 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemi-Supervised Domain Generalization in Real World:New Benchmark and Strong Baseline
Paper and Code
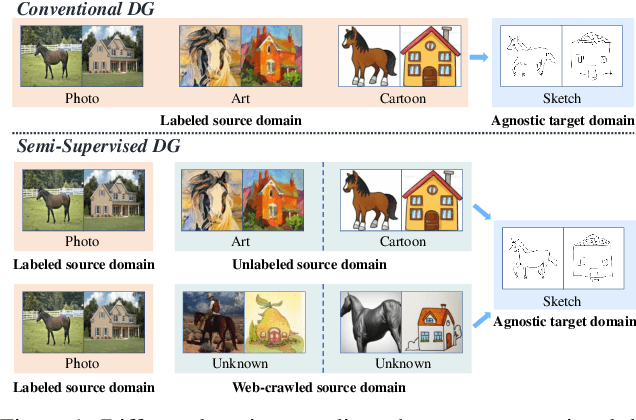
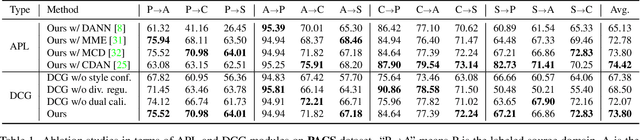
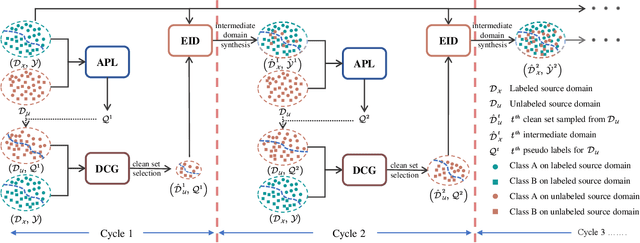
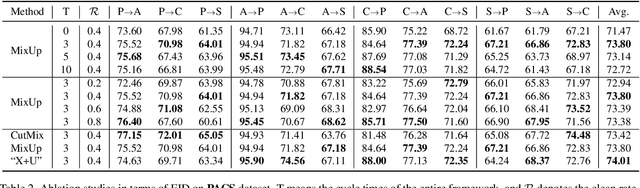
Conventional domain generalization aims to learn domain invariant representation from multiple domains, which requires accurate annotations. In realistic application scenarios, however, it is too cumbersome or even infeasible to collect and annotate the large mass of data. Yet, web data provides a free lunch to access a huge amount of unlabeled data with rich style information that can be harnessed to augment domain generalization ability. In this paper, we introduce a novel task, termed as semi-supervised domain generalization, to study how to interact the labeled and unlabeled domains, and establish two benchmarks including a web-crawled dataset, which poses a novel yet realistic challenge to push the limits of existing technologies. To tackle this task, a straightforward solution is to propagate the class information from the labeled to the unlabeled domains via pseudo labeling in conjunction with domain confusion training. Considering narrowing domain gap can improve the quality of pseudo labels and further advance domain invariant feature learning for generalization, we propose a cycle learning framework to encourage the positive feedback between label propagation and domain generalization, in favor of an evolving intermediate domain bridging the labeled and unlabeled domains in a curriculum learning manner. Experiments are conducted to validate the effectiveness of our framework. It is worth highlighting that web-crawled data benefits domain generalization as demonstrated in our results. Our code will be available later.