 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeURWKV: Unified RWKV Model with Multi-state Perspective for Low-light Image Restoration
May 29, 2025Existing low-light image enhancement (LLIE) and joint LLIE and deblurring (LLIE-deblur) models have made strides in addressing predefined degradations, yet they are often constrained by dynamically coupled degradations. To address these challenges, we introduce a Unified Receptance Weighted Key Value (URWKV) model with multi-state perspective, enabling flexible and effective degradation restoration for low-light images. Specifically, we customize the core URWKV block to perceive and analyze complex degradations by leveraging multiple intra- and inter-stage states. First, inspired by the pupil mechanism in the human visual system, we propose Luminance-adaptive Normalization (LAN) that adjusts normalization parameters based on rich inter-stage states, allowing for adaptive, scene-aware luminance modulation. Second, we aggregate multiple intra-stage states through exponential moving average approach, effectively capturing subtle variations while mitigating information loss inherent in the single-state mechanism. To reduce the degradation effects commonly associated with conventional skip connections, we propose the State-aware Selective Fusion (SSF) module, which dynamically aligns and integrates multi-state features across encoder stages, selectively fusing contextual information. In comparison to state-of-the-art models, our URWKV model achieves superior performance on various benchmarks, while requiring significantly fewer parameters and computational resources.
Revisiting Network Perturbation for Semi-Supervised Semantic Segmentation
Nov 08, 2024In semi-supervised semantic segmentation (SSS), weak-to-strong consistency regularization techniques are widely utilized in recent works, typically combined with input-level and feature-level perturbations. However, the integration between weak-to-strong consistency regularization and network perturbation has been relatively rare. We note several problems with existing network perturbations in SSS that may contribute to this phenomenon. By revisiting network perturbations, we introduce a new approach for network perturbation to expand the existing weak-to-strong consistency regularization for unlabeled data. Additionally, we present a volatile learning process for labeled data, which is uncommon in existing research. Building upon previous work that includes input-level and feature-level perturbations, we present MLPMatch (Multi-Level-Perturbation Match), an easy-to-implement and efficient framework for semi-supervised semantic segmentation. MLPMatch has been validated on the Pascal VOC and Cityscapes datasets, achieving state-of-the-art performance. Code is available from https://github.com/LlistenL/MLPMatch.
Beyond Night Visibility: Adaptive Multi-Scale Fusion of Infrared and Visible Images
Mar 02, 2024
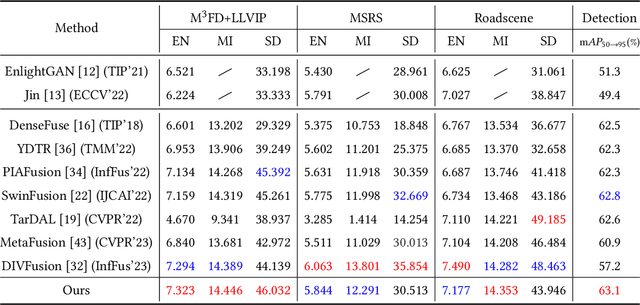
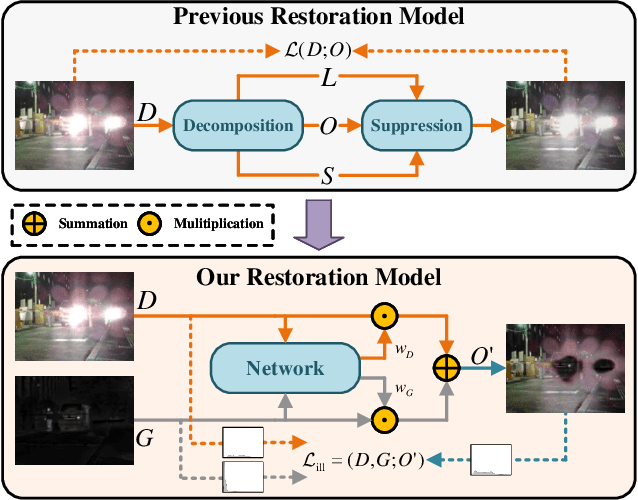
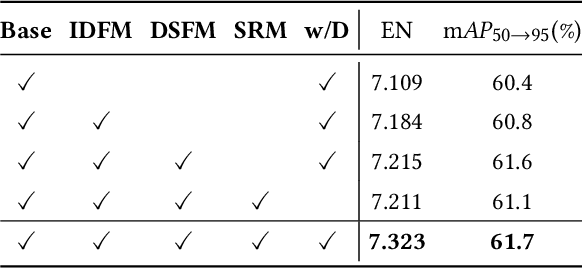
In addition to low light, night images suffer degradation from light effects (e.g., glare, floodlight, etc). However, existing nighttime visibility enhancement methods generally focus on low-light regions, which neglects, or even amplifies the light effects. To address this issue, we propose an Adaptive Multi-scale Fusion network (AMFusion) with infrared and visible images, which designs fusion rules according to different illumination regions. First, we separately fuse spatial and semantic features from infrared and visible images, where the former are used for the adjustment of light distribution and the latter are used for the improvement of detection accuracy. Thereby, we obtain an image free of low light and light effects, which improves the performance of nighttime object detection. Second, we utilize detection features extracted by a pre-trained backbone that guide the fusion of semantic features. Hereby, we design a Detection-guided Semantic Fusion Module (DSFM) to bridge the domain gap between detection and semantic features. Third, we propose a new illumination loss to constrain fusion image with normal light intensity. Experimental results demonstrate the superiority of AMFusion with better visual quality and detection accuracy. The source code will be released after the peer review process.
Distractor-aware Event-based Tracking
Oct 29, 2023



Event cameras, or dynamic vision sensors, have recently achieved success from fundamental vision tasks to high-level vision researches. Due to its ability to asynchronously capture light intensity changes, event camera has an inherent advantage to capture moving objects in challenging scenarios including objects under low light, high dynamic range, or fast moving objects. Thus event camera are natural for visual object tracking. However, the current event-based trackers derived from RGB trackers simply modify the input images to event frames and still follow conventional tracking pipeline that mainly focus on object texture for target distinction. As a result, the trackers may not be robust dealing with challenging scenarios such as moving cameras and cluttered foreground. In this paper, we propose a distractor-aware event-based tracker that introduces transformer modules into Siamese network architecture (named DANet). Specifically, our model is mainly composed of a motion-aware network and a target-aware network, which simultaneously exploits both motion cues and object contours from event data, so as to discover motion objects and identify the target object by removing dynamic distractors. Our DANet can be trained in an end-to-end manner without any post-processing and can run at over 80 FPS on a single V100. We conduct comprehensive experiments on two large event tracking datasets to validate the proposed model. We demonstrate that our tracker has superior performance against the state-of-the-art trackers in terms of both accuracy and efficiency.
Memory-Constrained Semantic Segmentation for Ultra-High Resolution UAV Imagery
Oct 07, 2023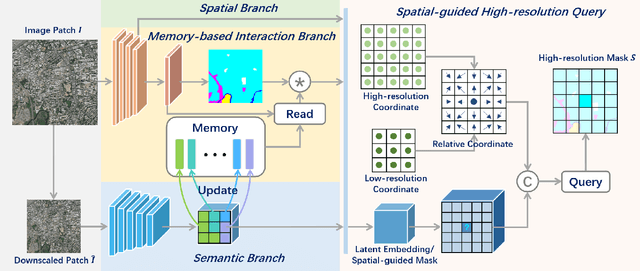
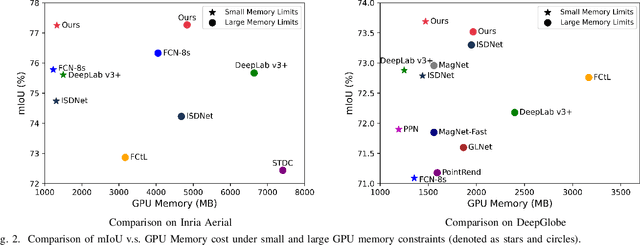
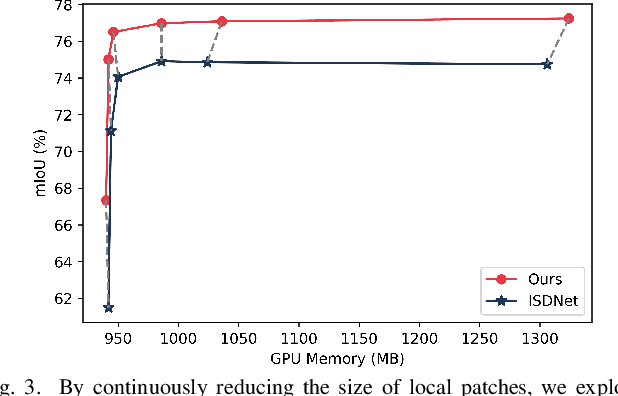

Amidst the swift advancements in photography and sensor technologies, high-definition cameras have become commonplace in the deployment of Unmanned Aerial Vehicles (UAVs) for diverse operational purposes. Within the domain of UAV imagery analysis, the segmentation of ultra-high resolution images emerges as a substantial and intricate challenge, especially when grappling with the constraints imposed by GPU memory-restricted computational devices. This paper delves into the intricate problem of achieving efficient and effective segmentation of ultra-high resolution UAV imagery, while operating under stringent GPU memory limitation. The strategy of existing approaches is to downscale the images to achieve computationally efficient segmentation. However, this strategy tends to overlook smaller, thinner, and curvilinear regions. To address this problem, we propose a GPU memory-efficient and effective framework for local inference without accessing the context beyond local patches. In particular, we introduce a novel spatial-guided high-resolution query module, which predicts pixel-wise segmentation results with high quality only by querying nearest latent embeddings with the guidance of high-resolution information. Additionally, we present an efficient memory-based interaction scheme to correct potential semantic bias of the underlying high-resolution information by associating cross-image contextual semantics. For evaluation of our approach, we perform comprehensive experiments over public benchmarks and achieve superior performance under both conditions of small and large GPU memory usage limitations. We will release the model and codes in the future.
Frame-Event Alignment and Fusion Network for High Frame Rate Tracking
May 25, 2023



Most existing RGB-based trackers target low frame rate benchmarks of around 30 frames per second. This setting restricts the tracker's functionality in the real world, especially for fast motion. Event-based cameras as bioinspired sensors provide considerable potential for high frame rate tracking due to their high temporal resolution. However, event-based cameras cannot offer fine-grained texture information like conventional cameras. This unique complementarity motivates us to combine conventional frames and events for high frame rate object tracking under various challenging conditions. Inthispaper, we propose an end-to-end network consisting of multi-modality alignment and fusion modules to effectively combine meaningful information from both modalities at different measurement rates. The alignment module is responsible for cross-style and cross-frame-rate alignment between frame and event modalities under the guidance of the moving cues furnished by events. While the fusion module is accountable for emphasizing valuable features and suppressing noise information by the mutual complement between the two modalities. Extensive experiments show that the proposed approach outperforms state-of-the-art trackers by a significant margin in high frame rate tracking. With the FE240hz dataset, our approach achieves high frame rate tracking up to 240Hz.
Single-View View Synthesis with Self-Rectified Pseudo-Stereo
Apr 20, 2023Synthesizing novel views from a single view image is a highly ill-posed problem. We discover an effective solution to reduce the learning ambiguity by expanding the single-view view synthesis problem to a multi-view setting. Specifically, we leverage the reliable and explicit stereo prior to generate a pseudo-stereo viewpoint, which serves as an auxiliary input to construct the 3D space. In this way, the challenging novel view synthesis process is decoupled into two simpler problems of stereo synthesis and 3D reconstruction. In order to synthesize a structurally correct and detail-preserved stereo image, we propose a self-rectified stereo synthesis to amend erroneous regions in an identify-rectify manner. Hard-to-train and incorrect warping samples are first discovered by two strategies, 1) pruning the network to reveal low-confident predictions; and 2) bidirectionally matching between stereo images to allow the discovery of improper mapping. These regions are then inpainted to form the final pseudo-stereo. With the aid of this extra input, a preferable 3D reconstruction can be easily obtained, and our method can work with arbitrary 3D representations. Extensive experiments show that our method outperforms state-of-the-art single-view view synthesis methods and stereo synthesis methods.
Monocular BEV Perception of Road Scenes via Front-to-Top View Projection
Nov 15, 2022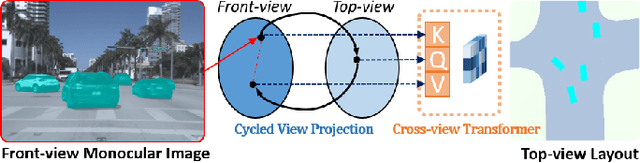



HD map reconstruction is crucial for autonomous driving. LiDAR-based methods are limited due to expensive sensors and time-consuming computation. Camera-based methods usually need to perform road segmentation and view transformation separately, which often causes distortion and missing content. To push the limits of the technology, we present a novel framework that reconstructs a local map formed by road layout and vehicle occupancy in the bird's-eye view given a front-view monocular image only. We propose a front-to-top view projection (FTVP) module, which takes the constraint of cycle consistency between views into account and makes full use of their correlation to strengthen the view transformation and scene understanding. In addition, we also apply multi-scale FTVP modules to propagate the rich spatial information of low-level features to mitigate spatial deviation of the predicted object location. Experiments on public benchmarks show that our method achieves the state-of-the-art performance in the tasks of road layout estimation, vehicle occupancy estimation, and multi-class semantic estimation. For multi-class semantic estimation, in particular, our model outperforms all competitors by a large margin. Furthermore, our model runs at 25 FPS on a single GPU, which is efficient and applicable for real-time panorama HD map reconstruction.
Glance to Count: Learning to Rank with Anchors for Weakly-supervised Crowd Counting
May 29, 2022
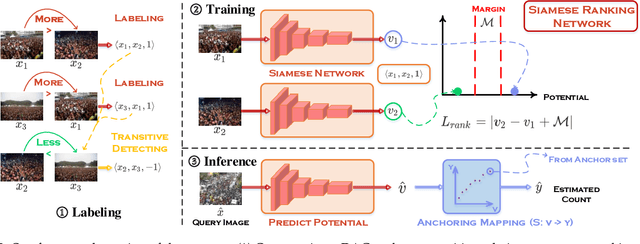


Crowd image is arguably one of the most laborious data to annotate. In this paper, we devote to reduce the massive demand of densely labeled crowd data, and propose a novel weakly-supervised setting, in which we leverage the binary ranking of two images with high-contrast crowd counts as training guidance. To enable training under this new setting, we convert the crowd count regression problem to a ranking potential prediction problem. In particular, we tailor a Siamese Ranking Network that predicts the potential scores of two images indicating the ordering of the counts. Hence, the ultimate goal is to assign appropriate potentials for all the crowd images to ensure their orderings obey the ranking labels. On the other hand, potentials reveal the relative crowd sizes but cannot yield an exact crowd count. We resolve this problem by introducing "anchors" during the inference stage. Concretely, anchors are a few images with count labels used for referencing the corresponding counts from potential scores by a simple linear mapping function. We conduct extensive experiments to study various combinations of supervision, and we show that the proposed method outperforms existing weakly-supervised methods without additional labeling effort by a large margin.
End-to-End Trajectory Distribution Prediction Based on Occupancy Grid Maps
Mar 31, 2022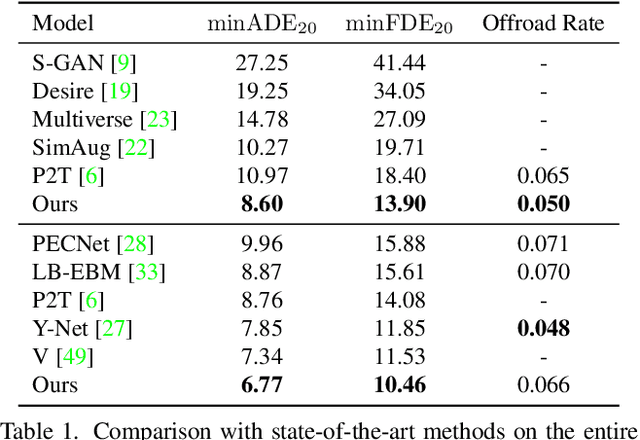
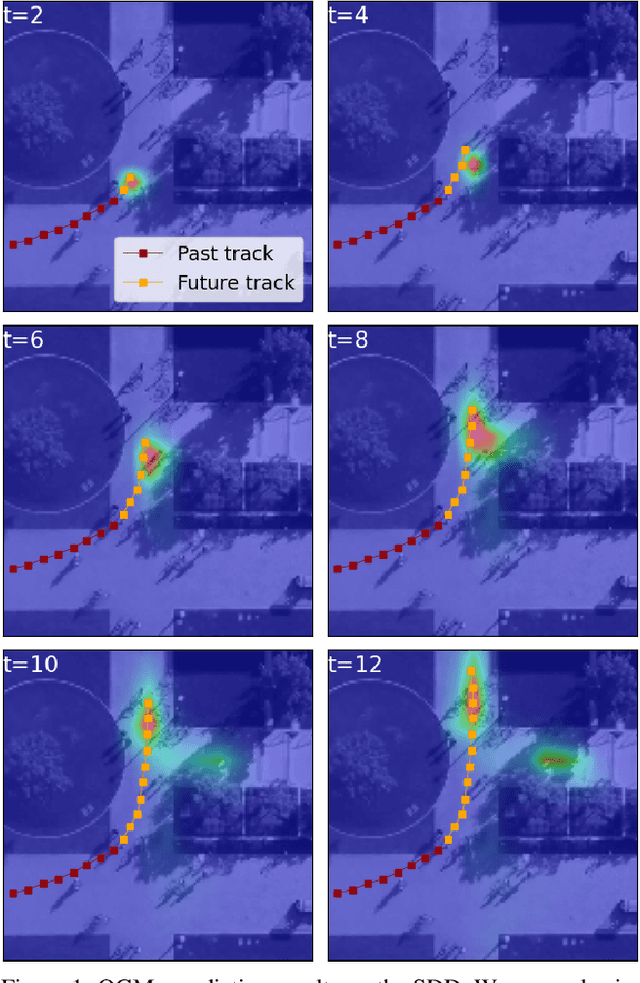
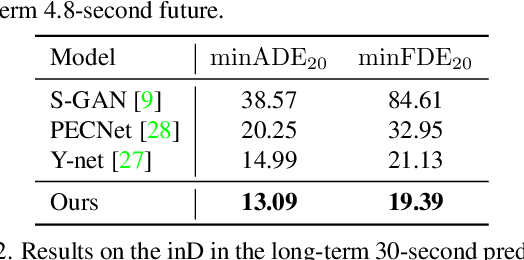
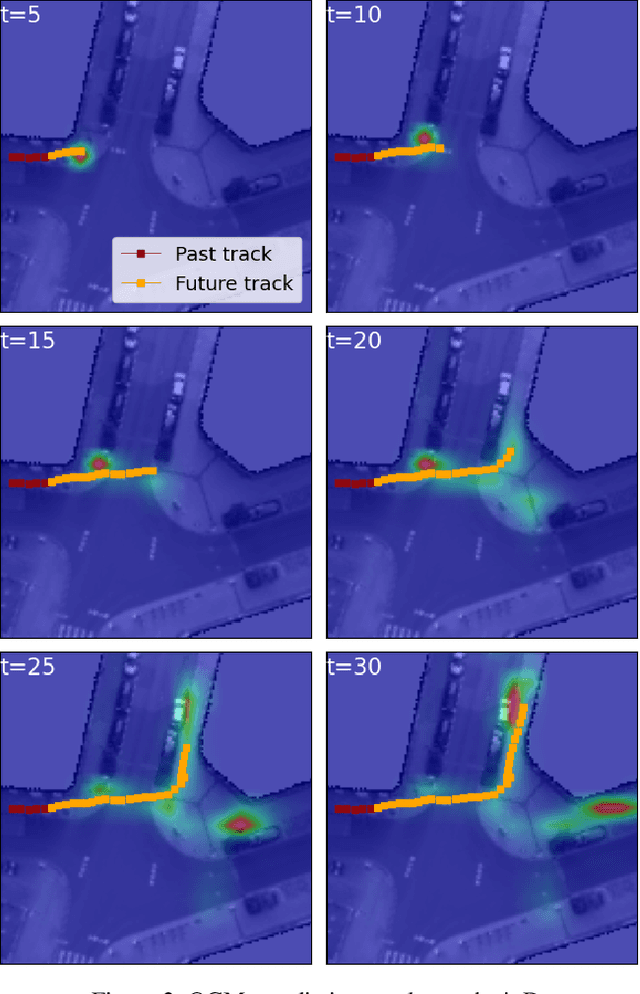
In this paper, we aim to forecast a future trajectory distribution of a moving agent in the real world, given the social scene images and historical trajectories. Yet, it is a challenging task because the ground-truth distribution is unknown and unobservable, while only one of its samples can be applied for supervising model learning, which is prone to bias. Most recent works focus on predicting diverse trajectories in order to cover all modes of the real distribution, but they may despise the precision and thus give too much credit to unrealistic predictions. To address the issue, we learn the distribution with symmetric cross-entropy using occupancy grid maps as an explicit and scene-compliant approximation to the ground-truth distribution, which can effectively penalize unlikely predictions. In specific, we present an inverse reinforcement learning based multi-modal trajectory distribution forecasting framework that learns to plan by an approximate value iteration network in an end-to-end manner. Besides, based on the predicted distribution, we generate a small set of representative trajectories through a differentiable Transformer-based network, whose attention mechanism helps to model the relations of trajectories. In experiments, our method achieves state-of-the-art performance on the Stanford Drone Dataset and Intersection Drone Dataset.