 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWebGames: Challenging General-Purpose Web-Browsing AI Agents
Feb 25, 2025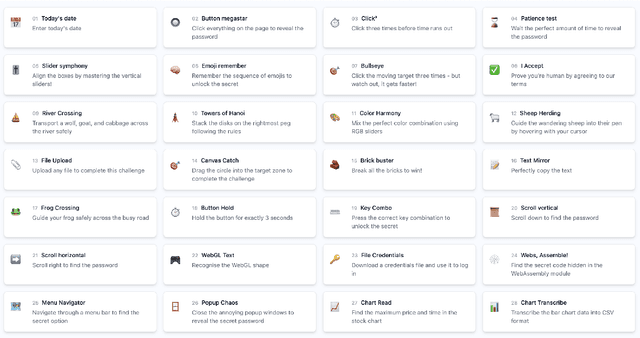


We introduce WebGames, a comprehensive benchmark suite designed to evaluate general-purpose web-browsing AI agents through a collection of 50+ interactive challenges. These challenges are specifically crafted to be straightforward for humans while systematically testing the limitations of current AI systems across fundamental browser interactions, advanced input processing, cognitive tasks, workflow automation, and interactive entertainment. Our framework eliminates external dependencies through a hermetic testing environment, ensuring reproducible evaluation with verifiable ground-truth solutions. We evaluate leading vision-language models including GPT-4o, Claude Computer-Use, Gemini-1.5-Pro, and Qwen2-VL against human performance. Results reveal a substantial capability gap, with the best AI system achieving only 43.1% success rate compared to human performance of 95.7%, highlighting fundamental limitations in current AI systems' ability to handle common web interaction patterns that humans find intuitive. The benchmark is publicly available at webgames.convergence.ai, offering a lightweight, client-side implementation that facilitates rapid evaluation cycles. Through its modular architecture and standardized challenge specifications, WebGames provides a robust foundation for measuring progress in development of more capable web-browsing agents.
LM2: Large Memory Models
Feb 09, 2025This paper introduces the Large Memory Model (LM2), a decoder-only Transformer architecture enhanced with an auxiliary memory module that aims to address the limitations of standard Transformers in multi-step reasoning, relational argumentation, and synthesizing information distributed over long contexts. The proposed LM2 incorporates a memory module that acts as a contextual representation repository, interacting with input tokens via cross attention and updating through gating mechanisms. To preserve the Transformers general-purpose capabilities, LM2 maintains the original information flow while integrating a complementary memory pathway. Experimental results on the BABILong benchmark demonstrate that the LM2model outperforms both the memory-augmented RMT model by 37.1% and the baseline Llama-3.2 model by 86.3% on average across tasks. LM2 exhibits exceptional capabilities in multi-hop inference, numerical reasoning, and large-context question-answering. On the MMLU dataset, it achieves a 5.0% improvement over a pre-trained vanilla model, demonstrating that its memory module does not degrade performance on general tasks. Further, in our analysis, we explore the memory interpretability, effectiveness of memory modules, and test-time behavior. Our findings emphasize the importance of explicit memory in enhancing Transformer architectures.
Lightweight Neural App Control
Oct 23, 2024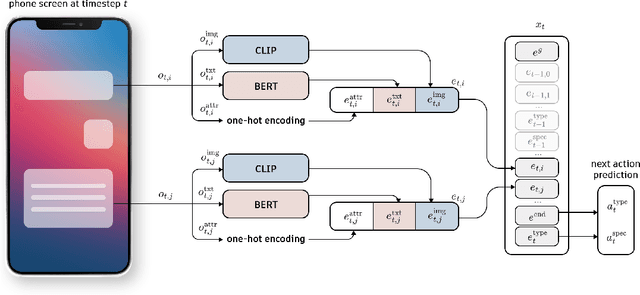
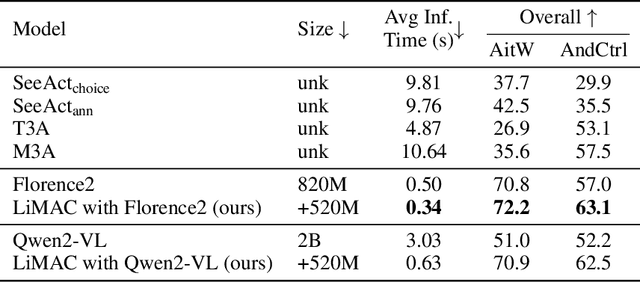
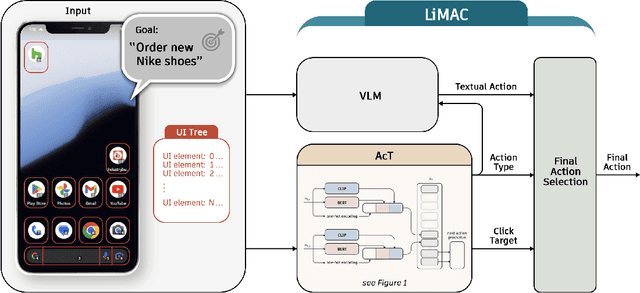
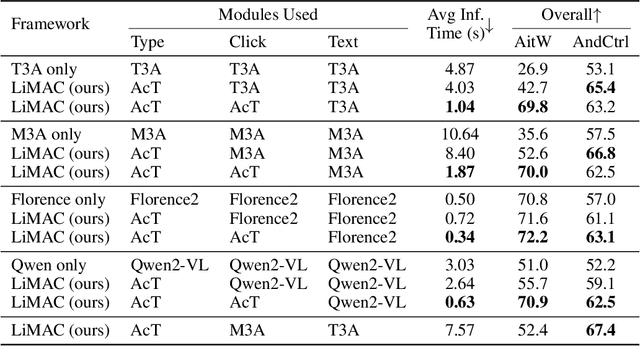
This paper introduces a novel mobile phone control architecture, termed ``app agents", for efficient interactions and controls across various Android apps. The proposed Lightweight Multi-modal App Control (LiMAC) takes as input a textual goal and a sequence of past mobile observations, such as screenshots and corresponding UI trees, to generate precise actions. To address the computational constraints inherent to smartphones, within LiMAC, we introduce a small Action Transformer (AcT) integrated with a fine-tuned vision-language model (VLM) for real-time decision-making and task execution. We evaluate LiMAC on two open-source mobile control datasets, demonstrating the superior performance of our small-form-factor approach against fine-tuned versions of open-source VLMs, such as Florence2 and Qwen2-VL. It also significantly outperforms prompt engineering baselines utilising closed-source foundation models like GPT-4o. More specifically, LiMAC increases the overall action accuracy by up to 19% compared to fine-tuned VLMs, and up to 42% compared to prompt-engineering baselines.
Pangu-Agent: A Fine-Tunable Generalist Agent with Structured Reasoning
Dec 22, 2023



A key method for creating Artificial Intelligence (AI) agents is Reinforcement Learning (RL). However, constructing a standalone RL policy that maps perception to action directly encounters severe problems, chief among them being its lack of generality across multiple tasks and the need for a large amount of training data. The leading cause is that it cannot effectively integrate prior information into the perception-action cycle when devising the policy. Large language models (LLMs) emerged as a fundamental way to incorporate cross-domain knowledge into AI agents but lack crucial learning and adaptation toward specific decision problems. This paper presents a general framework model for integrating and learning structured reasoning into AI agents' policies. Our methodology is motivated by the modularity found in the human brain. The framework utilises the construction of intrinsic and extrinsic functions to add previous understandings of reasoning structures. It also provides the adaptive ability to learn models inside every module or function, consistent with the modular structure of cognitive processes. We describe the framework in-depth and compare it with other AI pipelines and existing frameworks. The paper explores practical applications, covering experiments that show the effectiveness of our method. Our results indicate that AI agents perform and adapt far better when organised reasoning and prior knowledge are embedded. This opens the door to more resilient and general AI agent systems.
Ask more, know better: Reinforce-Learned Prompt Questions for Decision Making with Large Language Models
Oct 27, 2023Large language models (LLMs) demonstrate their promise in tackling complicated practical challenges by combining action-based policies with chain of thought (CoT) reasoning. Having high-quality prompts on hand, however, is vital to the framework's effectiveness. Currently, these prompts are handcrafted utilizing extensive human labor, resulting in CoT policies that frequently fail to generalize. Human intervention is also required in order to develop grounding functions that ensure low-level controllers appropriately process CoT reasoning. In this paper, we take the first step towards a fully integrated end-to-end framework for task-solving in real settings employing complicated reasoning. To that purpose, we offer a new leader-follower bilevel framework capable of learning to ask relevant questions (prompts) and subsequently undertaking reasoning to guide the learning of actions to be performed in an environment. A good prompt should make introspective revisions based on historical findings, leading the CoT to consider the anticipated goals. A prompt-generator policy has its own aim in our system, allowing it to adapt to the action policy and automatically root the CoT process towards outputs that lead to decisive, high-performing actions. Meanwhile, the action policy is learning how to use the CoT outputs to take specific actions. Our empirical data reveal that our system outperforms leading methods in agent learning benchmarks such as Overcooked and FourRoom.
Intrinsic Language-Guided Exploration for Complex Long-Horizon Robotic Manipulation Tasks
Sep 28, 2023Current reinforcement learning algorithms struggle in sparse and complex environments, most notably in long-horizon manipulation tasks entailing a plethora of different sequences. In this work, we propose the Intrinsically Guided Exploration from Large Language Models (IGE-LLMs) framework. By leveraging LLMs as an assistive intrinsic reward, IGE-LLMs guides the exploratory process in reinforcement learning to address intricate long-horizon with sparse rewards robotic manipulation tasks. We evaluate our framework and related intrinsic learning methods in an environment challenged with exploration, and a complex robotic manipulation task challenged by both exploration and long-horizons. Results show IGE-LLMs (i) exhibit notably higher performance over related intrinsic methods and the direct use of LLMs in decision-making, (ii) can be combined and complement existing learning methods highlighting its modularity, (iii) are fairly insensitive to different intrinsic scaling parameters, and (iv) maintain robustness against increased levels of uncertainty and horizons.
SMAClite: A Lightweight Environment for Multi-Agent Reinforcement Learning
May 09, 2023
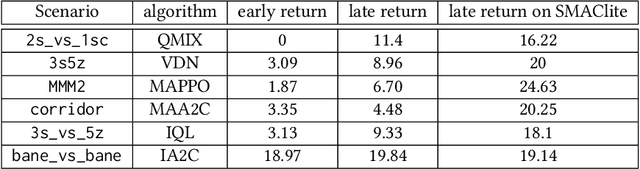

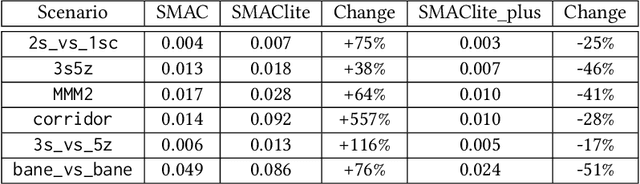
There is a lack of standard benchmarks for Multi-Agent Reinforcement Learning (MARL) algorithms. The Starcraft Multi-Agent Challenge (SMAC) has been widely used in MARL research, but is built on top of a heavy, closed-source computer game, StarCraft II. Thus, SMAC is computationally expensive and requires knowledge and the use of proprietary tools specific to the game for any meaningful alteration or contribution to the environment. We introduce SMAClite -- a challenge based on SMAC that is both decoupled from Starcraft II and open-source, along with a framework which makes it possible to create new content for SMAClite without any special knowledge. We conduct experiments to show that SMAClite is equivalent to SMAC, by training MARL algorithms on SMAClite and reproducing SMAC results. We then show that SMAClite outperforms SMAC in both runtime speed and memory.
Revisiting the Gumbel-Softmax in MADDPG
Feb 23, 2023MADDPG is an algorithm in multi-agent reinforcement learning (MARL) that extends the popular single-agent method, DDPG, to multi-agent scenarios. Importantly, DDPG is an algorithm designed for continuous action spaces, where the gradient of the state-action value function exists. For this algorithm to work in discrete action spaces, discrete gradient estimation must be performed. For MADDPG, the Gumbel-Softmax (GS) estimator is used -- a reparameterisation which relaxes a discrete distribution into a similar continuous one. This method, however, is statistically biased, and a recent MARL benchmarking paper suggests that this bias makes MADDPG perform poorly in grid-world situations, where the action space is discrete. Fortunately, many alternatives to the GS exist, boasting a wide range of properties. This paper explores several of these alternatives and integrates them into MADDPG for discrete grid-world scenarios. The corresponding impact on various performance metrics is then measured and analysed. It is found that one of the proposed estimators performs significantly better than the original GS in several tasks, achieving up to 55% higher returns, along with faster convergence.
Planning with Occluded Traffic Agents using Bi-Level Variational Occlusion Models
Oct 26, 2022Reasoning with occluded traffic agents is a significant open challenge for planning for autonomous vehicles. Recent deep learning models have shown impressive results for predicting occluded agents based on the behaviour of nearby visible agents; however, as we show in experiments, these models are difficult to integrate into downstream planning. To this end, we propose Bi-level Variational Occlusion Models (BiVO), a two-step generative model that first predicts likely locations of occluded agents, and then generates likely trajectories for the occluded agents. In contrast to existing methods, BiVO outputs a trajectory distribution which can then be sampled from and integrated into standard downstream planning. We evaluate the method in closed-loop replay simulation using the real-world nuScenes dataset. Our results suggest that BiVO can successfully learn to predict occluded agent trajectories, and these predictions lead to better subsequent motion plans in critical scenarios.
Pareto Actor-Critic for Equilibrium Selection in Multi-Agent Reinforcement Learning
Sep 28, 2022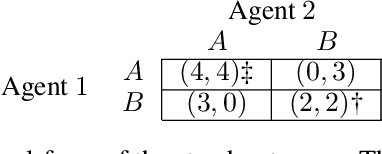
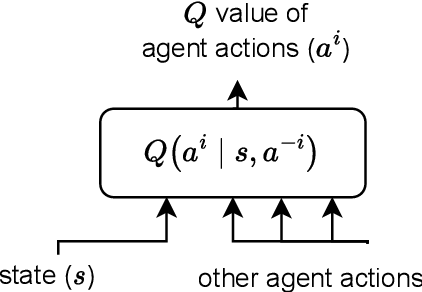
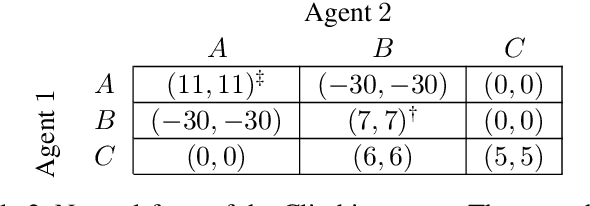
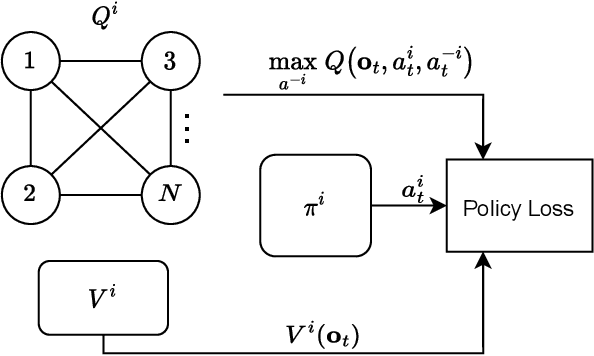
Equilibrium selection in multi-agent games refers to the problem of selecting a Pareto-optimal equilibrium. It has been shown that many state-of-the-art multi-agent reinforcement learning (MARL) algorithms are prone to converging to Pareto-dominated equilibria due to the uncertainty each agent has about the policy of the other agents during training. To address suboptimal equilibrium selection, we propose Pareto-AC (PAC), an actor-critic algorithm that utilises a simple principle of no-conflict games (a superset of cooperative games with identical rewards): each agent can assume the others will choose actions that will lead to a Pareto-optimal equilibrium. We evaluate PAC in a diverse set of multi-agent games and show that it converges to higher episodic returns compared to alternative MARL algorithms, as well as successfully converging to a Pareto-optimal equilibrium in a range of matrix games. Finally, we propose a graph neural network extension which is shown to efficiently scale in games with up to 15 agents.