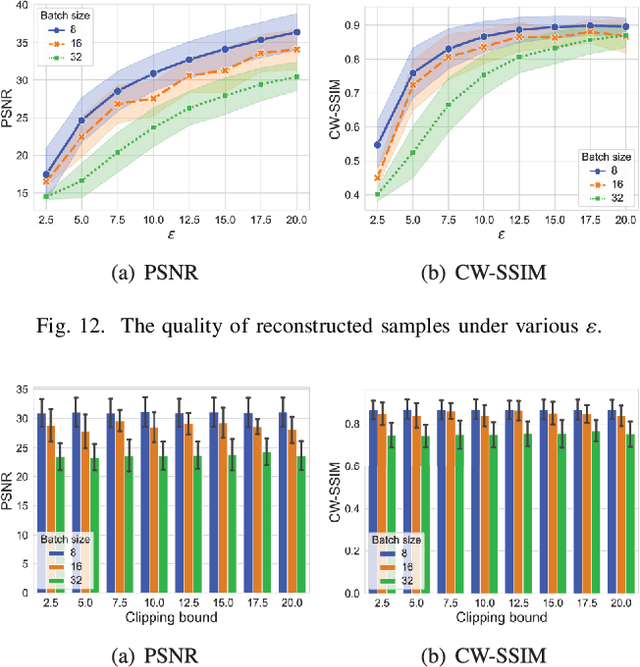
Reconstruction attacks against federated learning (FL) aim to reconstruct users' samples through users' uploaded gradients. Local differential privacy (LDP) is regarded as an effective defense against various attacks, including sample reconstruction in FL, where gradients are clipped and perturbed. Existing attacks are ineffective in FL with LDP since clipped and perturbed gradients obliterate most sample information for reconstruction. Besides, existing attacks embed additional sample information into gradients to improve the attack effect and cause gradient expansion, leading to a more severe gradient clipping in FL with LDP. In this paper, we propose a sample reconstruction attack against LDP-based FL with any target models to reconstruct victims' sensitive samples to illustrate that FL with LDP is not flawless. Considering gradient expansion in reconstruction attacks and noise in LDP, the core of the proposed attack is gradient compression and reconstructed sample denoising. For gradient compression, an inference structure based on sample characteristics is presented to reduce redundant gradients against LDP. For reconstructed sample denoising, we artificially introduce zero gradients to observe noise distribution and scale confidence interval to filter the noise. Theoretical proof guarantees the effectiveness of the proposed attack. Evaluations show that the proposed attack is the only attack that reconstructs victims' training samples in LDP-based FL and has little impact on the target model's accuracy. We conclude that LDP-based FL needs further improvements to defend against sample reconstruction attacks effectively.
SemiAdv: Query-Efficient Black-Box Adversarial Attack with Unlabeled Images
Jul 13, 2024Adversarial attack has garnered considerable attention due to its profound implications for the secure deployment of robots in sensitive security scenarios. To potentially push for advances in the field, this paper studies the adversarial attack in the black-box setting and proposes an unlabeled data-driven adversarial attack method, called SemiAdv. Specifically, SemiAdv achieves the following breakthroughs compared with previous works. First, by introducing the semi-supervised learning technique into the adversarial attack, SemiAdv substantially decreases the number of queries required for generating adversarial samples. On average, SemiAdv only needs to query a few hundred times to launch an effective attack with more than 90% success rate. Second, many existing black-box adversarial attacks require massive labeled data to mitigate the difference between the local substitute model and the remote target model for a good attack performance. While SemiAdv relaxes this limitation and is capable of utilizing unlabeled raw data to launch an effective attack. Finally, our experiments show that SemiAdv saves up to 12x query accesses for generating adversarial samples while maintaining a competitive attack success rate compared with state-of-the-art attacks.
MEAT: Median-Ensemble Adversarial Training for Improving Robustness and Generalization
Jun 20, 2024Self-ensemble adversarial training methods improve model robustness by ensembling models at different training epochs, such as model weight averaging (WA). However, previous research has shown that self-ensemble defense methods in adversarial training (AT) still suffer from robust overfitting, which severely affects the generalization performance. Empirically, in the late phases of training, the AT becomes more overfitting to the extent that the individuals for weight averaging also suffer from overfitting and produce anomalous weight values, which causes the self-ensemble model to continue to undergo robust overfitting due to the failure in removing the weight anomalies. To solve this problem, we aim to tackle the influence of outliers in the weight space in this work and propose an easy-to-operate and effective Median-Ensemble Adversarial Training (MEAT) method to solve the robust overfitting phenomenon existing in self-ensemble defense from the source by searching for the median of the historical model weights. Experimental results show that MEAT achieves the best robustness against the powerful AutoAttack and can effectively allievate the robust overfitting. We further demonstrate that most defense methods can improve robust generalization and robustness by combining with MEAT.
Towards Trustworthy Unsupervised Domain Adaptation: A Representation Learning Perspective for Enhancing Robustness, Discrimination, and Generalization
Jun 19, 2024Robust Unsupervised Domain Adaptation (RoUDA) aims to achieve not only clean but also robust cross-domain knowledge transfer from a labeled source domain to an unlabeled target domain. A number of works have been conducted by directly injecting adversarial training (AT) in UDA based on the self-training pipeline and then aiming to generate better adversarial examples (AEs) for AT. Despite the remarkable progress, these methods only focus on finding stronger AEs but neglect how to better learn from these AEs, thus leading to unsatisfied results. In this paper, we investigate robust UDA from a representation learning perspective and design a novel algorithm by utilizing the mutual information theory, dubbed MIRoUDA. Specifically, through mutual information optimization, MIRoUDA is designed to achieve three characteristics that are highly expected in robust UDA, i.e., robustness, discrimination, and generalization. We then propose a dual-model framework accordingly for robust UDA learning. Extensive experiments on various benchmarks verify the effectiveness of the proposed MIRoUDA, in which our method surpasses the state-of-the-arts by a large margin.
MFA-Net: Multi-Scale feature fusion attention network for liver tumor segmentation
May 07, 2024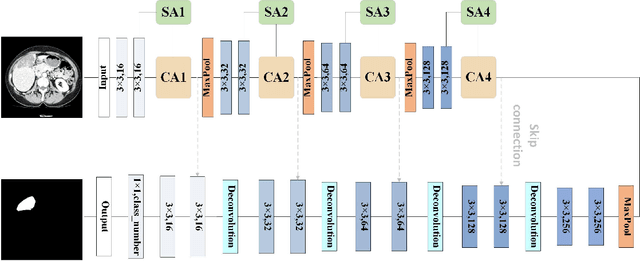

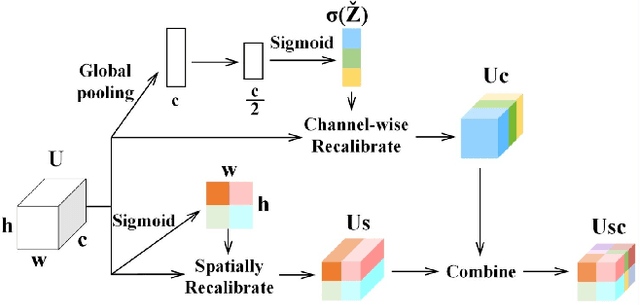

Segmentation of organs of interest in medical CT images is beneficial for diagnosis of diseases. Though recent methods based on Fully Convolutional Neural Networks (F-CNNs) have shown success in many segmentation tasks, fusing features from images with different scales is still a challenge: (1) Due to the lack of spatial awareness, F-CNNs share the same weights at different spatial locations. (2) F-CNNs can only obtain surrounding information through local receptive fields. To address the above challenge, we propose a new segmentation framework based on attention mechanisms, named MFA-Net (Multi-Scale Feature Fusion Attention Network). The proposed framework can learn more meaningful feature maps among multiple scales and result in more accurate automatic segmentation. We compare our proposed MFA-Net with SOTA methods on two 2D liver CT datasets. The experimental results show that our MFA-Net produces more precise segmentation on images with different scales.
An Adaptive Model Ensemble Adversarial Attack for Boosting Adversarial Transferability
Aug 05, 2023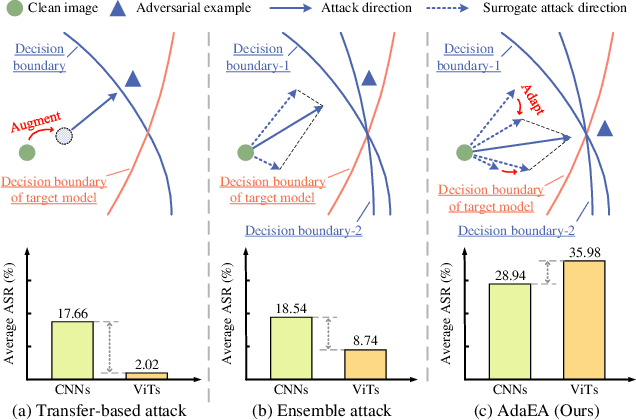
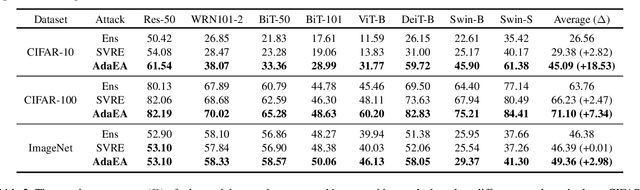
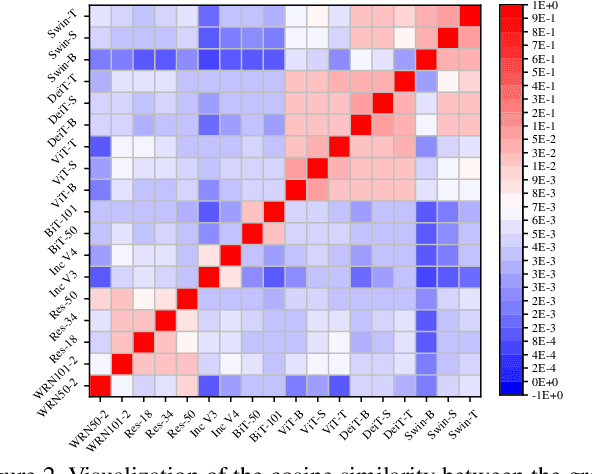
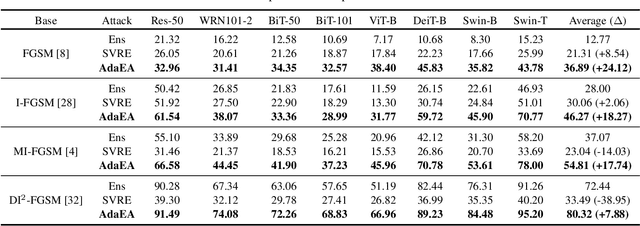
While the transferability property of adversarial examples allows the adversary to perform black-box attacks (i.e., the attacker has no knowledge about the target model), the transfer-based adversarial attacks have gained great attention. Previous works mostly study gradient variation or image transformations to amplify the distortion on critical parts of inputs. These methods can work on transferring across models with limited differences, i.e., from CNNs to CNNs, but always fail in transferring across models with wide differences, such as from CNNs to ViTs. Alternatively, model ensemble adversarial attacks are proposed to fuse outputs from surrogate models with diverse architectures to get an ensemble loss, making the generated adversarial example more likely to transfer to other models as it can fool multiple models concurrently. However, existing ensemble attacks simply fuse the outputs of the surrogate models evenly, thus are not efficacious to capture and amplify the intrinsic transfer information of adversarial examples. In this paper, we propose an adaptive ensemble attack, dubbed AdaEA, to adaptively control the fusion of the outputs from each model, via monitoring the discrepancy ratio of their contributions towards the adversarial objective. Furthermore, an extra disparity-reduced filter is introduced to further synchronize the update direction. As a result, we achieve considerable improvement over the existing ensemble attacks on various datasets, and the proposed AdaEA can also boost existing transfer-based attacks, which further demonstrates its efficacy and versatility.
Fedward: Flexible Federated Backdoor Defense Framework with Non-IID Data
Jul 01, 2023Federated learning (FL) enables multiple clients to collaboratively train deep learning models while considering sensitive local datasets' privacy. However, adversaries can manipulate datasets and upload models by injecting triggers for federated backdoor attacks (FBA). Existing defense strategies against FBA consider specific and limited attacker models, and a sufficient amount of noise to be injected only mitigates rather than eliminates FBA. To address these deficiencies, we introduce a Flexible Federated Backdoor Defense Framework (Fedward) to ensure the elimination of adversarial backdoors. We decompose FBA into various attacks, and design amplified magnitude sparsification (AmGrad) and adaptive OPTICS clustering (AutoOPTICS) to address each attack. Meanwhile, Fedward uses the adaptive clipping method by regarding the number of samples in the benign group as constraints on the boundary. This ensures that Fedward can maintain the performance for the Non-IID scenario. We conduct experimental evaluations over three benchmark datasets and thoroughly compare them to state-of-the-art studies. The results demonstrate the promising defense performance from Fedward, moderately improved by 33% $\sim$ 75 in clustering defense methods, and 96.98%, 90.74%, and 89.8% for Non-IID to the utmost extent for the average FBA success rate over MNIST, FMNIST, and CIFAR10, respectively.
When Evolutionary Computation Meets Privacy
Mar 22, 2023



Recently, evolutionary computation (EC) has been promoted by machine learning, distributed computing, and big data technologies, resulting in new research directions of EC like distributed EC and surrogate-assisted EC. These advances have significantly improved the performance and the application scope of EC, but also trigger privacy leakages, such as the leakage of optimal results and surrogate model. Accordingly, evolutionary computation combined with privacy protection is becoming an emerging topic. However, privacy concerns in evolutionary computation lack a systematic exploration, especially for the object, motivation, position, and method of privacy protection. To this end, in this paper, we discuss three typical optimization paradigms (i.e., \textit{centralized optimization, distributed optimization, and data-driven optimization}) to characterize optimization modes of evolutionary computation and propose BOOM to sort out privacy concerns in evolutionary computation. Specifically, the centralized optimization paradigm allows clients to outsource optimization problems to the centralized server and obtain optimization solutions from the server. While the distributed optimization paradigm exploits the storage and computational power of distributed devices to solve optimization problems. Also, the data-driven optimization paradigm utilizes data collected in history to tackle optimization problems lacking explicit objective functions. Particularly, this paper adopts BOOM to characterize the object and motivation of privacy protection in three typical optimization paradigms and discusses potential privacy-preserving technologies balancing optimization performance and privacy guarantees in three typical optimization paradigms. Furthermore, this paper attempts to foresee some new research directions of privacy-preserving evolutionary computation.
SRoUDA: Meta Self-training for Robust Unsupervised Domain Adaptation
Dec 12, 2022As acquiring manual labels on data could be costly, unsupervised domain adaptation (UDA), which transfers knowledge learned from a rich-label dataset to the unlabeled target dataset, is gaining increasing popularity. While extensive studies have been devoted to improving the model accuracy on target domain, an important issue of model robustness is neglected. To make things worse, conventional adversarial training (AT) methods for improving model robustness are inapplicable under UDA scenario since they train models on adversarial examples that are generated by supervised loss function. In this paper, we present a new meta self-training pipeline, named SRoUDA, for improving adversarial robustness of UDA models. Based on self-training paradigm, SRoUDA starts with pre-training a source model by applying UDA baseline on source labeled data and taraget unlabeled data with a developed random masked augmentation (RMA), and then alternates between adversarial target model training on pseudo-labeled target data and finetuning source model by a meta step. While self-training allows the direct incorporation of AT in UDA, the meta step in SRoUDA further helps in mitigating error propagation from noisy pseudo labels. Extensive experiments on various benchmark datasets demonstrate the state-of-the-art performance of SRoUDA where it achieves significant model robustness improvement without harming clean accuracy. Code is available at https://github.com/Vision.
Refiner: Data Refining against Gradient Leakage Attacks in Federated Learning
Dec 05, 2022Federated Learning (FL) is pervasive in privacy-focused IoT environments since it enables avoiding privacy leakage by training models with gradients instead of data. Recent works show the uploaded gradients can be employed to reconstruct data, i.e., gradient leakage attacks, and several defenses are designed to alleviate the risk by tweaking the gradients. However, these defenses exhibit weak resilience against threatening attacks, as the effectiveness builds upon the unrealistic assumptions that deep neural networks are simplified as linear models. In this paper, without such unrealistic assumptions, we present a novel defense, called Refiner, instead of perturbing gradients, which refines ground-truth data to craft robust data that yields sufficient utility but with the least amount of privacy information, and then the gradients of robust data are uploaded. To craft robust data, Refiner promotes the gradients of critical parameters associated with robust data to close ground-truth ones while leaving the gradients of trivial parameters to safeguard privacy. Moreover, to exploit the gradients of trivial parameters, Refiner utilizes a well-designed evaluation network to steer robust data far away from ground-truth data, thereby alleviating privacy leakage risk. Extensive experiments across multiple benchmark datasets demonstrate the superior defense effectiveness of Refiner at defending against state-of-the-art threats.