 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyperVLA: Efficient Inference in Vision-Language-Action Models via Hypernetworks
Oct 06, 2025Built upon language and vision foundation models with strong generalization ability and trained on large-scale robotic data, Vision-Language-Action (VLA) models have recently emerged as a promising approach to learning generalist robotic policies. However, a key drawback of existing VLAs is their extremely high inference costs. In this paper, we propose HyperVLA to address this problem. Unlike existing monolithic VLAs that activate the whole model during both training and inference, HyperVLA uses a novel hypernetwork (HN)-based architecture that activates only a small task-specific policy during inference, while still retaining the high model capacity needed to accommodate diverse multi-task behaviors during training. Successfully training an HN-based VLA is nontrivial so HyperVLA contains several key algorithm design features that improve its performance, including properly utilizing the prior knowledge from existing vision foundation models, HN normalization, and an action generation strategy. Compared to monolithic VLAs, HyperVLA achieves a similar or even higher success rate for both zero-shot generalization and few-shot adaptation, while significantly reducing inference costs. Compared to OpenVLA, a state-of-the-art VLA model, HyperVLA reduces the number of activated parameters at test time by $90\times$, and accelerates inference speed by $120\times$. Code is publicly available at https://github.com/MasterXiong/HyperVLA
An Improved YOLOv8 Approach for Small Target Detection of Rice Spikelet Flowering in Field Environments
Jul 28, 2025Accurately detecting rice flowering time is crucial for timely pollination in hybrid rice seed production. This not only enhances pollination efficiency but also ensures higher yields. However, due to the complexity of field environments and the characteristics of rice spikelets, such as their small size and short flowering period, automated and precise recognition remains challenging. To address this, this study proposes a rice spikelet flowering recognition method based on an improved YOLOv8 object detection model. First, a Bidirectional Feature Pyramid Network (BiFPN) replaces the original PANet structure to enhance feature fusion and improve multi-scale feature utilization. Second, to boost small object detection, a p2 small-object detection head is added, using finer feature mapping to reduce feature loss commonly seen in detecting small targets. Given the lack of publicly available datasets for rice spikelet flowering in field conditions, a high-resolution RGB camera and data augmentation techniques are used to construct a dedicated dataset, providing reliable support for model training and testing. Experimental results show that the improved YOLOv8s-p2 model achieves an mAP@0.5 of 65.9%, precision of 67.6%, recall of 61.5%, and F1-score of 64.41%, representing improvements of 3.10%, 8.40%, 10.80%, and 9.79%, respectively, over the baseline YOLOv8. The model also runs at 69 f/s on the test set, meeting practical application requirements. Overall, the improved YOLOv8s-p2 offers high accuracy and speed, providing an effective solution for automated monitoring in hybrid rice seed production.
DiT4SR: Taming Diffusion Transformer for Real-World Image Super-Resolution
Mar 30, 2025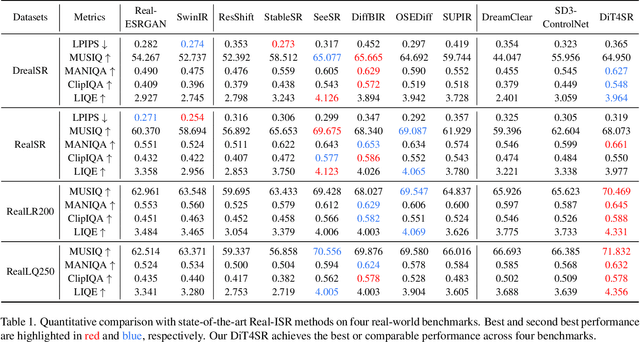
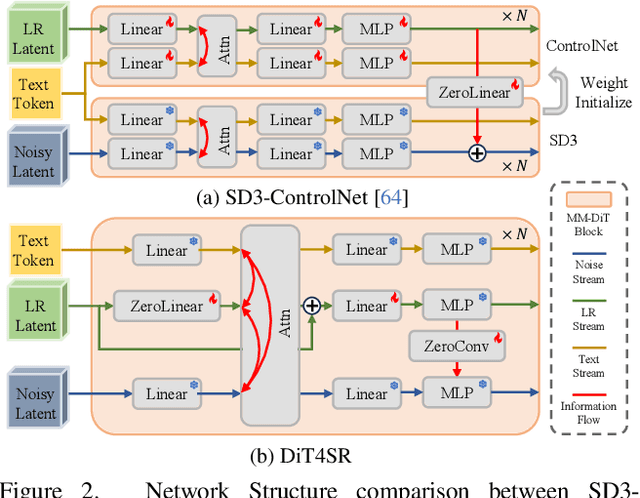
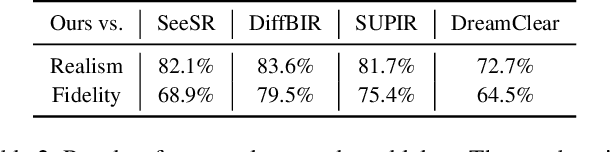
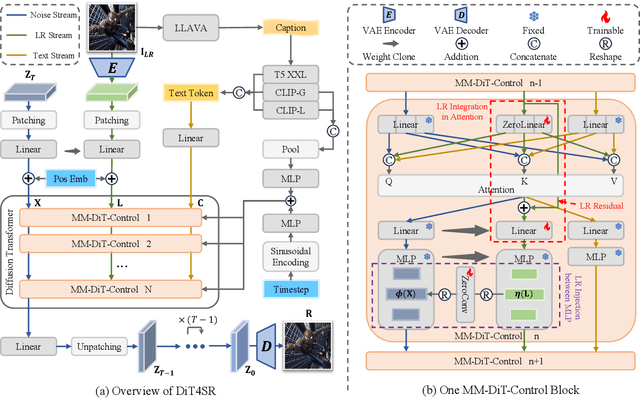
Large-scale pre-trained diffusion models are becoming increasingly popular in solving the Real-World Image Super-Resolution (Real-ISR) problem because of their rich generative priors. The recent development of diffusion transformer (DiT) has witnessed overwhelming performance over the traditional UNet-based architecture in image generation, which also raises the question: Can we adopt the advanced DiT-based diffusion model for Real-ISR? To this end, we propose our DiT4SR, one of the pioneering works to tame the large-scale DiT model for Real-ISR. Instead of directly injecting embeddings extracted from low-resolution (LR) images like ControlNet, we integrate the LR embeddings into the original attention mechanism of DiT, allowing for the bidirectional flow of information between the LR latent and the generated latent. The sufficient interaction of these two streams allows the LR stream to evolve with the diffusion process, producing progressively refined guidance that better aligns with the generated latent at each diffusion step. Additionally, the LR guidance is injected into the generated latent via a cross-stream convolution layer, compensating for DiT's limited ability to capture local information. These simple but effective designs endow the DiT model with superior performance in Real-ISR, which is demonstrated by extensive experiments. Project Page: https://adam-duan.github.io/projects/dit4sr/.
SplAgger: Split Aggregation for Meta-Reinforcement Learning
Mar 08, 2024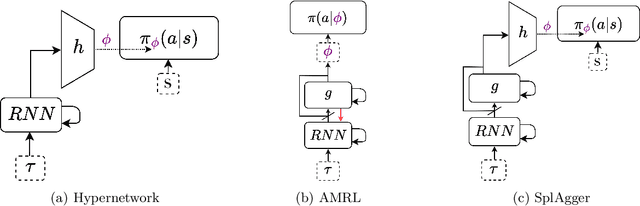
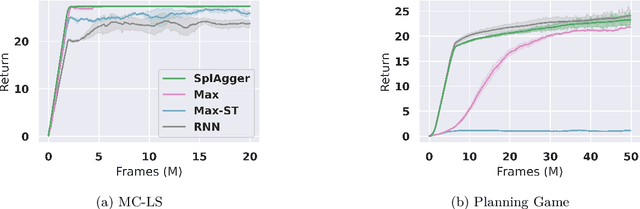
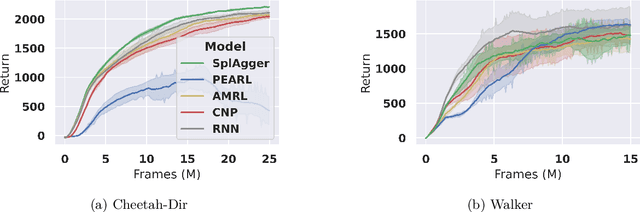
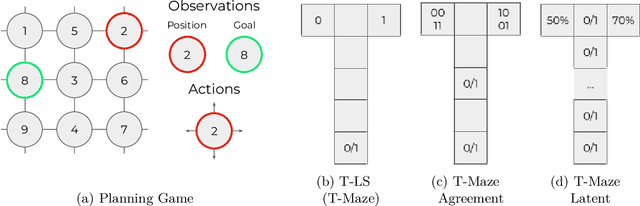
A core ambition of reinforcement learning (RL) is the creation of agents capable of rapid learning in novel tasks. Meta-RL aims to achieve this by directly learning such agents. Black box methods do so by training off-the-shelf sequence models end-to-end. By contrast, task inference methods explicitly infer a posterior distribution over the unknown task, typically using distinct objectives and sequence models designed to enable task inference. Recent work has shown that task inference methods are not necessary for strong performance. However, it remains unclear whether task inference sequence models are beneficial even when task inference objectives are not. In this paper, we present strong evidence that task inference sequence models are still beneficial. In particular, we investigate sequence models with permutation invariant aggregation, which exploit the fact that, due to the Markov property, the task posterior does not depend on the order of data. We empirically confirm the advantage of permutation invariant sequence models without the use of task inference objectives. However, we also find, surprisingly, that there are multiple conditions under which permutation variance remains useful. Therefore, we propose SplAgger, which uses both permutation variant and invariant components to achieve the best of both worlds, outperforming all baselines on continuous control and memory environments.
Distilling Morphology-Conditioned Hypernetworks for Efficient Universal Morphology Control
Feb 09, 2024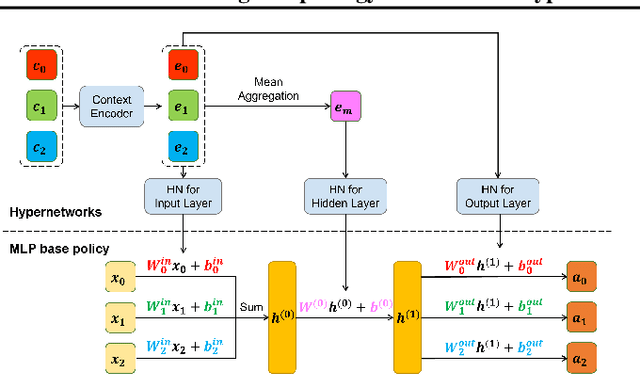
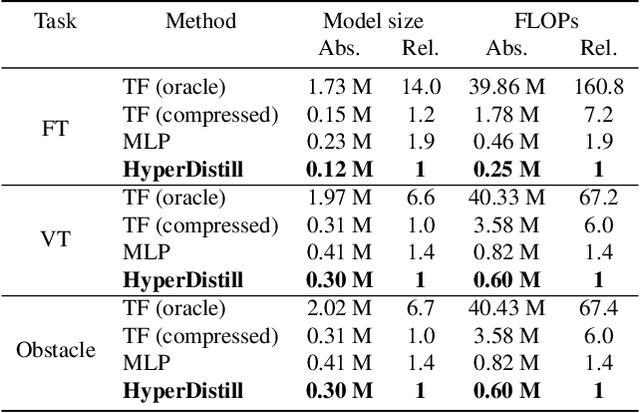
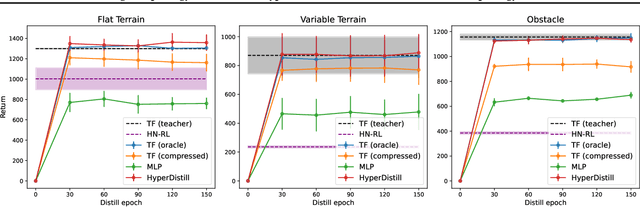

Learning a universal policy across different robot morphologies can significantly improve learning efficiency and enable zero-shot generalization to unseen morphologies. However, learning a highly performant universal policy requires sophisticated architectures like transformers (TF) that have larger memory and computational cost than simpler multi-layer perceptrons (MLP). To achieve both good performance like TF and high efficiency like MLP at inference time, we propose HyperDistill, which consists of: (1) A morphology-conditioned hypernetwork (HN) that generates robot-wise MLP policies, and (2) A policy distillation approach that is essential for successful training. We show that on UNIMAL, a benchmark with hundreds of diverse morphologies, HyperDistill performs as well as a universal TF teacher policy on both training and unseen test robots, but reduces model size by 6-14 times, and computational cost by 67-160 times in different environments. Our analysis attributes the efficiency advantage of HyperDistill at inference time to knowledge decoupling, i.e., the ability to decouple inter-task and intra-task knowledge, a general principle that could also be applied to improve inference efficiency in other domains.
Pangu-Agent: A Fine-Tunable Generalist Agent with Structured Reasoning
Dec 22, 2023



A key method for creating Artificial Intelligence (AI) agents is Reinforcement Learning (RL). However, constructing a standalone RL policy that maps perception to action directly encounters severe problems, chief among them being its lack of generality across multiple tasks and the need for a large amount of training data. The leading cause is that it cannot effectively integrate prior information into the perception-action cycle when devising the policy. Large language models (LLMs) emerged as a fundamental way to incorporate cross-domain knowledge into AI agents but lack crucial learning and adaptation toward specific decision problems. This paper presents a general framework model for integrating and learning structured reasoning into AI agents' policies. Our methodology is motivated by the modularity found in the human brain. The framework utilises the construction of intrinsic and extrinsic functions to add previous understandings of reasoning structures. It also provides the adaptive ability to learn models inside every module or function, consistent with the modular structure of cognitive processes. We describe the framework in-depth and compare it with other AI pipelines and existing frameworks. The paper explores practical applications, covering experiments that show the effectiveness of our method. Our results indicate that AI agents perform and adapt far better when organised reasoning and prior knowledge are embedded. This opens the door to more resilient and general AI agent systems.
Recurrent Hypernetworks are Surprisingly Strong in Meta-RL
Sep 26, 2023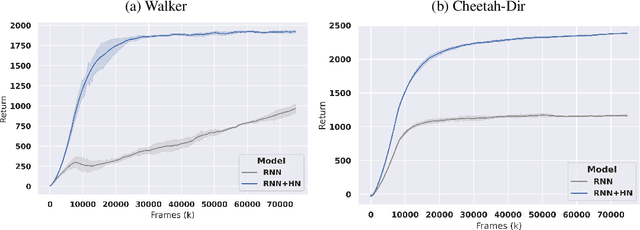
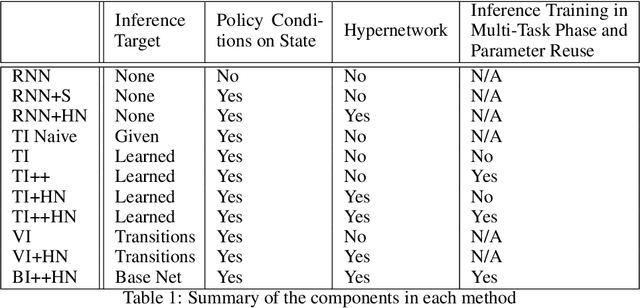
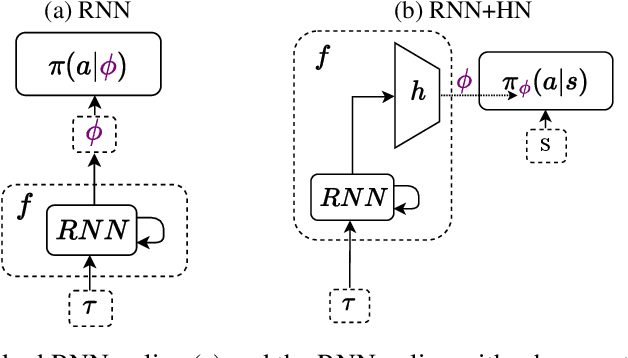
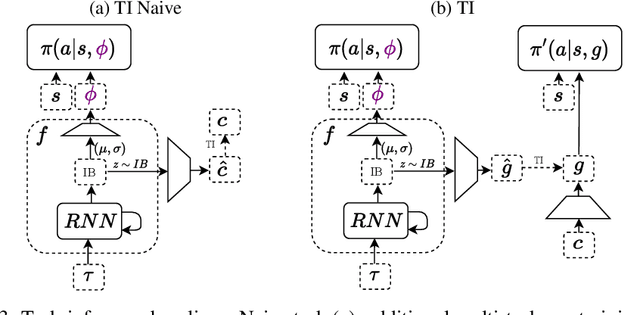
Deep reinforcement learning (RL) is notoriously impractical to deploy due to sample inefficiency. Meta-RL directly addresses this sample inefficiency by learning to perform few-shot learning when a distribution of related tasks is available for meta-training. While many specialized meta-RL methods have been proposed, recent work suggests that end-to-end learning in conjunction with an off-the-shelf sequential model, such as a recurrent network, is a surprisingly strong baseline. However, such claims have been controversial due to limited supporting evidence, particularly in the face of prior work establishing precisely the opposite. In this paper, we conduct an empirical investigation. While we likewise find that a recurrent network can achieve strong performance, we demonstrate that the use of hypernetworks is crucial to maximizing their potential. Surprisingly, when combined with hypernetworks, the recurrent baselines that are far simpler than existing specialized methods actually achieve the strongest performance of all methods evaluated.
Decentralized Multi-agent Reinforcement Learning based State-of-Charge Balancing Strategy for Distributed Energy Storage System
Aug 29, 2023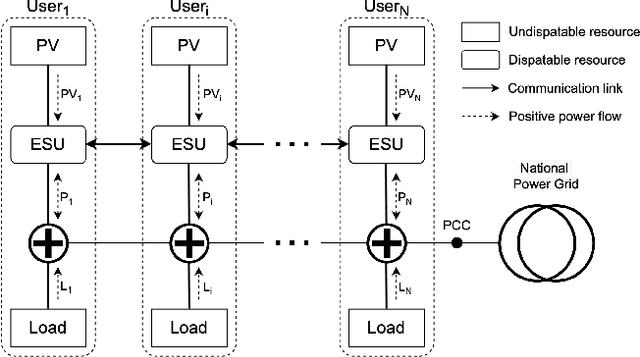
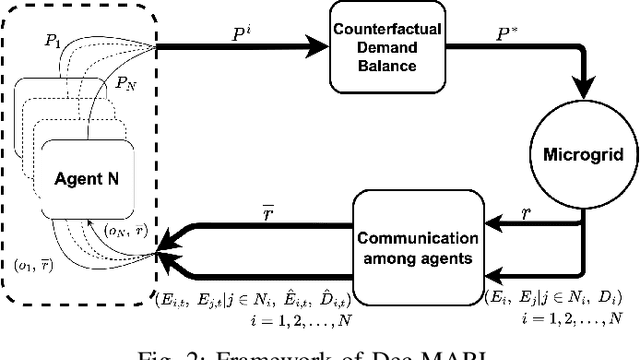
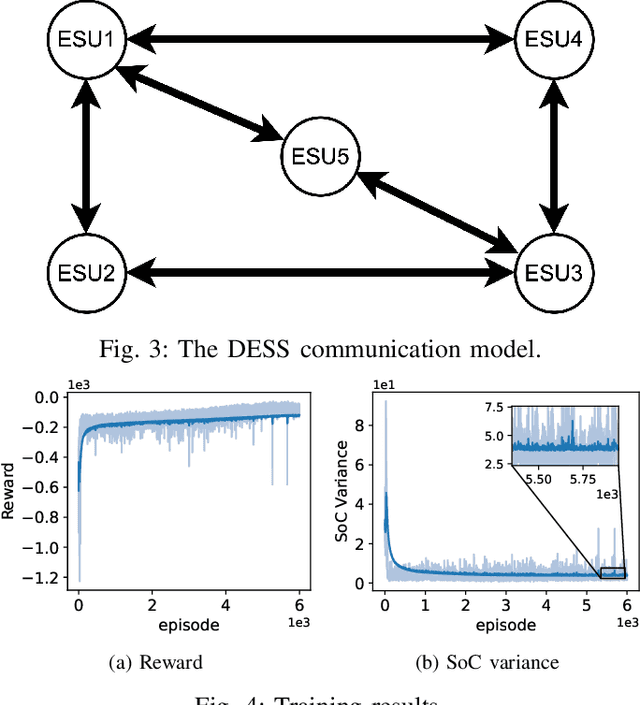
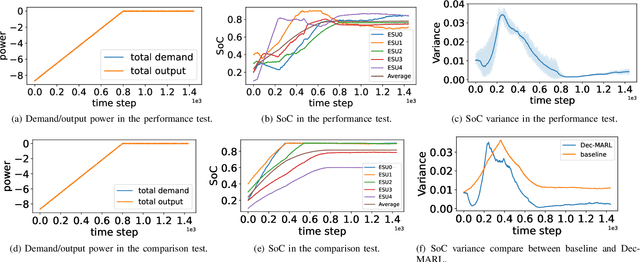
This paper develops a Decentralized Multi-Agent Reinforcement Learning (Dec-MARL) method to solve the SoC balancing problem in the distributed energy storage system (DESS). First, the SoC balancing problem is formulated into a finite Markov decision process with action constraints derived from demand balance, which can be solved by Dec-MARL. Specifically, the first-order average consensus algorithm is utilized to expand the observations of the DESS state in a fully-decentralized way, and the initial actions (i.e., output power) are decided by the agents (i.e., energy storage units) according to these observations. In order to get the final actions in the allowable range, a counterfactual demand balance algorithm is proposed to balance the total demand and the initial actions. Next, the agents execute the final actions and get local rewards from the environment, and the DESS steps into the next state. Finally, through the first-order average consensus algorithm, the agents get the average reward and the expended observation of the next state for later training. By the above procedure, Dec-MARL reveals outstanding performance in a fully-decentralized system without any expert experience or constructing any complicated model. Besides, it is flexible and can be extended to other decentralized multi-agent systems straightforwardly. Extensive simulations have validated the effectiveness and efficiency of Dec-MARL.
Single-View View Synthesis with Self-Rectified Pseudo-Stereo
Apr 20, 2023Synthesizing novel views from a single view image is a highly ill-posed problem. We discover an effective solution to reduce the learning ambiguity by expanding the single-view view synthesis problem to a multi-view setting. Specifically, we leverage the reliable and explicit stereo prior to generate a pseudo-stereo viewpoint, which serves as an auxiliary input to construct the 3D space. In this way, the challenging novel view synthesis process is decoupled into two simpler problems of stereo synthesis and 3D reconstruction. In order to synthesize a structurally correct and detail-preserved stereo image, we propose a self-rectified stereo synthesis to amend erroneous regions in an identify-rectify manner. Hard-to-train and incorrect warping samples are first discovered by two strategies, 1) pruning the network to reveal low-confident predictions; and 2) bidirectionally matching between stereo images to allow the discovery of improper mapping. These regions are then inpainted to form the final pseudo-stereo. With the aid of this extra input, a preferable 3D reconstruction can be easily obtained, and our method can work with arbitrary 3D representations. Extensive experiments show that our method outperforms state-of-the-art single-view view synthesis methods and stereo synthesis methods.
Universal Morphology Control via Contextual Modulation
Feb 22, 2023



Learning a universal policy across different robot morphologies can significantly improve learning efficiency and generalization in continuous control. However, it poses a challenging multi-task reinforcement learning problem, as the optimal policy may be quite different across robots and critically depend on the morphology. Existing methods utilize graph neural networks or transformers to handle heterogeneous state and action spaces across different morphologies, but pay little attention to the dependency of a robot's control policy on its morphology context. In this paper, we propose a hierarchical architecture to better model this dependency via contextual modulation, which includes two key submodules: (1) Instead of enforcing hard parameter sharing across robots, we use hypernetworks to generate morphology-dependent control parameters; (2) We propose a morphology-dependent attention mechanism to modulate the interactions between different limbs in a robot. Experimental results show that our method not only improves learning performance on a diverse set of training robots, but also generalizes better to unseen morphologies in a zero-shot fashion.