 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvent-Anchored Frame Selection for Effective Long-Video Understanding
Mar 01, 2026Massive frame redundancy and limited context window make efficient frame selection crucial for long-video understanding with large vision-language models (LVLMs). Prevailing approaches, however, adopt a flat sampling paradigm which treats the video as an unstructured collection of frames. In this paper, we introduce Event-Anchored Frame Selection (EFS), a hierarchical, event-aware pipeline. Leveraging self-supervised DINO embeddings, EFS first partitions the video stream into visually homogeneous temporal segments, which serve as proxies for semantic events. Within each event, it then selects the most query-relevant frame as an anchor. These anchors act as structural priors that guide a global refinement stage using an adaptive Maximal Marginal Relevance (MMR) scheme. This pipeline ensures the final keyframe set jointly optimizes for event coverage, query relevance, and visual diversity. As a training-free, plug-and-play module, EFS can be seamlessly integrated into off-the-shelf LVLMs, yielding substantial gains on challenging video understanding benchmarks. Specifically, when applied to LLaVA-Video-7B, EFS improves accuracy by 4.7%, 4.9%, and 8.8% on VideoMME, LongVideoBench, and MLVU, respectively.
Wavelet-based Frame Selection by Detecting Semantic Boundary for Long Video Understanding
Feb 28, 2026Frame selection is crucial due to high frame redundancy and limited context windows when applying Large Vision-Language Models (LVLMs) to long videos. Current methods typically select frames with high relevance to a given query, resulting in a disjointed set of frames that disregard the narrative structure of video. In this paper, we introduce Wavelet-based Frame Selection by Detecting Semantic Boundary (WFS-SB), a training-free framework that presents a new perspective: effective video understanding hinges not only on high relevance but, more importantly, on capturing semantic shifts - pivotal moments of narrative change that are essential to comprehending the holistic storyline of video. However, direct detection of abrupt changes in the query-frame similarity signal is often unreliable due to high-frequency noise arising from model uncertainty and transient visual variations. To address this, we leverage the wavelet transform, which provides an ideal solution through its multi-resolution analysis in both time and frequency domains. By applying this transform, we decompose the noisy signal into multiple scales and extract a clean semantic change signal from the coarsest scale. We identify the local extrema of this signal as semantic boundaries, which segment the video into coherent clips. Building on this, WFS-SB comprises a two-stage strategy: first, adaptively allocating a frame budget to each clip based on a composite importance score; and second, within each clip, employing the Maximal Marginal Relevance approach to select a diverse yet relevant set of frames. Extensive experiments show that WFS-SB significantly boosts LVLM performance, e.g., improving accuracy by 5.5% on VideoMME, 9.5% on MLVU, and 6.2% on LongVideoBench, consistently outperforming state-of-the-art methods.
Distilling Vision-Language Foundation Models: A Data-Free Approach via Prompt Diversification
Jul 21, 2024



Data-Free Knowledge Distillation (DFKD) has shown great potential in creating a compact student model while alleviating the dependency on real training data by synthesizing surrogate data. However, prior arts are seldom discussed under distribution shifts, which may be vulnerable in real-world applications. Recent Vision-Language Foundation Models, e.g., CLIP, have demonstrated remarkable performance in zero-shot out-of-distribution generalization, yet consuming heavy computation resources. In this paper, we discuss the extension of DFKD to Vision-Language Foundation Models without access to the billion-level image-text datasets. The objective is to customize a student model for distribution-agnostic downstream tasks with given category concepts, inheriting the out-of-distribution generalization capability from the pre-trained foundation models. In order to avoid generalization degradation, the primary challenge of this task lies in synthesizing diverse surrogate images driven by text prompts. Since not only category concepts but also style information are encoded in text prompts, we propose three novel Prompt Diversification methods to encourage image synthesis with diverse styles, namely Mix-Prompt, Random-Prompt, and Contrastive-Prompt. Experiments on out-of-distribution generalization datasets demonstrate the effectiveness of the proposed methods, with Contrastive-Prompt performing the best.
MEAT: Median-Ensemble Adversarial Training for Improving Robustness and Generalization
Jun 20, 2024Self-ensemble adversarial training methods improve model robustness by ensembling models at different training epochs, such as model weight averaging (WA). However, previous research has shown that self-ensemble defense methods in adversarial training (AT) still suffer from robust overfitting, which severely affects the generalization performance. Empirically, in the late phases of training, the AT becomes more overfitting to the extent that the individuals for weight averaging also suffer from overfitting and produce anomalous weight values, which causes the self-ensemble model to continue to undergo robust overfitting due to the failure in removing the weight anomalies. To solve this problem, we aim to tackle the influence of outliers in the weight space in this work and propose an easy-to-operate and effective Median-Ensemble Adversarial Training (MEAT) method to solve the robust overfitting phenomenon existing in self-ensemble defense from the source by searching for the median of the historical model weights. Experimental results show that MEAT achieves the best robustness against the powerful AutoAttack and can effectively allievate the robust overfitting. We further demonstrate that most defense methods can improve robust generalization and robustness by combining with MEAT.
Parameter Exchange for Robust Dynamic Domain Generalization
Nov 23, 2023Agnostic domain shift is the main reason of model degradation on the unknown target domains, which brings an urgent need to develop Domain Generalization (DG). Recent advances at DG use dynamic networks to achieve training-free adaptation on the unknown target domains, termed Dynamic Domain Generalization (DDG), which compensates for the lack of self-adaptability in static models with fixed weights. The parameters of dynamic networks can be decoupled into a static and a dynamic component, which are designed to learn domain-invariant and domain-specific features, respectively. Based on the existing arts, in this work, we try to push the limits of DDG by disentangling the static and dynamic components more thoroughly from an optimization perspective. Our main consideration is that we can enable the static component to learn domain-invariant features more comprehensively by augmenting the domain-specific information. As a result, the more comprehensive domain-invariant features learned by the static component can then enforce the dynamic component to focus more on learning adaptive domain-specific features. To this end, we propose a simple yet effective Parameter Exchange (PE) method to perturb the combination between the static and dynamic components. We optimize the model using the gradients from both the perturbed and non-perturbed feed-forward jointly to implicitly achieve the aforementioned disentanglement. In this way, the two components can be optimized in a mutually-beneficial manner, which can resist the agnostic domain shifts and improve the self-adaptability on the unknown target domain. Extensive experiments show that PE can be easily plugged into existing dynamic networks to improve their generalization ability without bells and whistles.
MetaFBP: Learning to Learn High-Order Predictor for Personalized Facial Beauty Prediction
Nov 23, 2023



Predicting individual aesthetic preferences holds significant practical applications and academic implications for human society. However, existing studies mainly focus on learning and predicting the commonality of facial attractiveness, with little attention given to Personalized Facial Beauty Prediction (PFBP). PFBP aims to develop a machine that can adapt to individual aesthetic preferences with only a few images rated by each user. In this paper, we formulate this task from a meta-learning perspective that each user corresponds to a meta-task. To address such PFBP task, we draw inspiration from the human aesthetic mechanism that visual aesthetics in society follows a Gaussian distribution, which motivates us to disentangle user preferences into a commonality and an individuality part. To this end, we propose a novel MetaFBP framework, in which we devise a universal feature extractor to capture the aesthetic commonality and then optimize to adapt the aesthetic individuality by shifting the decision boundary of the predictor via a meta-learning mechanism. Unlike conventional meta-learning methods that may struggle with slow adaptation or overfitting to tiny support sets, we propose a novel approach that optimizes a high-order predictor for fast adaptation. In order to validate the performance of the proposed method, we build several PFBP benchmarks by using existing facial beauty prediction datasets rated by numerous users. Extensive experiments on these benchmarks demonstrate the effectiveness of the proposed MetaFBP method.
Periodically Exchange Teacher-Student for Source-Free Object Detection
Nov 23, 2023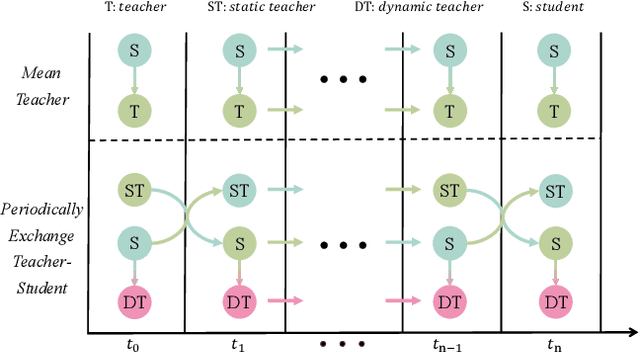
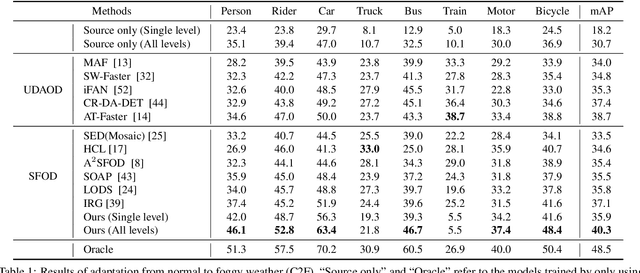
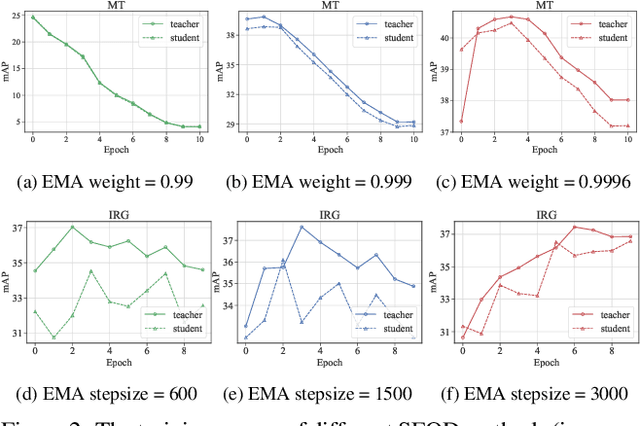
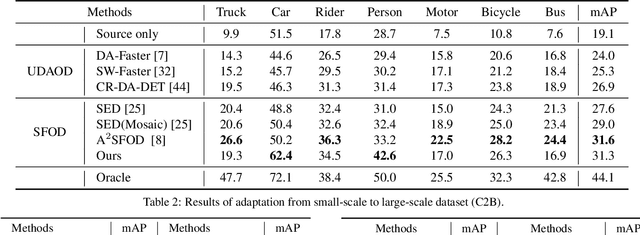
Source-free object detection (SFOD) aims to adapt the source detector to unlabeled target domain data in the absence of source domain data. Most SFOD methods follow the same self-training paradigm using mean-teacher (MT) framework where the student model is guided by only one single teacher model. However, such paradigm can easily fall into a training instability problem that when the teacher model collapses uncontrollably due to the domain shift, the student model also suffers drastic performance degradation. To address this issue, we propose the Periodically Exchange Teacher-Student (PETS) method, a simple yet novel approach that introduces a multiple-teacher framework consisting of a static teacher, a dynamic teacher, and a student model. During the training phase, we periodically exchange the weights between the static teacher and the student model. Then, we update the dynamic teacher using the moving average of the student model that has already been exchanged by the static teacher. In this way, the dynamic teacher can integrate knowledge from past periods, effectively reducing error accumulation and enabling a more stable training process within the MT-based framework. Further, we develop a consensus mechanism to merge the predictions of two teacher models to provide higher-quality pseudo labels for student model. Extensive experiments on multiple SFOD benchmarks show that the proposed method achieves state-of-the-art performance compared with other related methods, demonstrating the effectiveness and superiority of our method on SFOD task.
Adapt Anything: Tailor Any Image Classifiers across Domains And Categories Using Text-to-Image Diffusion Models
Oct 25, 2023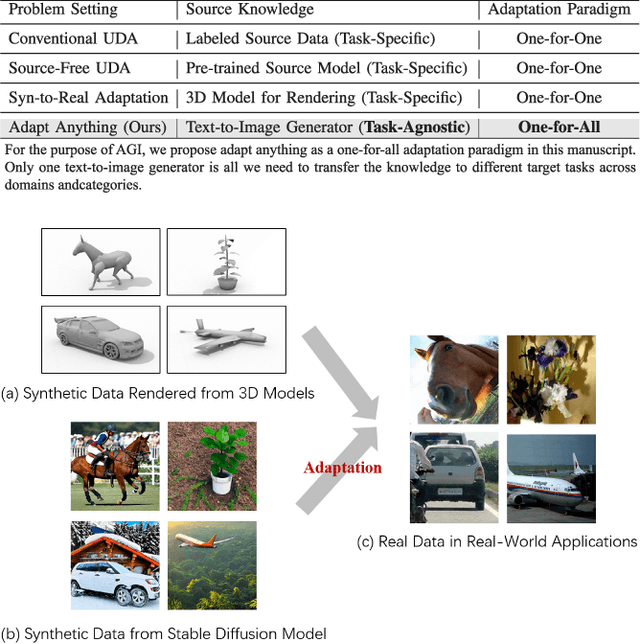
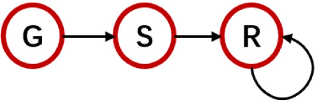

We do not pursue a novel method in this paper, but aim to study if a modern text-to-image diffusion model can tailor any task-adaptive image classifier across domains and categories. Existing domain adaptive image classification works exploit both source and target data for domain alignment so as to transfer the knowledge learned from the labeled source data to the unlabeled target data. However, as the development of the text-to-image diffusion model, we wonder if the high-fidelity synthetic data from the text-to-image generator can serve as a surrogate of the source data in real world. In this way, we do not need to collect and annotate the source data for each domain adaptation task in a one-for-one manner. Instead, we utilize only one off-the-shelf text-to-image model to synthesize images with category labels derived from the corresponding text prompts, and then leverage the surrogate data as a bridge to transfer the knowledge embedded in the task-agnostic text-to-image generator to the task-oriented image classifier via domain adaptation. Such a one-for-all adaptation paradigm allows us to adapt anything in the world using only one text-to-image generator as well as the corresponding unlabeled target data. Extensive experiments validate the feasibility of the proposed idea, which even surpasses the state-of-the-art domain adaptation works using the source data collected and annotated in real world.
Slimmable Domain Adaptation
Jun 14, 2022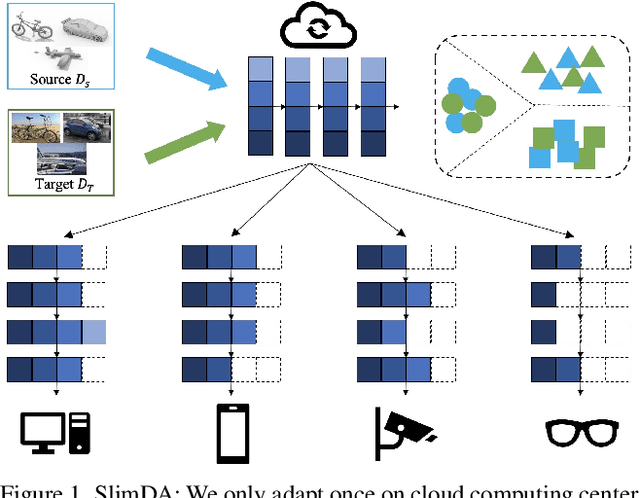

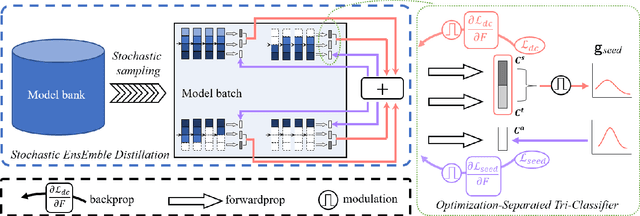
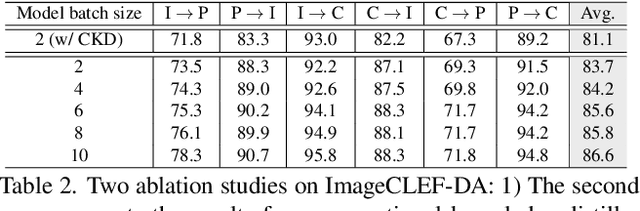
Vanilla unsupervised domain adaptation methods tend to optimize the model with fixed neural architecture, which is not very practical in real-world scenarios since the target data is usually processed by different resource-limited devices. It is therefore of great necessity to facilitate architecture adaptation across various devices. In this paper, we introduce a simple framework, Slimmable Domain Adaptation, to improve cross-domain generalization with a weight-sharing model bank, from which models of different capacities can be sampled to accommodate different accuracy-efficiency trade-offs. The main challenge in this framework lies in simultaneously boosting the adaptation performance of numerous models in the model bank. To tackle this problem, we develop a Stochastic EnsEmble Distillation method to fully exploit the complementary knowledge in the model bank for inter-model interaction. Nevertheless, considering the optimization conflict between inter-model interaction and intra-model adaptation, we augment the existing bi-classifier domain confusion architecture into an Optimization-Separated Tri-Classifier counterpart. After optimizing the model bank, architecture adaptation is leveraged via our proposed Unsupervised Performance Evaluation Metric. Under various resource constraints, our framework surpasses other competing approaches by a very large margin on multiple benchmarks. It is also worth emphasizing that our framework can preserve the performance improvement against the source-only model even when the computing complexity is reduced to $1/64$. Code will be available at https://github.com/hikvision-research/SlimDA.
* To appear in CVPR 2022. Code is coming soon: https://github.com/hikvision-research/SlimDA
Dynamic Domain Generalization
May 27, 2022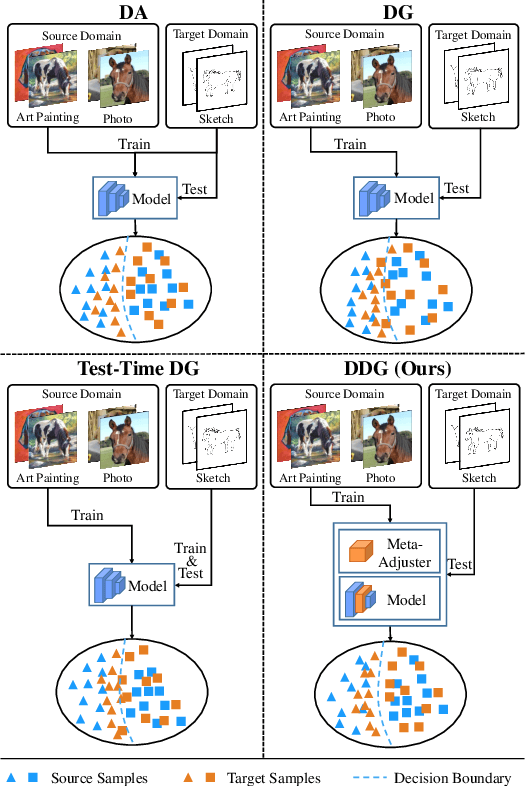
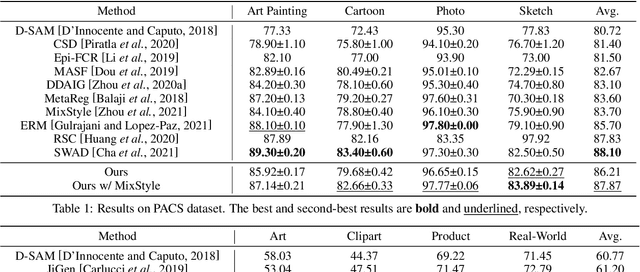

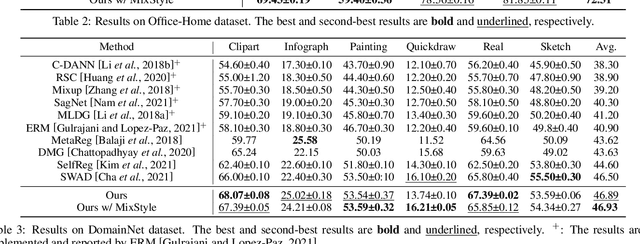
Domain generalization (DG) is a fundamental yet very challenging research topic in machine learning. The existing arts mainly focus on learning domain-invariant features with limited source domains in a static model. Unfortunately, there is a lack of training-free mechanism to adjust the model when generalized to the agnostic target domains. To tackle this problem, we develop a brand-new DG variant, namely Dynamic Domain Generalization (DDG), in which the model learns to twist the network parameters to adapt the data from different domains. Specifically, we leverage a meta-adjuster to twist the network parameters based on the static model with respect to different data from different domains. In this way, the static model is optimized to learn domain-shared features, while the meta-adjuster is designed to learn domain-specific features. To enable this process, DomainMix is exploited to simulate data from diverse domains during teaching the meta-adjuster to adapt to the upcoming agnostic target domains. This learning mechanism urges the model to generalize to different agnostic target domains via adjusting the model without training. Extensive experiments demonstrate the effectiveness of our proposed method. Code is available at: https://github.com/MetaVisionLab/DDG